Chinese researchers diagnose AI image models with aphasia-like disorder, develop self-healing framework

Chinese researchers have developed UniCorn, a framework designed to teach multimodal AI models to recognize and fix their own weaknesses.
Some multimodal models can now both understand and generate images, but there's often a surprising gap between these two abilities. A model might correctly identify that a beach is on the left and waves are on the right in an image but then generate its own image with the arrangement flipped.
Researchers from the University of Science and Technology of China (USTC) and other Chinese universities call this phenomenon "Conduction Aphasia" in their study, a reference to a neurological disorder where patients understand language but can't reproduce it correctly. UniCorn is their framework for bridging this gap.
One model plays three roles at once
The core idea behind UniCorn is simple: if a model can evaluate images better than it generates them, that evaluation ability should be able to improve generation. The researchers split a single multimodal model into three collaborating roles that operate within the same parameter space.
The "Proposer" first generates diverse and challenging text descriptions. The "Solver" then creates multiple image candidates for each prompt, specifically eight different variants with varying parameters. Finally, the "Judge" rates the generated images on a scale of 0 to 10 and provides detailed reasoning.
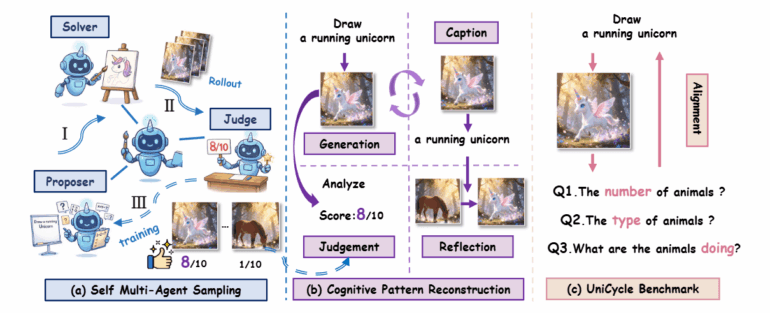
The actual training happens in the second phase. The collected interactions get converted into four different training formats: the model learns to generate good images from prompts, but also to describe its own images. It additionally trains on evaluating image-text pairs and transforming poor results into better ones. The researchers emphasize that all three components are necessary - training only on generation data causes the model's understanding capabilities to collapse.
Fine-tuning takes about seven hours on eight Nvidia H800 GPUs, according to the researchers, which is relatively little for the improvements achieved. The entire process works without external datasets or stronger teacher models.
New benchmark tests cycle consistency
To measure whether the improvements reflect genuine multimodal intelligence or just task-specific optimizations, the researchers developed the UniCycle benchmark. It tests whether a model can reconstruct key information from its own generated images.
The process follows a text-to-image-to-text loop: the model first generates an image from a text description, then answers questions about that image. An external model then checks whether the answers match the original description. This reveals whether the model truly understands what it generated.
Significant gains on complex tasks
In experiments, the researchers used BAGEL as the base model and tested UniCorn across six different benchmarks. Results show consistent improvements over the base model. It's no Nano Banana Pro, but the clear performance jump shows the method works.
The gains are particularly strong on tasks requiring structured understanding. The model improves significantly on object counting and spatial 3D arrangements. UniCorn also shows clear progress on knowledge-intensive tasks requiring cultural or scientific background knowledge.
On the DPG benchmark, which tests the ability to generate complex scenes with multiple objects and their attributes, UniCorn even beats GPT-4o. On the new UniCycle benchmark, the framework scores almost ten points higher than the base model - a sign that the improvements aren't just superficial but actually strengthen coherence between understanding and generation, according to the team.

External teacher model provides little benefit
The researchers also tested whether a stronger external model as Judge would deliver better results. They used Qwen3-VL-235B, a significantly larger model. The performance barely improved, and on the UniCycle benchmark it actually dropped.
The researchers suspect the model struggles to adopt the more complex evaluation patterns of a stronger teacher. Self-play with the model's own judgments proves more effective than external supervision, at least in this experiment.
Negation and counting remain weak spots
The researchers acknowledge that UniCorn hits limits on certain tasks. It shows no significant improvements on negations, e.g. instructions like "a bed without a cat" and precise object counting. These task types are fundamentally difficult for multimodal models, and the self-play approach can't provide effective supervision here.
The model also only goes through the improvement process once: it collects data, trains on it - and that's it. An iterative approach where the improved model collects new data and optimizes further hasn't been implemented yet. The researchers plan this for future work to develop understanding and generation together.
Another limitation concerns understanding capabilities: while image generation improves significantly, scores on pure understanding benchmarks remain largely stable. UniCorn primarily improves one side of the equation. However, understanding capabilities don't collapse either, which would happen with pure generation training without the additional data formats, the team reports.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.