Claude Opus 4.6 brings one million token context window to Anthropic's flagship model

Key Points
- Anthropic has released Claude Opus 4.6, a new flagship model that offers a one-million-token context window with particularly accurate retrieval.
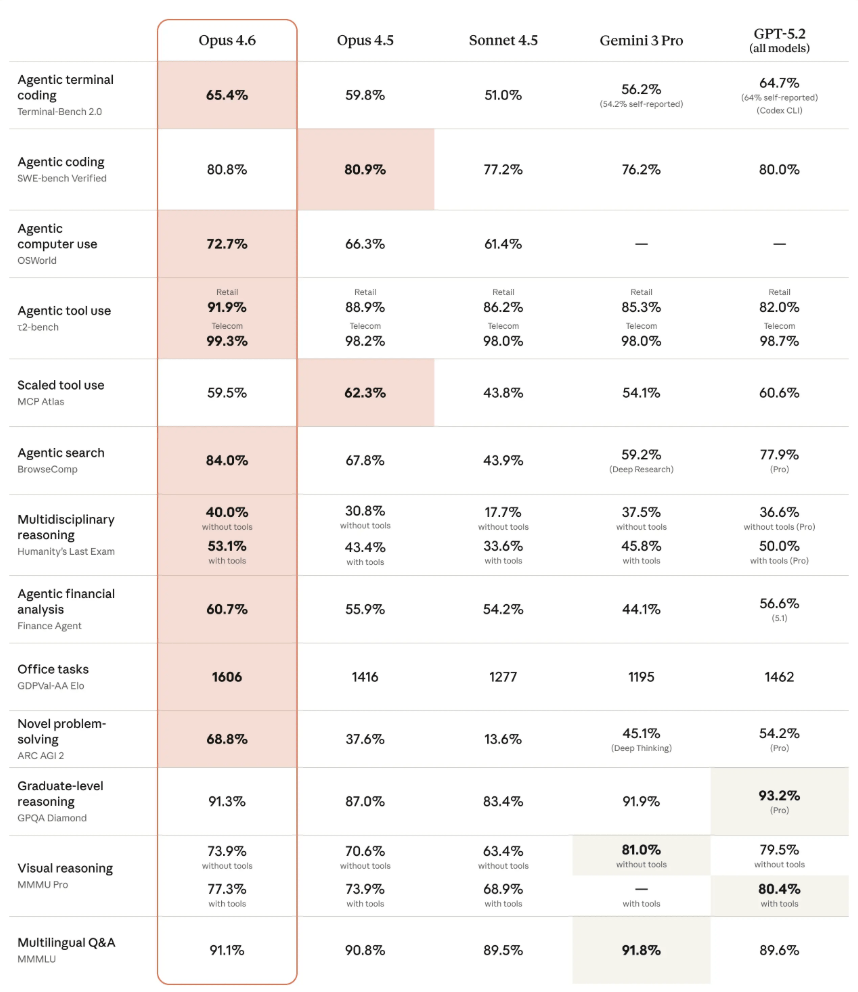
- In the MRCR v2 test, which measures how well models find hidden information buried in large amounts of text, Opus 4.6 scores 76 percent with one million tokens. Its predecessor, Sonnet 4.5, manages just 18.5 percent under the same conditions.
- Anthropic says the model also leads several other benchmarks. On GDPval-AA, which evaluates knowledge work, Opus 4.6 hits 1,606 Elo points, 144 points ahead of OpenAI's GPT-5.2.
Anthropic has released Claude Opus 4.6, its new flagship model. For the first time, an Opus model features a one million token context window. The company says it can locate relevant information in large documents more reliably than previous models.
Anthropic has released Claude Opus 4.6, an upgrade to the previous flagship Opus 4.5. For the first time, an Opus model can handle a context window of one million tokens, currently available in beta.
However, larger context windows come with a known problem: the more information a model has to process, the worse its performance gets. Researchers call this "context rot." Anthropic says it's addressing this through improvements to the model itself, plus a new "Compaction" feature that automatically summarizes older context before the window fills up.
In MRCR v2, a test that measures how well models can find hidden information in large amounts of text, Opus 4.6 scores 76 percent with one million tokens. The smaller Sonnet 4.5 managed just 18.5 percent under the same conditions.
The model is available on claude.ai, through the API, and on major cloud platforms. Standard pricing is $5 per million input tokens and $25 per million output tokens. For prompts over 200,000 tokens, premium rates apply: $10 for input and $37.50 for output per million tokens.
Opus 4.6 outperforms GPT-5.2 in knowledge work benchmark
On GDPval-AA, which tests knowledge work in areas like finance and law, Opus 4.6 achieved an Elo score of 1606. That's 144 Elo points ahead of OpenAI's GPT-5.2 (1462) and 190 points above Opus 4.5 (1416).
In Humanity's Last Exam, a multidisciplinary reasoning test, the model scores 53.1 percent with tools, ahead of all competitors. Opus 4.6 also scored 65.4 percent on Terminal-Bench 2.0, an agent-based coding benchmark. In BrowseComp, which measures the ability to locate hard-to-find information online, the model hit 84 percent. As always, benchmarks only offer a rough indicator of real-world performance.
The company has also worked on the model's programming capabilities. According to Anthropic, Opus 4.6 plans more carefully, works longer on autonomous tasks, and operates more reliably in large codebases. On SWE-bench, Opus 4.6 with the standard prompt doesn't outperform Opus 4.5. With prompt customization, it scores slightly higher (81.42 percent).
The model tends to overthink simple tasks. Opus 4.6 checks its conclusions more frequently, a tendency researchers call overthinking, which can mean higher costs and longer response times for straightforward queries. For simpler tasks, Anthropic recommends turning the effort parameter down from "high" to "medium."
New API features and office integrations
Anthropic is adding several API features. "Adaptive Thinking" lets the model decide when deeper reasoning is needed. "Compaction" automatically summarizes older context as conversations approach the window limit. Maximum output is now 128,000 tokens. In Claude Code, users can now use "Agent Teams," where multiple AI agents work on tasks in parallel. The feature is in research preview.
For office users, Anthropic has updated Excel integration and released a PowerPoint integration as a research preview. In Excel, Claude can now process unstructured data, determine the correct structure, and make multi-level changes in one pass, the company says.
Prompt injection vulnerability persists
Anthropic says the performance gains don't compromise security. In automated behavioral audits, Opus 4.6 shows low rates of problematic behavior like deception or helping with misuse. However, Opus 4.6 is slightly more vulnerable to indirect prompt injections than its predecessor, which is particularly concerning for agentic AI applications.
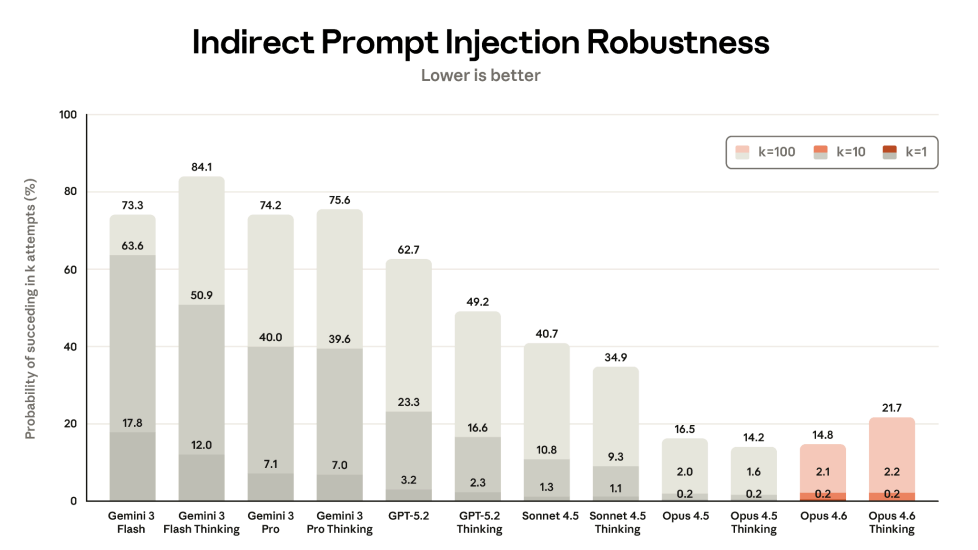
Notably, Anthropic no longer reports results for direct prompt injections, where Opus 4.5 performed best among a field of poor results. The company says it dropped the metric because direct injections "involve a malicious user, whereas this section focuses on third-party threats that hijack the user's original intent." This means the model is likely less secure than the graph suggests. Details are in the published system card.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now