Current language model training leaves large parts of the internet on the table

Large language models learn from web data, but which pages actually end up in training sets depends heavily on the HTML extractor used. Researchers at Apple, Stanford, and the University of Washington show that three common tools extract surprisingly different parts of the web.
Large language models pick up language, facts, and skills primarily from text scraped from the internet. Common Crawl, a freely available web archive, forms the backbone of most training datasets.
Before raw data can be fed into a model, the actual text has to be pulled from each page's HTML code. Navigation bars, hidden elements, and visual styling all get stripped out.
This step sounds trivial, but a new study by researchers at Apple, Stanford University, and the University of Washington reveals it's a significantly underestimated factor for training data quality and scope.
Several extraction tools exist—the speed-optimized Resiliparse, the balanced Trafilatura, and the stopword-based JusText—but each major dataset project picks exactly one and applies it across all web pages. Since models trained with any of these tools scored similarly on standard benchmarks, the choice was previously considered more or less arbitrary.
Combining extractors boosts token yield by up to 71 percent
The study challenges that assumption. The researchers ran the same filter pipeline on all three extractors' output and compared which websites made it through. Only 39 percent of pages were captured by more than one extractor. The remaining 61 percent showed up in the output of just a single tool. Each extractor systematically surfaces different parts of the web; relying on only one means leaving a large chunk of available data behind.
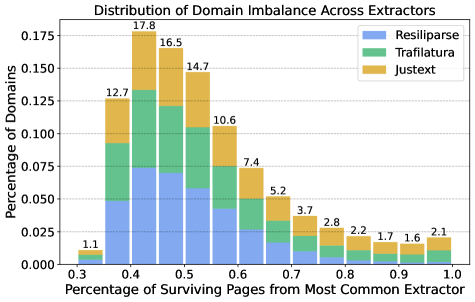
Token yield jumps by up to 71 percent when using the union of all three extractors, while benchmark performance stays the same. Even after further deduplication, 58 percent more tokens remained. The dataset for 7B models grew from 193 billion tokens (Resiliparse only) to 283 billion.
The combined approach also beat simply loosening the filter thresholds of a single extractor: strict filters across multiple tools delivered higher-quality pages than generous thresholds for just one. The advantage was especially clear in simulations of data-scarce scenarios modeling the increasing depletion of available internet data.
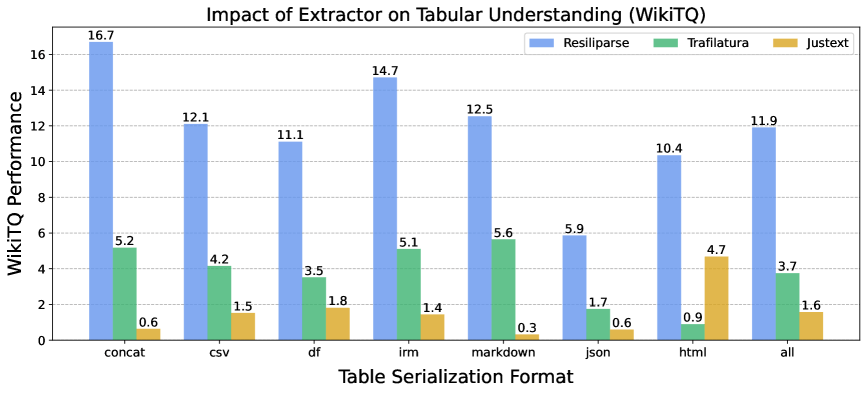
Tables and code can vanish entirely depending on the extractor
For general language tasks, the three extractors appear largely interchangeable. For structured content like tables and code blocks, the differences are dramatic: JusText often strips tables and code out completely. Trafilatura tries converting tables to Markdown but loses cell content along the way. Resiliparse preserves content most reliably.
On the WikiTableQuestions benchmark, a 7B model trained with Resiliparse scored 11.9 points. Trafilatura managed 3.7, and JusText just 1.6. Resiliparse closed 73 percent of the gap between DCLM-7B-8k and Llama-3-8B in table comprehension, even though both models performed comparably on general benchmarks.
JusText also fell behind on the HumanEval code benchmark by up to 3.6 percentage points because it frequently strips out code blocks. Trafilatura destroys the whitespace formatting that's critical for programming languages.
A small processing step with outsized consequences
The researchers say their goal isn't to build new extractors but to show that existing tools perform significantly better when used in parallel and selected based on content type. Approaches that could open up even more of the web weren't tested. The study also flags a risk: more effective extraction could expose models to more harmful or copyrighted content.
The internet data powering today's language models is a finite resource. The fact that such an early processing step determines how much of it actually gets used should push dataset developers to rethink their pipelines.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.