Even frontier LLMs from GPT-5 onward lose up to 33% accuracy when you chat too long
The latest generation of large language models—from GPT-5 onward—still struggles when tasks are spread across multiple conversation turns. Researcher Philippe Laban and his team tested current models on six tasks covering code, databases, actions, data-to-text, math, and summarization. Performance drops significantly when information is split across several messages (sharded) instead of a single prompt (concat).
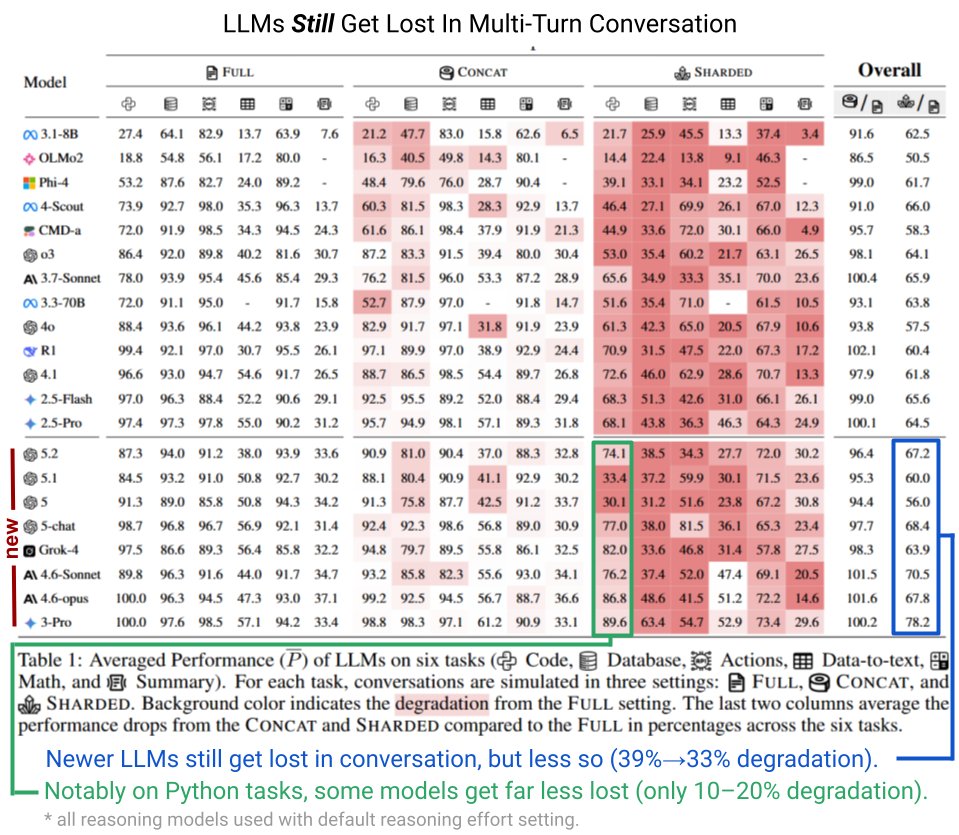
Newer models did slightly better—performance degradation shrank from 39 to 33 percent—but the issue is far from solved. The biggest gains showed up in Python tasks, where some models only lost 10 to 20 percent. Laban suspects real-world losses could be even worse, since the tests used simple user simulations. Users who change their mind mid-conversation would likely cause steeper drops.
Technical tweaks like lowering temperature values don't fix the problem, the original study found. The researchers recommend starting a fresh conversation when things go sideways, ideally by having the model summarize all requests first and using that summary as the starting point for a new chat.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe now