Do large language models really need large context windows?

AI companies like Google, OpenAI, and Anthropic are touting extra-large context windows for their models, allowing them to process a lot of data at once. But are they really the best way forward?
The main development in large language models recently has been massive context windows. Companies say they can be used to process giant documents, like entire books or even series of books, all at once.
While this is true, they don't mention an important detail: the processing isn't reliable. The more information you put into the AI model, the more likely it is to miss essential details, for example in a summary.
This doesn't make large context windows useless, but it does make them less useful for many tasks. Also, large context windows mean that the models cost more to run and consume more power.
Making better use of small context windows
Researchers from Renmin University in China and the Beijing Academy of Artificial Intelligence now say in a paper that most long-text tasks can be done with smaller context windows. This is because often only parts of the long text matter for the task.
They developed a method based on GPT-3.5 called LC-Boost. LC-Boost breaks up long texts into shorter parts and lets the language model with a smaller context window choose which parts are needed for the task and how best to use them. This allows the model to process only the relevant parts and filter out unimportant information.
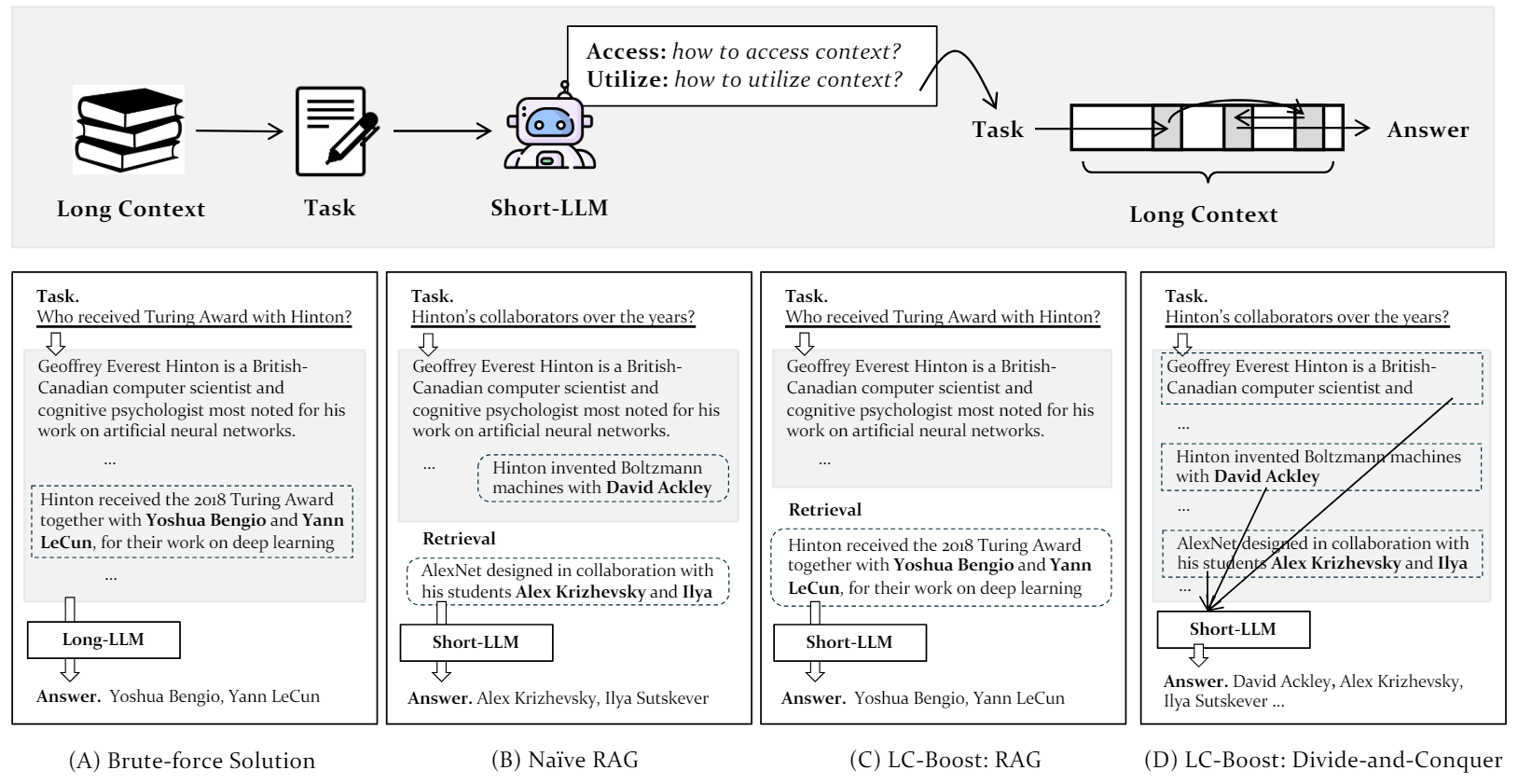
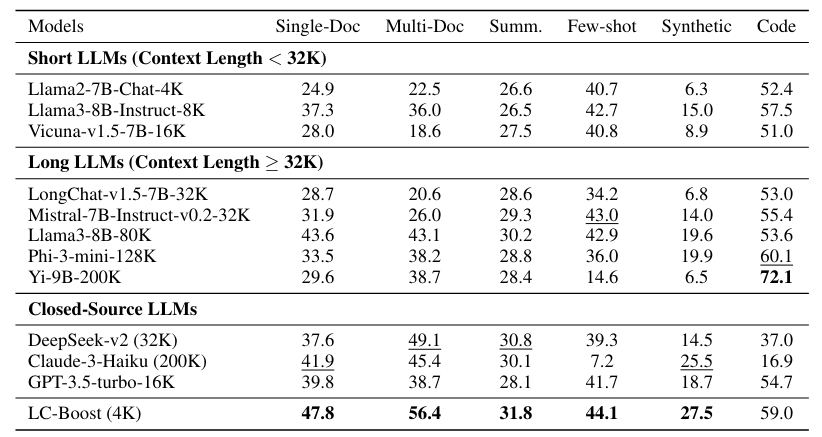
In tests on twelve datasets of question-answering, summarization, and code tasks, LC-Boost performed as well or better with a context window of 4,000 tokens than models with up to 200,000 context tokens. In particular, LC-Boost performed better on question-answering tasks because it was more accurate in finding the exact information needed for an answer.
To demonstrate how well LC-Boost works, the researchers used the 122,000-word novel "Harry Potter and the Chamber of Secrets" as an example.
When asked "List all the characters in the book who were petrified," the LC-Boost system found three of the five characters in the story who were petrified, searching the text step by step and summarizing the results at the end. It's not perfect, but it's better than, say, Claude 3 Haiku, which only finds one character.

The researchers' energy consumption analysis also shows that LC-Boost, with its short context window, consumes much less energy than models that process the entire text at once. With the latter, energy consumption explodes as the context lengthens.
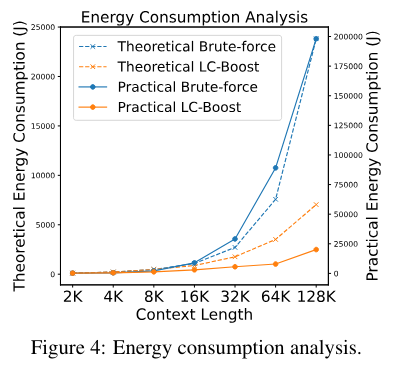
The authors see their approach as an important step toward limiting the huge resource consumption of large language models. They expect AI systems to be ubiquitous in the future, which means that their energy requirements could become a major environmental problem. More efficient methods like LC-Boost may be in demand.
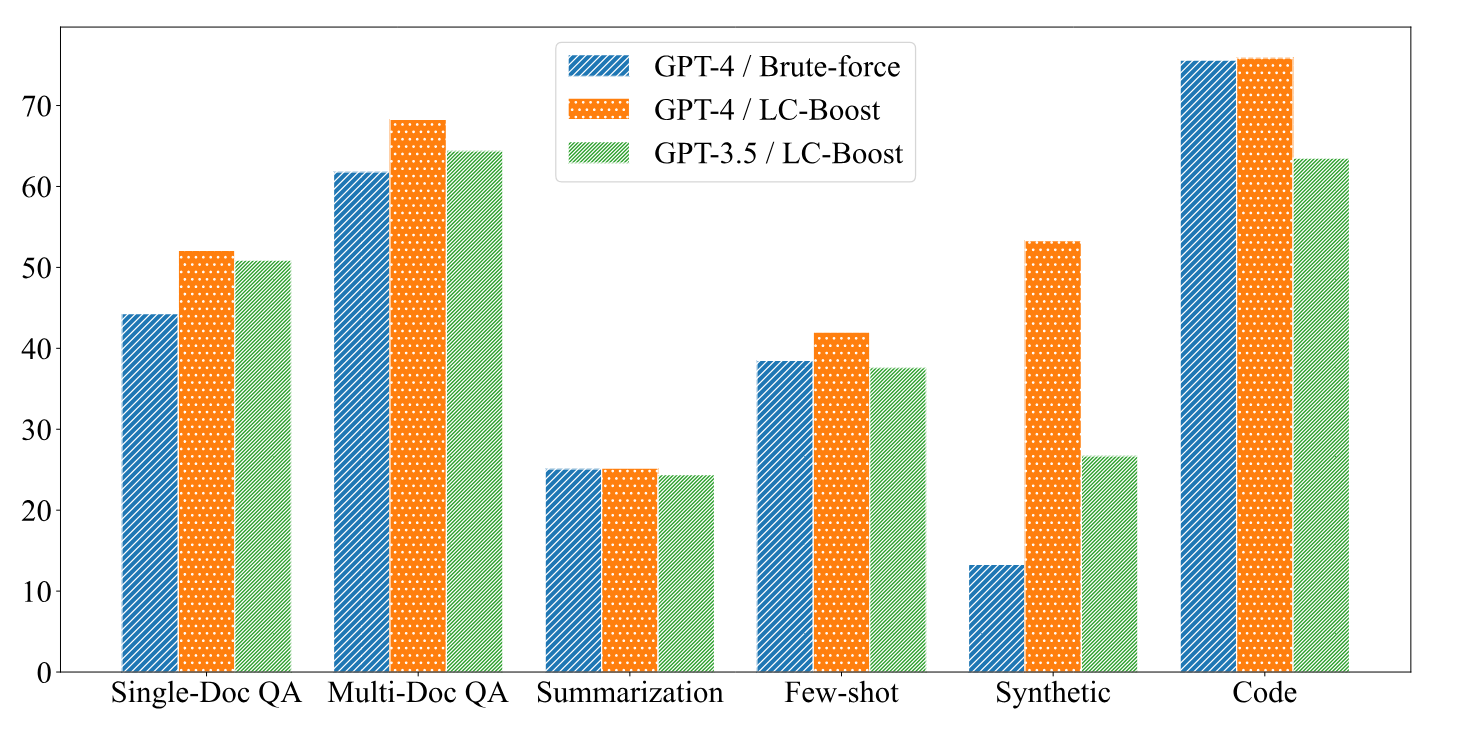
The study shows that there may be alternatives to large context windows that can achieve at least equivalent results with smarter methods using smaller windows - and at significantly lower energy consumption. However, there may be more complex scenarios that require an understanding of the entire context. According to the authors, LC-Boost may be less suitable for such tasks.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.