A Chinese language model performs better than OpenAI's GPT-3 and Google's PaLM. Huawei shows a Codex alternative.
Large AI models for language, code, and images play a central role in the current proliferation of artificial intelligence. Researchers at Stanford University therefore even want to call such models "foundation models." The pioneer in the development of very large AI models is the U.S. AI company OpenAI, whose GPT-3 language model first demonstrated the usefulness of such AI systems.
In addition to many text tasks, GPT-3 also demonstrated rudimentary code capabilities. OpenAI then leveraged its close collaboration with Microsoft to use Github data to train the large code model Codex. Codex also serves as the foundation for Github's CoPilot.
China's AI firms develop powerful alternatives to Western models
Meanwhile, the list of large language models from Western companies and institutions is long.
In addition to GPT-3, there is Google's PaLM, AI21 Labs' Jurassic-1, Meta's OPT models, BigScience BLOOM, and Aleph Alpha's Luminous, for example. Code models are also available from Google, Amazon, Deepmind, and Salesforce. However, these models are primarily trained with Western data and are therefore not suitable for use in China - if access is possible or permitted at all.
Chinese companies and research institutions, therefore, began producing their own alternatives at the latest with the presentation of GPT-3. In 2021, for example, Huawei showed PanGu-Alpha, a 200 billion parameter language model trained with 1.1 terabytes of Chinese language data. The Beijing Academy of Artificial Intelligence (BAAI) unveiled Wu Dao 2.0, a 1.75 trillion parameter multimodal model, in the same year.
GLM-130B language model outperforms GPT-3
Now, researchers at China's Tsinghua University have unveiled GLM-130B, a bilingual language model that outperforms Metas OPT, BLOOM, and OpenAI's GPT-3, according to the team's benchmarks. The Chinese- and English-language model's Few-Shot performance surpassed the level of the previous top model GPT-3 in the Massive Multi-Task Language Understanding (MMLU) benchmark.
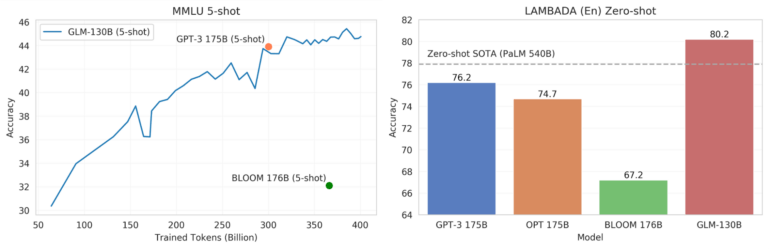
The team also tested GLM-130B against LAMBADA, a zero-shot benchmark for predicting the last word in a sequence of words. The benchmark is used to evaluate the language modeling capabilities of large language models.
Here, the Chinese model outperformed even previous leader PaLM - despite 410 billion fewer parameters. For the training, the team relied on a method developed at Tsinghua University (GLM), as well as 400 Nvidia A100 GPUs.
This is the first time a large language model from China has outperformed Western models. GLM-130B is available on Github and HuggingFace.
Code model PanGu coder achieves Codex performance
As a consistent evolution of PanGu, Huawei's Noah's Ark Lab and Huawei Cloud also recently showed a Chinese alternative to Copilot, Codex and other code models. PanGu-Coder completes code like the Western models and builds on the work done with PanGu. Like Codex, PanGu follows a training method similar to language models - the key difference is the training data: Code instead of text.
PanGu-Coder comes in several models, ranging from 317 million to 2.6 billion parameters. According to Huawei, the Chinese models are on par with Codex, AlphaCode, and alternatives in human evaluations - and in some cases outperform them. The company also shows a variant trained with a curated dataset (PanGu-Coder-FT) that performs even a bit better.
PanGu-Coder comes just under a year after the release of OpenAI's Codex. Huawei is thus following the pattern of PanGu-Alpha, which was also released just under a year after GPT-3.