China wins the open model race and the price to pay goes beyond economics
For the first time in 2025, Chinese developers are seeing higher download numbers for open AI models than US providers.
The "Economies of Open Intelligence" report (preprint), which pulls data from the Hugging Face platform, shows that over 44 percent of downloads for popular new models now come from China. Alibaba's Qwen family and Deepseek are racking up massive numbers, leaving US competitors like Meta and Google behind.

US dominance collapsed in just a few years
The shift happened remarkably fast. By the end of 2022, Google, Meta, and OpenAI together controlled up to 60 percent of all downloads on Hugging Face, the go-to platform for open AI models. The US alone held over 60 percent market share. Models like BERT and CLIP defined the field—all homegrown American developments.
Then Stable Diffusion changed everything. When the image generator dropped in late 2022, it opened the floodgates. Suddenly small teams and solo developers could build and tweak their own models. The US share started slipping as international groups and community projects picked up steam.
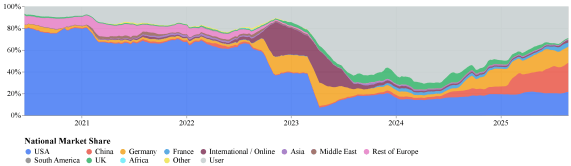
That trend hit a turning point in 2025 when China passed the US for the first time. Deepseek and Qwen alone grabbed 14 percent of downloads during the period. Alibaba's Qwen models were downloaded over 750 million times last year. Compare that to Meta's Llama models, which dominated in 2024 but managed only 500 million downloads.
Beyond the big names, an entirely new layer of developers has emerged. Groups like LM Studio, comfy, and mlx-community don't build AI models from scratch. Instead, they take existing models and make them work for non-developers. They compress massive files, tweak models for specific use cases, and wrap them in user-friendly software. These middlemen now account for more than 22 percent of downloads, outpacing some major companies.
Models are getting bigger and smarter, but also more opaque
The models themselves have come a long way. Parameter counts and file sizes have ballooned alongside capabilities, jumping from 827 million parameters in 2023 to 20 billion this year. Many models now handle images, video, and speech instead of just text. Video AIs like ByteDance's AnimateDiff-Lightning and tools from Stable Diffusion rank among the most popular downloads.
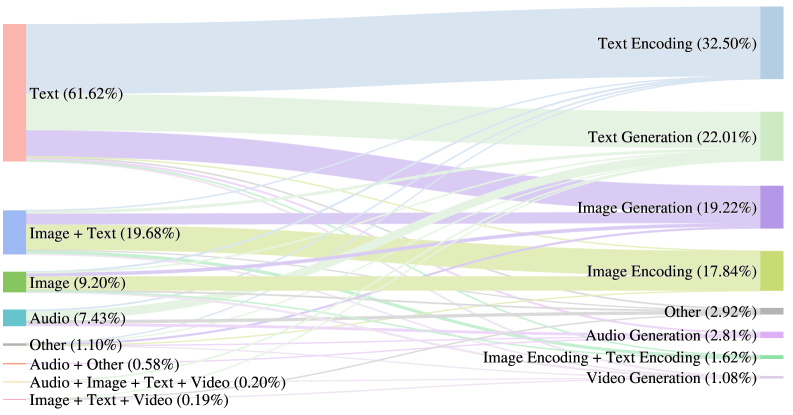
But there's a flip side to all this progress: transparency is tanking. In 2022, nearly 80 percent of popular models disclosed their training data. By 2025, that number dropped to just 39 percent. More models than ever are free to download, but nobody knows what's actually in them. True open source—where training data is fully traceable—is becoming rare. Instead, more models ship with usage restrictions and license terms users have to accept upfront.
Chinese dominance brings political baggage
The rise of Chinese AI models also raises political red flags. A recent study by US media watchdog NewsGuard found that many Chinese LLMs repeat or fail to correct pro-Chinese false claims 60 percent of the time.
Since these models generate content based on their training data, they inevitably spread whatever narratives and values are baked in. Anyone running Chinese models is automatically pulling Chinese propaganda into their own AI systems.
The same goes for any imported media, of course. But generative AI is different. Traditional propaganda takes effort. Someone has to deliberately craft and place it, even when using AI tools.
But AI models are more like sand. Once in the system, they get into everything.
Developers building chatbots, writers drafting emails, and companies automating customer service—none of them intend to spread propaganda. When they build on these models, the embedded narratives seep into every crack of their work without anyone noticing.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.