DeepSeek-V2 is a Chinese flagship open source Mixture-of-Experts model
Chinese AI startup DeepSeek recently released DeepSeek-V2, a large Mixture-of-Experts (MoE) language model that aims to achieve an optimal balance between high performance, lower training cost, and efficient inference.
The open-source model boasts 236 billion parameters and supports a context length of 128,000 tokens. Compared to its predecessor, DeepSeek 67B, DeepSeek-V2 saves 42.5 percent in training costs, reduces the key-value cache by 93.3 percent, and increases the maximum generation throughput by 5.76 times.
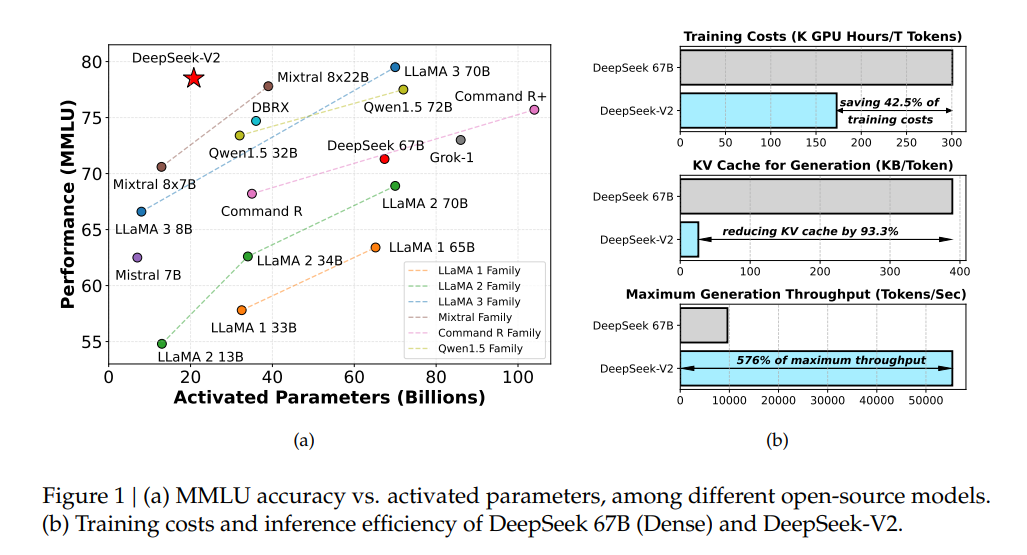
It is based on the proven Transformer architecture, but with significant innovations in the attention module and feed-forward network. The model uses two key techniques: Multi-Head Latent Attention (MLA) and the DeepSeekMoE architecture.
MLA compresses keys and values together to reduce memory and increase processing speed by storing essential information in a more compact format. The DeepSeekMoE architecture specializes individual experts and avoids redundancy by breaking complex tasks into smaller subtasks that are handled by specialized experts rather than a single large model.
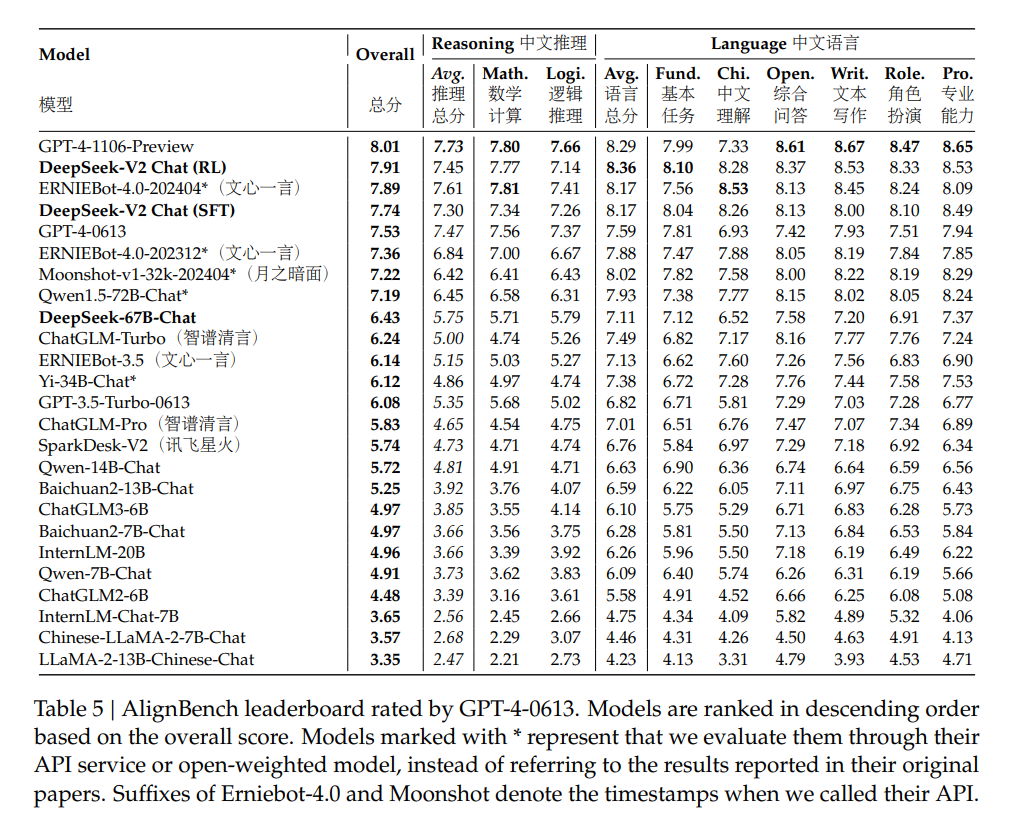
The researchers trained DeepSeek-V2 on a massive corpus of 8.1 trillion tokens, focusing on high-quality Chinese data. Naturally, the model's strength is its performance on Chinese benchmarks.
The company has also developed two chat variants using Supervised Finetuning (SFT) and Reinforcement Learning (RL): DeepSeek-V2 Chat (SFT) and DeepSeek-V2 Chat (RL).
The benchmark results published by DeepSeek-AI show that DeepSeek-V2 Chat achieves top performance among open-source models with only 21 billion activated parameters, making it currently the best performing open source MoE language model. It beats Mixtral 8x22B and LLaMA 3-70B in some benchmarks.
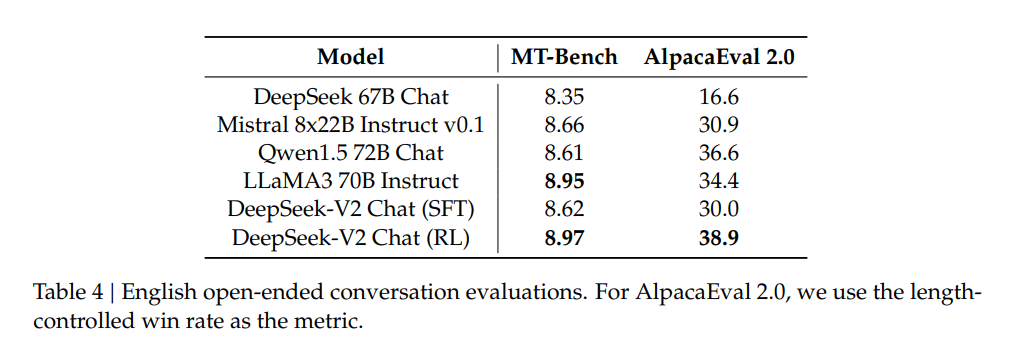
In particular, the RL version of DeepSeek-V2 Chat excels at understanding Chinese, performing on par with GPT-4. However, the reasoning ability of the model still falls short of larger models such as Ernie 4.0 and the GPT-4 models.
Open Source and affordable API
Despite being a relatively young startup, founded in 2023, DeepSeek offers a set of large language models for various use cases.
The models are open source and available for free local use. The company also provides a programming interface for easy integration into products without the need for extensive computing power.
DeepSeek's chat API is cheap, charging only $0.14 per million input tokens and $0.28 per million output tokens. By comparison, the next cheapest commercial language model, Claude 3 Haiku, costs $0.25 and $1.25, respectively.
Like other large language models, DeepSeek-V2 has some limitations, such as a lack of recent information in its training data and the presence of hallucinations. But the company plans to continue investing in large open-source models to move closer to its goal of artificial general intelligence (AGI).
For future iterations, DeepSeek aims to further improve cost efficiency and performance using the MoE architecture. While DeepSeek-V2 excels in Chinese language tasks and specific domains such as math and coding, the startup is likely to focus on higher-quality data in English and other languages for its next release, DeepSeek-V3, to better compete with models such as Claude 3 and GPT-4 on a global scale.
DeepSeek-V2 is available on Hugging Face and can be tried out for free after registering via email or Google account at chat.deepseek.com.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.