Deepseek slashes API prices by up to 75 percent with its latest V3.2 model
Deepseek has rolled out its experimental language model, Deepseek-V3.2-Exp, building on the recent V3.1-Terminus release.
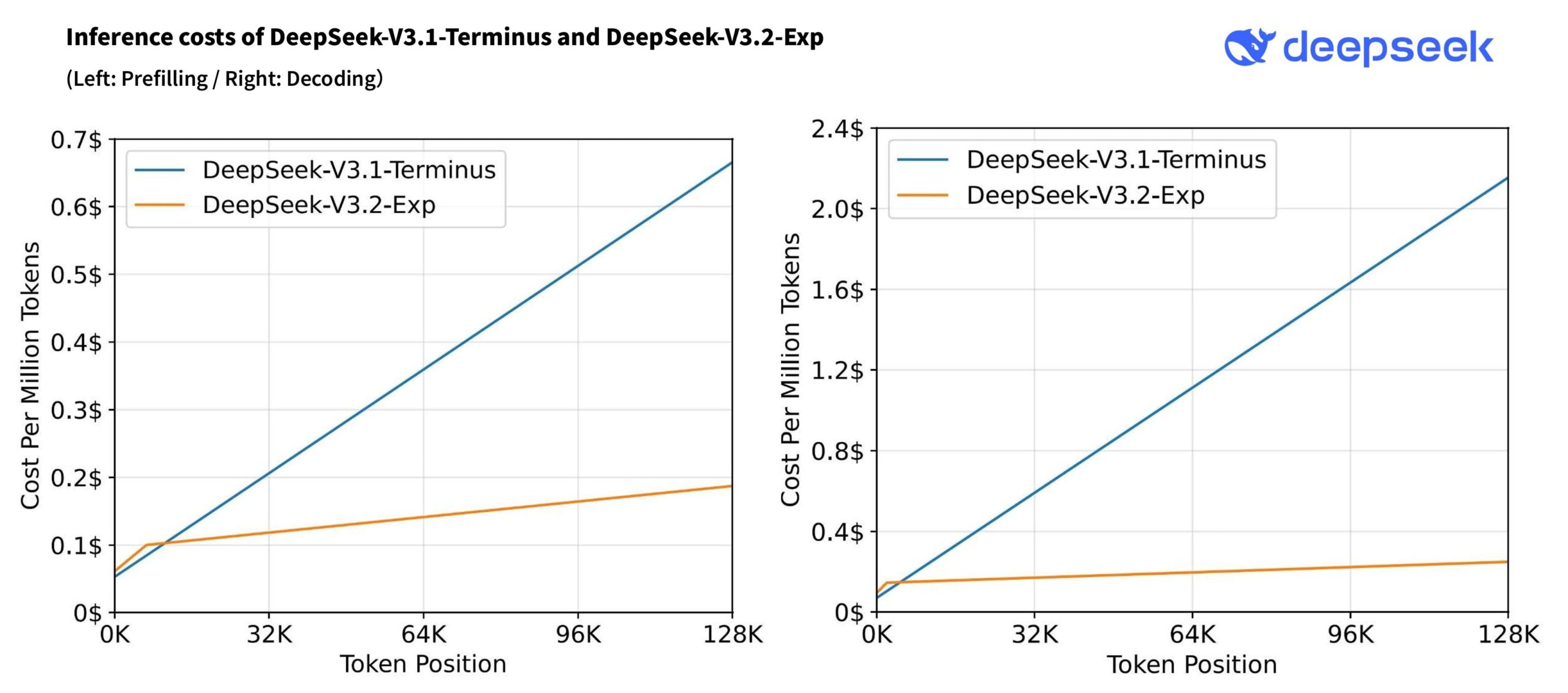
At the heart of the upgrade is DeepSeek Sparse Attention (DSA), which selectively focuses on relevant parts of the input. This change dramatically cuts inference costs for large inputs, handling up to 128,000 tokens. According to Deepseek's technical report, costs at the 128K token level are about 3.5 times lower for prefilling and 6 to 7 times lower for decoding.
The new release also features TileLang, a high-level programming framework that runs on multiple hardware platforms. This means V3.2-Exp can run on AI chips from Chinese vendors like Huawei Ascend and Cambricon out of the box. Deepseek appears to be positioning itself for a future where China reduces its reliance on US chipmakers like Nvidia.
Similar performance, steep price cuts
In benchmarks, Deepseek-V3.2-Exp performs about the same as V3.1-Terminus, with only minor differences. Deepseek notes small gains or losses on individual tasks, mostly due to shorter responses in complex reasoning tests. These gaps disappear in tests with similar token counts.
| Benchmark | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp |
|---|---|---|
| Reasoning Mode w/o Tool Use | ||
| MMLU-Pro | 85.0 | 85.0 |
| GPQA-Diamond | 80.7 | 79.9 |
| Humanity's Last Exam | 21.7 | 19.8 |
| LiveCodeBench | 74.9 | 74.1 |
| AIME 2025 | 88.4 | 89.3 |
| HMMT 2025 | 86.1 | 83.6 |
| Codeforces | 2046 | 2121 |
| Aider-Polyglot | 76.1 | 74.5 |
| Agentic Tool Use | ||
| BrowseComp | 38.5 | 40.1 |
| BrowseComp_zh | 45.0 | 47.9 |
| SimpleQA | 96.8 | 97.1 |
| SWE Verified | 68.4 | 67.8 |
| SWE-bench Multilingual | 57.8 | 57.9 |
| Terminal-bench | 36.7 | 37.7 |
Despite similar performance, the new model is much cheaper to run. Deepseek has cut API prices by 50 to 75 percent. This could put added pressure on Western providers like Anthropic, who charge more for comparable models. However, ongoing skepticism about Chinese AI models may limit the impact for now.
| New price | Old price | Reduction | |
|---|---|---|---|
| Input (cache hit) | 0.028 US dollars / 1 million tokens | 0.07 US dollars / 1 million tokens | -60% |
| Input (cache miss) | 0.28 US dollars / 1 million tokens | 0.56 US dollars / 1 million tokens | -50% |
| Output (cache miss) | 0.42 US dollars / 1 million tokens | 1.68 US dollars / 1 million tokens | -75% |
Deepseek-V3.2-Exp is available through the web interface, iOS and Android apps, the API, and as downloadable checkpoints on Hugging Face, with V3.1-Terminus remaining accessible for comparison testing until October 15, 2025.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.