
Google Brain shows that large language models benefit from fine-tuning with instructional data.
So-called fine-tuning means that pre-trained large language models are trained with additional data, for example, to specialize them for specific application scenarios. A research group at Google now shows that fine-tuning with instruction datasets can improve the performance of large language models for many tasks.
Fine-tuning with 1,836 language tasks
The fine-tuning approach with instructions itself is not new. In particular, the Google Brain team tested the scaling of the method and re-trained its large language models PaLM, U-PaLM, and the open-source T5 model with a total of 1,836 instructions.
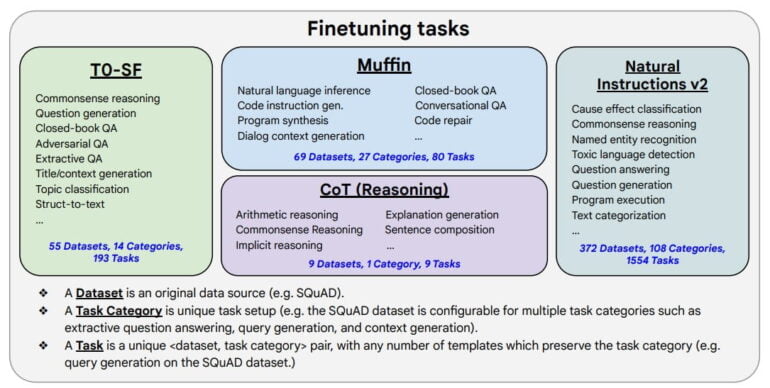
Most of the tasks come from the Natural Instructions v2 dataset, which contains instructions for logical reasoning, for example. According to the research team, fine-tuning with examples of chain-of-thought reasoning also helps with common sense.
With chain of thought prompts, the AI is asked to solve language tasks step by step, documenting each step. Training with only nine CoT datasets provided significant improvement in this skill compared to previous FLAN models. In addition, the prompt is simplified because the FLAN model does not require a CoT example in the prompt. The request for step-by-step reasoning is sufficient.
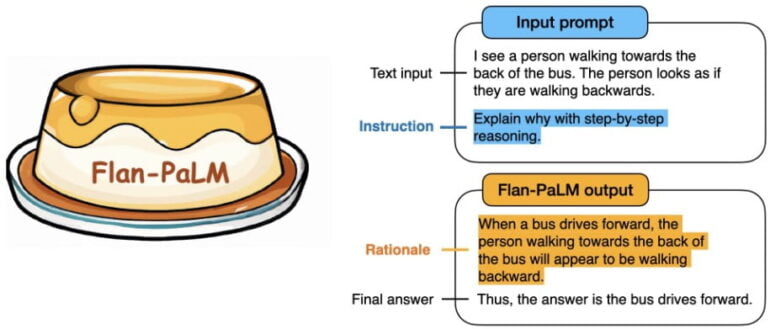
The research team reports a "dramatic improvement" in prompting and multi-step reasoning. PaLM and T5 models benefit from fine-tuning with instructions in common benchmarks, regardless of their size, and beat all non-Flan models.
To show the generality of our method we train T5 (encoder-decoder trained with span-corruption), PaLM (decoder-only trained with next-token prediction) and U-PaLM (mixture of denoisers), covering a wide range of sizes (80M to 540B).
ALL models benefit significantly! pic.twitter.com/KYRvbiJf4e
- Hyung Won Chung (@hwchung27) October 21, 2022
20 Human testers rated the usability of the Flan PaLM model better than that of the non-Flan PaLM model nearly 80 percent of the time in areas such as creativity, contextual reasoning, and particularly complex reasoning.
Fine-tuning with instructional data scales strongly at the beginning
The performance scaling when training with instructional data, however, decreases significantly as the instructional data sets become larger. There is a significant performance jump between models without fine-tuning and models fine-tuned with 282 tasks. However, the difference between the latter and the model with 1,836 tasks is small. In general, fine-tuning scales with model size.
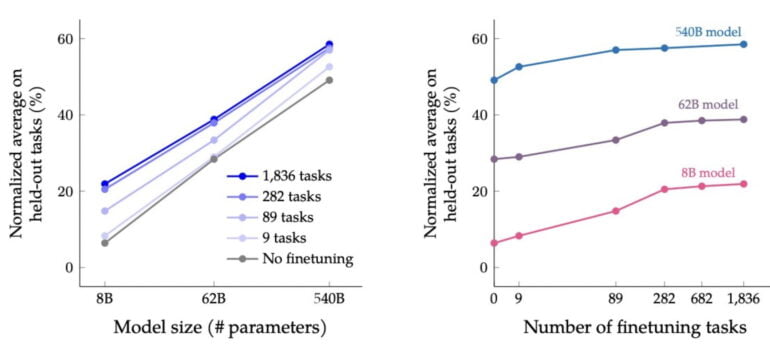
Flan-PaLM achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. Flan-PaLM also has improved usability—for example, it can perform zero-shot reasoning without prompt engineering or few-shot exemplars. Additionally, we show that instruction finetuning is compatible with a range of model sizes, architectures, and pre-training objectives.
Paper Conclusion
The research team publishes the Flan-T5 model as open source on Github. A comparison demo between Flan-T5 and vanilla T5 is available at Hugging Face.





