
Meta AI today released Llama 3, the next generation of its open-source language models. According to Meta, the new models are on par with some of the best proprietary models and will soon support multimodality and more languages.
Meta today announced the first two models in the next generation of Llama. The series, called Meta Llama 3, initially includes pre-trained and instruction-tuned LLMs with 8 and 70 billion parameters, respectively.
According to the company, these are the best open-source models in their class. The models are a big step forward compared to Llama 2 and show significantly improved capabilities in areas such as logical reasoning, code generation, and following instructions.
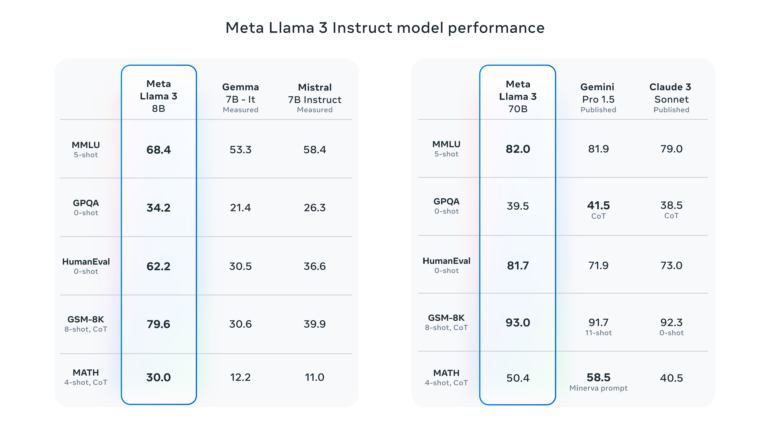
In the benchmarks presented by Meta, Llama 3 70B outperforms proprietary models such as Google's Gemini 1.5 Pro and Anthropic's Claude 3 Sonnet in several benchmarks such as MMLU, but lags behind leading models such as Claude 3 Opus and OpenAI's GPT-4 Turbo.
Llama 3: Training with 15 trillion tokens
The leap in performance is due in part to a massive increase in training data: Llama 3 was pre-trained on over 15 trillion tokens, all from publicly available sources. The dataset is seven times larger than Llama 2 and contains four times more code. More than 5 percent of the data is not in English, but covers over 30 languages - although Meta does not yet expect the same performance in these languages as in English.
In terms of architecture, Meta is based on the decoder-only transformer and uses a more efficient tokenizer with a vocabulary of 128,000 tokens. However, the first two models only have a context window of 8,000 tokens. The knowledge cutoff for Llama 3 8B is March 2023, for Llama 70B it is December 2023.
In order to use Llama 3 securely and responsibly, Meta provides several new tools, including updated versions of Llama Guard and Cybersec Eval, as well as the new Code Shield, which serves as a guardrail for the output of insecure code by language models.
Bigger and better Llama 3 models with up to 400 billion parameters to come
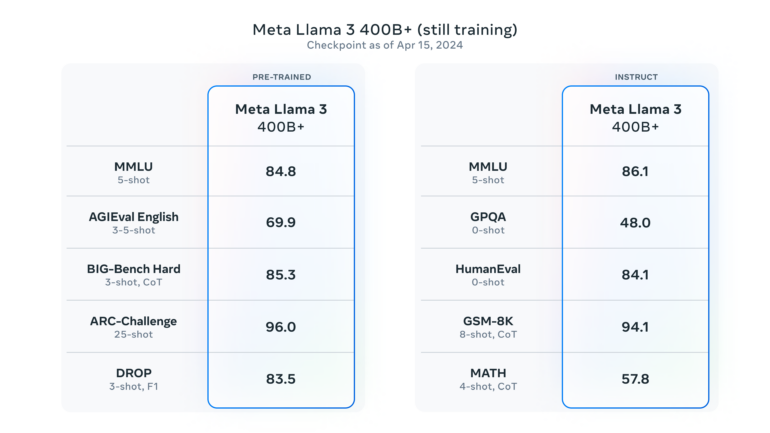
Llama 3 is not complete with the models released today: Meta will continue to develop the models and release additional models with new features such as multilingualism, a longer context window, and stronger overall capabilities in the coming months. According to Meta, the largest models in Llama 3 have over 400 billion parameters and are still in the training phase. Meta also plans to publish a detailed research paper once Llama 3 training is complete. The largest model could reach GPT-4 level, according to some preliminary benchmarks Meta shared from a recent snapshot of the 400B model.
The Llama 3 models will soon be available on Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake, with support for hardware platforms from AMD, AWS, Dell, Intel, NVIDIA, and Qualcomm. They are available for download from Meta's Llama 3 page and are currently available on Amazon SageMaker.





