Google unveils the latest advance in artificial intelligence: The PaLM language AI model is huge, powerful, and the first building block of a grand vision.
Last year, Google unveiled the Pathways concept, an AI architecture for the next generation of artificial intelligence. The vision: A single, large AI model should master many tasks.
With the PaLM model (Pathways Language Model), Google is now unveiling the first building block of the Pathways architecture for natural language processing.
PaLM is one of the largest AI language models
With 540 billion parameters, PaLM is one of the largest of its kind. Google sister Deepmind unveiled Gopher in December 2021, a model with 280 billion parameters that could beat OpenAI's well-known GPT-3 language AI with 175 billion parameters on many language tasks. Nvidia and Microsoft jointly trained the 530-billion-parameter Megatron model. All these systems are based on the Transformer architecture.
The basis for the AI training is a training system developed by Google for Pathways, which was used to train PaLM on 6144 chips in parallel on two Cloud TPU v4 pods. According to Google, this was the largest TPU-based AI training system to date.
PaLM was trained with a mix of English and multilingual datasets. The texts came from "high-quality" websites such as Wikipedia, books and discussions, and - in the case of code examples - from Github.
Language AI continues to get better as it gets bigger
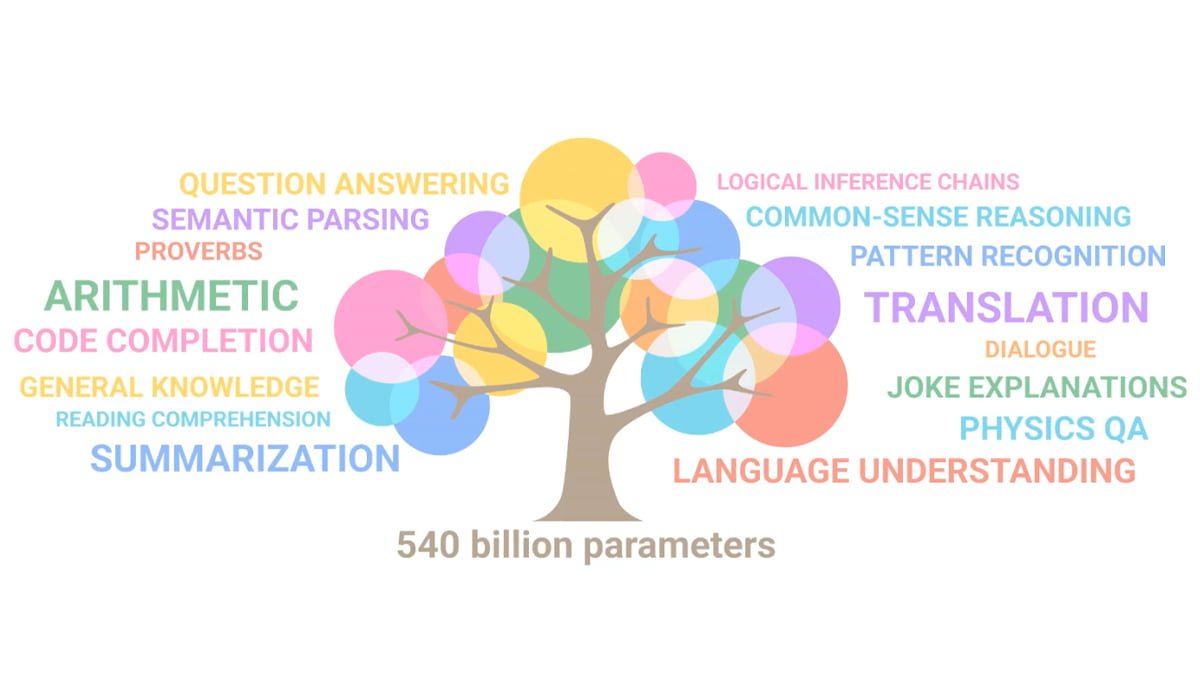
Probably the most important insight from Google's PaLM model is that the language processing of AI models continues to scale with the number of their parameters. Simply put, the larger the model, the better and more diverse it processes language. Google illustrates this in the following animation.
The more parameters the language model has, the more capabilities it should develop. Google compares this to branches on a growing tree. | Video: Google
According to Google, PaLM demonstrates "breakthrough capabilities" in numerous particularly challenging language tasks such as language comprehension and generation, reasoning, and code-related tasks.

For example, the model is said to be able to distinguish cause and effect, understand combinations of terms in appropriate contexts, and even guess a movie based on emojis, as shown in the following animation.
Video: Google
As is common practice with large language models, PaLM can also be fine-tuned with a few additional examples for specific tasks such as code generation. In this so-called "few-shot" learning, PaLM is said to beat all known large AI language models, making the model more versatile.
In particular, logical thinking and a "general knowledge" should benefit from an increasing number of parameters. If the AI is offered the solution path of a simple text task in an example ("chain of thought prompting"), it can solve a comparable task independently.

PaLM's text comprehension should go so far that the AI can explain simple jokes. Google demonstrates this with the following example, in which the cloud computer (pod) used for AI training is compared to a whale.
The prompt "Explain this joke" in combination with the indication of when the joke starts is sufficient for the PaLM model to provide an appropriate explanation. The joke along with its explanation was not included in the training data.

For code tasks, PaLM is said to achieve similar performance to OpenAI's Codex with fewer data examples, thanks to its strong few-shot capability. There were about five percent code examples in the pre-training data set.
For the Python programming language, PaLM required 50 times less training data than Codex for comparable performance, according to Google. Google's researchers see this as an indication that "larger models can be more sample efficient than smaller models because they better transfer learning from other programming languages and natural language data."
On the path to the Pathways vision
The Google team believes that the approach of training huge AI models and then matching them to specific tasks with limited data is not maxed out with PaLM. Few-shot capability is expected to benefit further from larger models: "Pushing the limits of model scale enables breakthrough few-shot performance of PaLM across a variety of natural language processing, reasoning, and code tasks."
PaLM thus paves the way for even higher-performance models by "combining the scaling capabilities with novel architectural choices and training schemes". It is therefore an important step toward the grand Pathways vision, according to the scientists, where a single AI model can understand diverse data to efficiently handle thousands or even millions of tasks.
The PaLM code is available on Github.




