Deepseek V3.2 rivals GPT-5 and Gemini 3 Pro, reaches IMO gold level as open source
Chinese AI lab Deepseek has unveiled V3.2, a new language model that matches GPT-5 and Google's Gemini 3 Pro in key benchmarks and reasoning tasks.
The team identified three main flaws in current open-source models: inefficient long-text processing, weak autonomous agent capabilities, and insufficient investment in post-training. V3.2 addresses these problems with a redesigned attention architecture and a massive scale-up in post-training, according to the newly published technical report. The company teased these capabilities in September with a preliminary version called V3.2-Exp.
The core upgrade is Deepseek Sparse Attention (DSA). Standard models re-check every previous token for each new response - a computationally heavy process for long chats. DSA uses a small indexing system to identify only the important parts of the text history.
By reading only what's essential, the model cuts computing costs without sacrificing quality. Deepseek says this significantly speeds up processing for long inputs, though the company didn't share specific numbers.
Deepseek has poured more resources into post-training—the reinforcement learning and alignment phase that happens after initial training. This budget now exceeds 10 percent of the original pre-training costs, up from around one percent just two years ago.
To build training data, the team first created specialized models for math, programming, logic, and agent tasks. These specialists generated data for the final model. Deepseek also built over 1,800 synthetic environments and thousands of executable scenarios based on real GitHub issues to train autonomous agents.
V3.2 matches GPT-5 and Gemini 3 Pro in benchmarks
In the AIME 2025 math competition, V3.2 scored 93.1 percent, just behind GPT-5 (High) at 94.6 percent. OpenAI has since shipped GPT-5.1 and updated Codex models.
For programming, V3.2 hit 83.3 percent on LiveCodeBench, again landing just behind GPT-5's 84.5 percent. Google's Gemini 3 Pro remains the leader, with 95.0 percent in AIME and 90.7 percent in LiveCodeBench.
On SWE Multilingual, which tests software development using real GitHub issues, V3.2 solved 70.2 percent of problems, beating GPT-5's 55.3 percent. It also outperformed GPT-5 on Terminal Bench 2.0 (46.4 percent vs. 35.2 percent), though it trailed Gemini 3 Pro (54.2 percent).
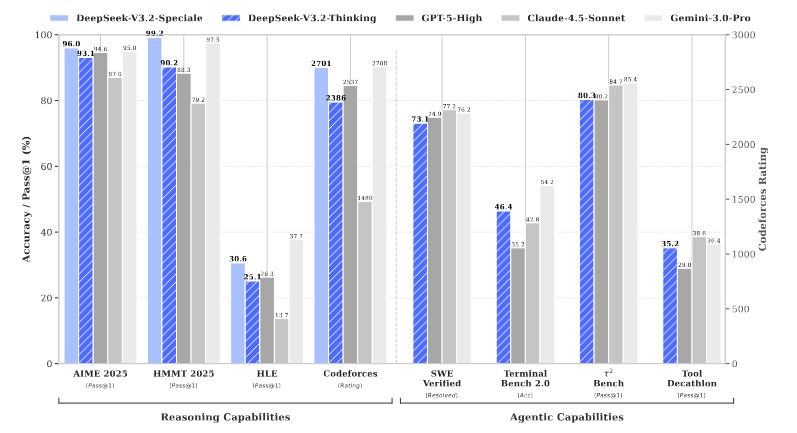
Deepseek beats OpenAI and Google to the math crown
Deepseek also released an experimental variant called "Speciale," which relaxes length restrictions for reasoning chains. This version hit gold at the 2025 International Olympiad in Informatics (10th place) and took second place at the ICPC World Final 2025. By integrating components from Deepseek Math V2, it also reached gold at the International Mathematical Olympiad 2025.
Speciale rivals Gemini 3 Pro in performance but consumes far more tokens. Solving Codeforces problems required an average of 77,000 tokens, compared to Gemini's 22,000. Because of the cost and latency hit, Deepseek went with stricter token limits in the standard V3.2 release.
This seems like a big deal. Both OpenAI and Google DeepMind announced models this summer capable of hitting this level, something many researchers thought wasn't possible with pure language models. Deepseek has now matched that performance, beaten both companies to release, and shipped it as open source. OpenAI has only said an improved version of its math model will drop in the next few months.
Where V3.2 still falls short
Despite the progress, Deepseek admits it still lags commercial frontier models in three areas: knowledge breadth, token efficiency, and performance on the most complex tasks. The team plans to address the knowledge gap through more pre-training - a strategy some researchers had previously written off as a dead end.
V3.2 is available now under an Apache 2.0 license on Hugging Face and via API. This release puts Deepseek squarely in the price war against OpenAI, offering a cheaper alternative for agent-based workflows. V3.2 also outperforms other open-weight models like Kimi K2 Thinking and MiniMax M2 when running on Model Context Protocol (MCP) servers.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.