
Sensitive data and racist expressions have surfaced in the analysis of training texts of the open-source language model Bloom. A dataset search tool shows this and should improve the transparency of future models.
"Why do LMs say what they say? We often don't know - but now we might get a better idea." With these words, NLP researcher Aleksandra "Ola" Piktus announces her latest project on Twitter.
Together with Hugging Face, the researcher has released the "Roots" search app for the open-source Bloom model, which can be used to search the underlying database of 176 billion parameters in 59 languages.
Bloom was launched in July 2022 and is an open source alternative to OpenAI's GPT-3, especially because it is freely available and multilingual.
Tool aims to raise bar "for next generation" language model
The ability to browse training material without programming knowledge is necessary to develop a common understanding of general problems and raise the bar for next-generation language models, Piktus says.
Using the Roots search engine, she found sensitive private data, language contamination, and fake news. A woman had previously used a similar search engine for AI training images to find private medical photos of herself in the dataset.
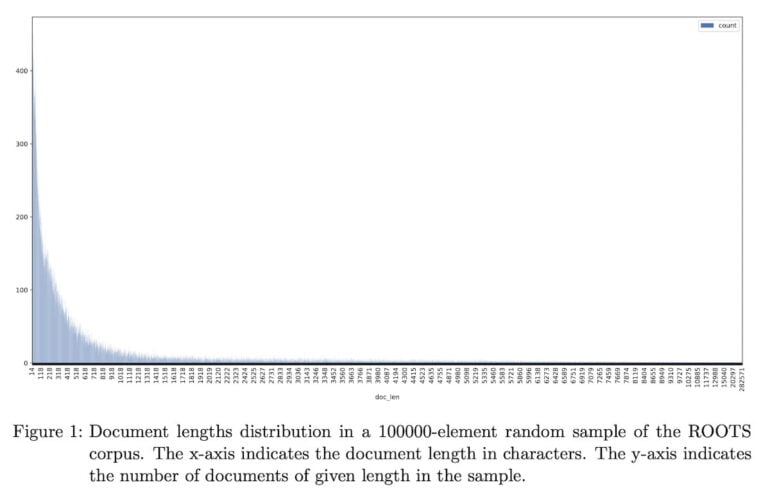
Roots searches 1.6 TB of text data in 46 natural and 13 programming languages. Piktus' analysis shows: individual data points vary drastically in length. To compare and rank them, she divided them into equal-sized passages of 128 words and assigned each a unique ID.
Sensitive data is blacked out instead of removed
The OSCAR dataset came to Piktus' attention as a source of particularly large amounts of personal data. To prevent this from becoming public through the search engine, a script is applied that blackens the results. "This way one can inspect the data and observe the problem, but personal information are predominantly removed," the accompanying paper states.

Racism and hate speech can come from movie subtitles
The researchers involved also observed evidence of "low-quality text," such as racial slurs, sexually explicit language, or hate speech, some of which came from records with movie subtitles.
While humans can contextualize this form of language, which is usually used consciously, a language model adopts it without classification, the researchers say.
The current version of the tool is heavily influenced by the user interface of popular search engines. In the future, the researchers plan to display more quantitative information, such as the frequency of certain terms, the number of hits or co-occurrence statistics.





