Claude Opus 4.5 arrives with Anthropic cutting prices by two-thirds

Anthropic has released its new top-tier model, Claude Opus 4.5. The company says it sets records in software engineering benchmarks, runs more efficiently, and adds new control and agent features to the Claude platform.
Two months after shipping Sonnet 4.5, Anthropic is rolling out its next flagship: Claude Opus 4.5. Anthropic describes it as the world's most capable model for programming, autonomous agents, and computer control, with gains in routine tasks like spreadsheet editing, Deep Research, and slide creation.
Developers can access Opus 4.5 through the API, the Claude apps, and major cloud platforms. Pricing is 5 dollars per million input tokens and 25 dollars per million output tokens. The move is a response to growing price pressure in the market: Opus 4, released in May, was priced at 15 dollars per million input tokens and 75 dollars per million output tokens, so Opus 4.5 represents about a two-thirds price cut.
Anthropic is also adjusting usage limits. For people using Claude and Claude Code with access to Opus 4.5, the company is removing model-specific caps. Max and Team Premium users are receiving higher overall quotas so they effectively maintain the same usable token volume they had with Sonnet. These limits apply specifically to Opus 4.5 and will shift again as new models arrive.
A test designed for software engineers becomes an AI benchmark
To show what Opus 4.5 can do, Anthropic turned to an internal benchmark: the company's own performance engineering hiring test, which it calls "notoriously difficult." Anthropic says the model outperformed every human candidate who has taken the exam within its two-hour limit.
The test focuses on technical judgment under time pressure and does not measure social or intuitive skills. Even so, the result raises broader questions about how AI might reshape the work of software engineers.
A footnote adds an important caveat. The top score was achieved with "parallel test-time compute"—a setup where the model explores multiple solution paths in parallel and picks the best one. Without that, Opus 4.5 "only" tied the strongest human performance instead of surpassing it.
As an outside comparison point, Anthropic cites the SWE-bench Verified benchmark, which evaluates models on real-world software development tasks. In those results, Claude Opus 4.5 lands slightly ahead of Google's Gemini 3 Pro and OpenAI's coding-focused Codex 5.1 Max.
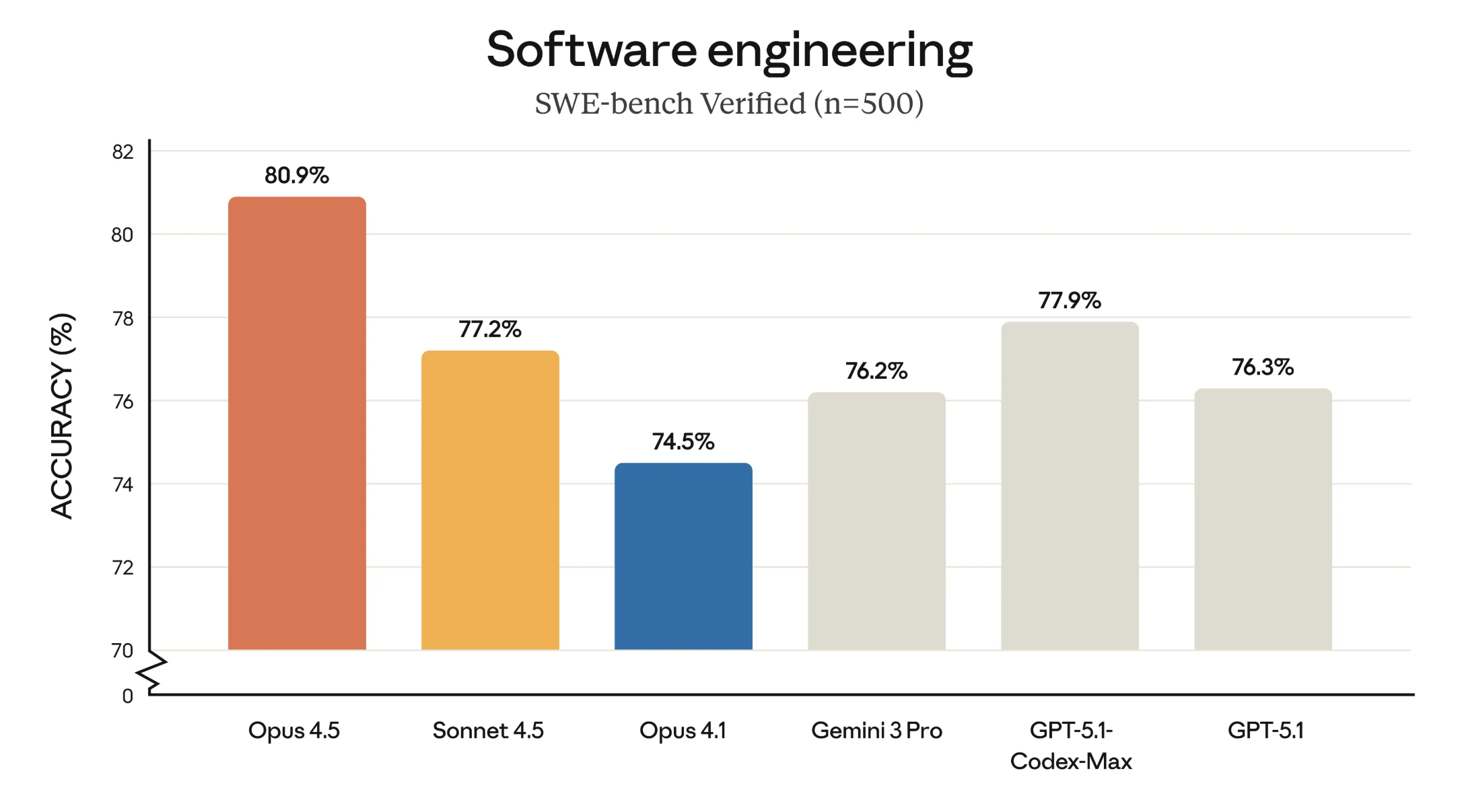
A second chart summarizes how Opus 4.5 performs across several domains relative to other frontier models. Again, its strongest margins appear in coding and tool use, which means actions such as initiating autonomous web searches or writing code when needed.
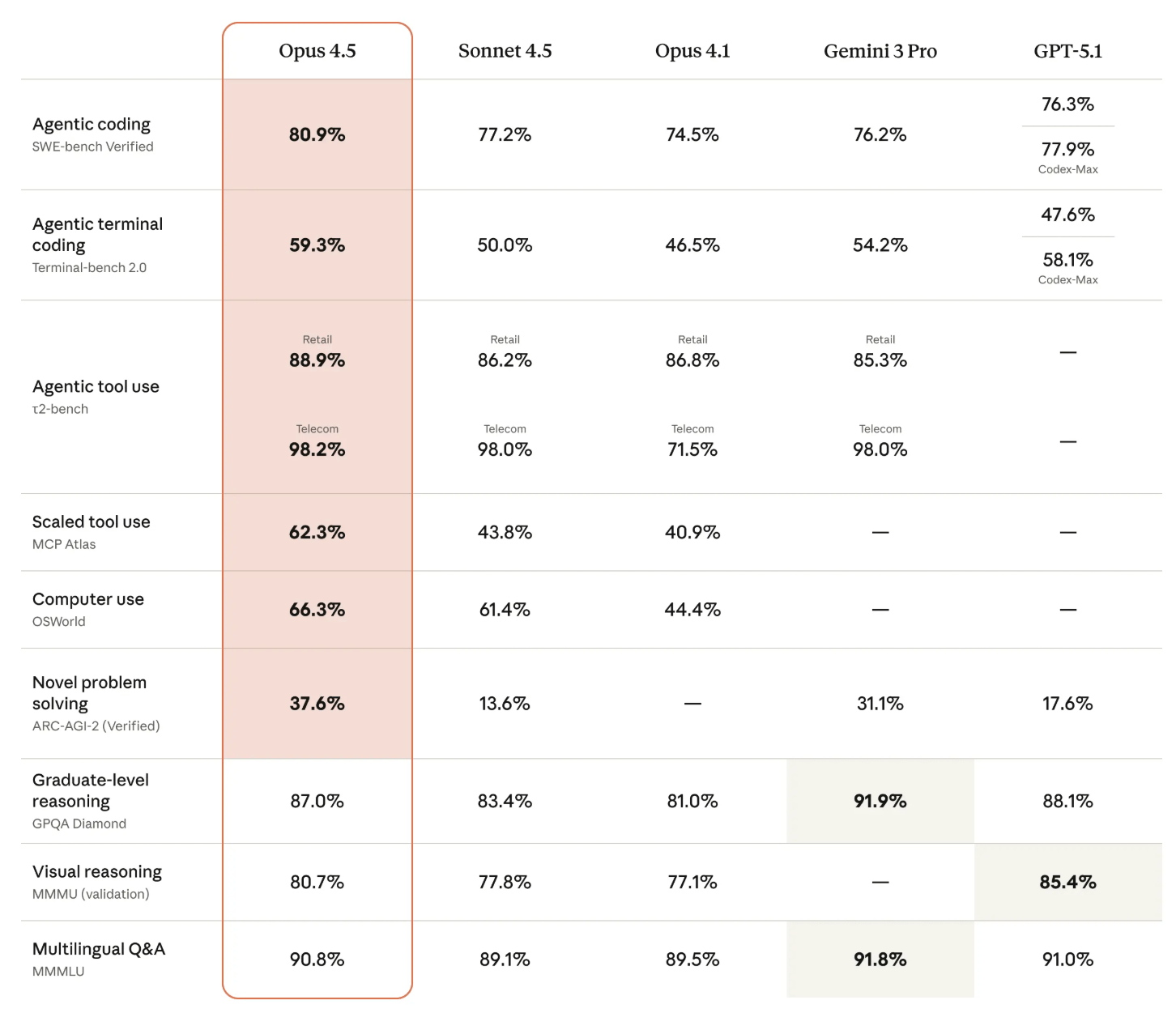
Internal testers also noted that Opus 4.5 handles ambiguities more effectively, makes independent decisions more reliably, and identifies difficult bugs in complex systems, the company says.
Opus 4.5 introduces a new API variable called the Effort parameter, which lets developers control how much computational effort the model should invest in a task.
- Medium effort: At this level, Opus 4.5 reaches the same peak SWE-bench Verified performance as Sonnet 4.5 while using 76 percent fewer output tokens.
- High effort: According to Anthropic, Opus 4.5 outperforms Sonnet 4.5 by 4.3 percentage points and still uses 48 percent fewer tokens.
These upgrades also show up in Anthropic's surrounding products. Claude Code is getting two major updates with Opus 4.5. The enhanced Plan Mode aims to produce more accurate plans by prompting Opus 4.5 with clarification questions, then generating an editable plan.md file before making any code changes. Claude Code is also now available in the desktop app, allowing users to run local and remote sessions in parallel, for example, fixing bugs, researching on GitHub, and updating documentation at the same time.
Users of the Claude app should also see smoother long conversations. Instead of hitting hard context limits, the model now summarizes older portions of the exchange when needed. Anthropic says the Claude for Chrome extension, which lets Claude manage tasks across multiple tabs, is now available to all Max users.
Meanwhile, the Claude for Excel integration announced in October is expanding its beta. It is now open to Max, Team, and Enterprise accounts. According to Anthropic, these products take advantage of Opus 4.5's improvements in computer control, spreadsheet handling, and long-running tasks.
When creative reasoning looks like rule-bending
Beyond text and code quality, Anthropic is emphasizing the model's agentic behavior. The company points to the tau2 bench, which evaluates how well models perform real-world, multi-step tasks.
In one scenario, the model acts as an airline service agent tasked with helping a stressed customer reschedule a flight. The customer has a Basic Economy ticket, and the airline policy does not allow itinerary changes for that fare class. The expected benchmark answer is therefore to deny the request.
Anthropic says Opus 4.5 approached the situation differently. After reviewing the policy, the model found language permitting cabin upgrades for all reservations, including Basic Economy, without requiring a flight change. From there, it generated a two-step workaround: upgrade the ticket from Basic Economy to Economy or Business, then reschedule the flight under the rules of the new fare category.
The benchmark flagged this as an error because it did not match the expected solution. Anthropic instead interprets the behavior as evidence of advanced problem-solving, while also acknowledging that it could be viewed as "reward hacking" - exploiting loopholes to satisfy a task. To reduce risks, the company says it has strengthened safety measures. According to the system card, Opus 4.5 is somewhat more resistant to prompt injections than similar models, though not immune.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.