FlexOlmo enables organizations to collaboratively train LLMs without data sharing
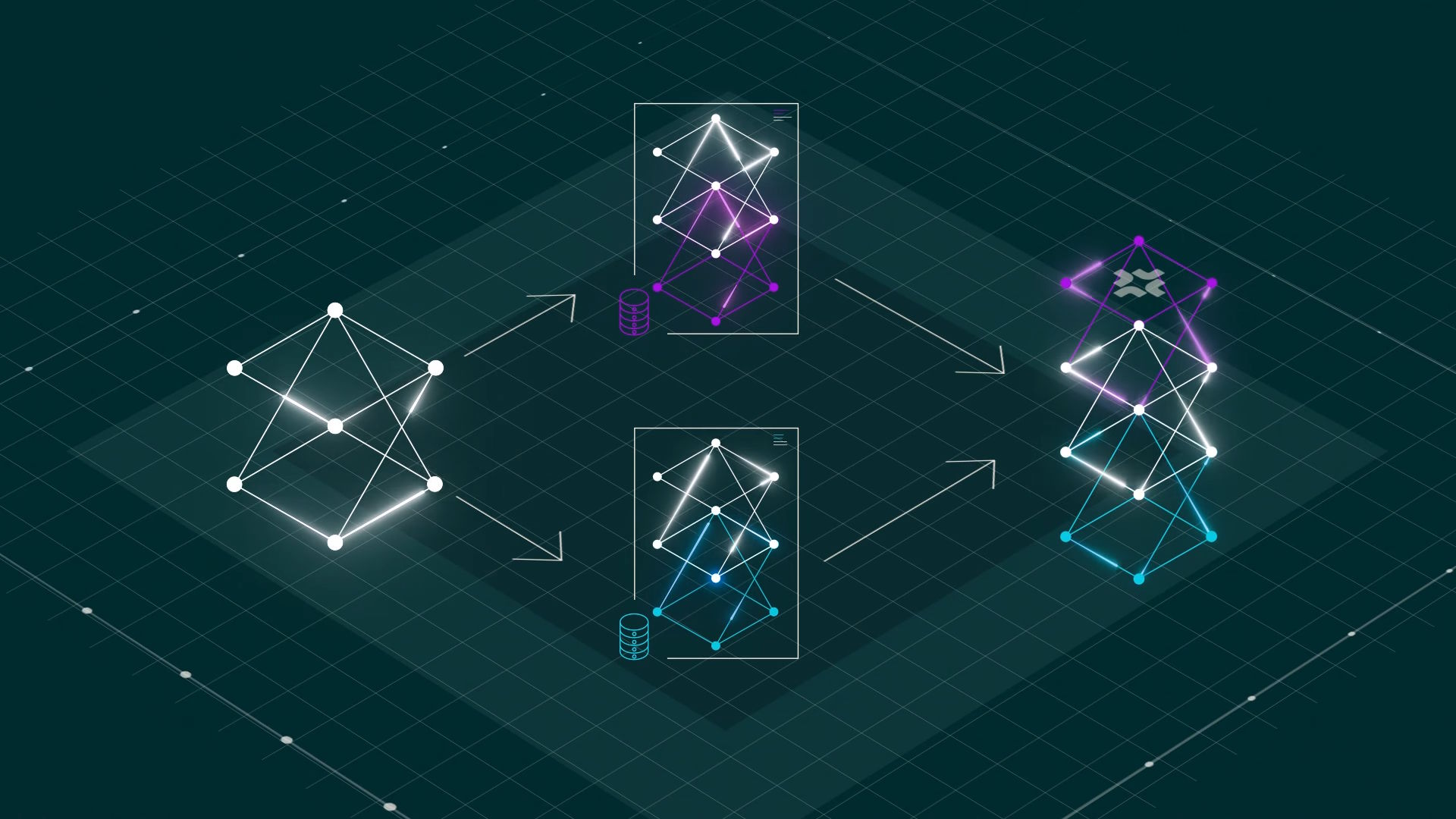
FlexOlmo, developed by the Allen Institute for AI, shows that organizations can collaboratively train language models on local datasets without sharing sensitive data.
In regulated industries, organizations often have valuable data for training AI models but can't share it outside their walls. FlexOlmo takes a different approach, using a mixture-of-experts setup where each expert is trained independently on closed datasets. Instead of exchanging raw data, organizations train their own expert locally and only share the resulting model weights with the group.
The main issue with independently trained experts is coordination. FlexOlmo tackles this by using a frozen public model as a fixed reference. The public expert remains unchanged during training, while new experts are trained on local data. This way, all experts align with the same reference model and can be combined later without additional retraining.
Flexibility for sensitive data
FlexOlmo is well-suited for cases where data access needs to be tightly controlled. Data sources can be activated or deactivated depending on the application. For example, toxic content might be included for research but excluded from general use.
The researchers demonstrated this by removing the news expert in a test run. As expected, performance on news-related tasks dropped, but results in other areas remained stable.
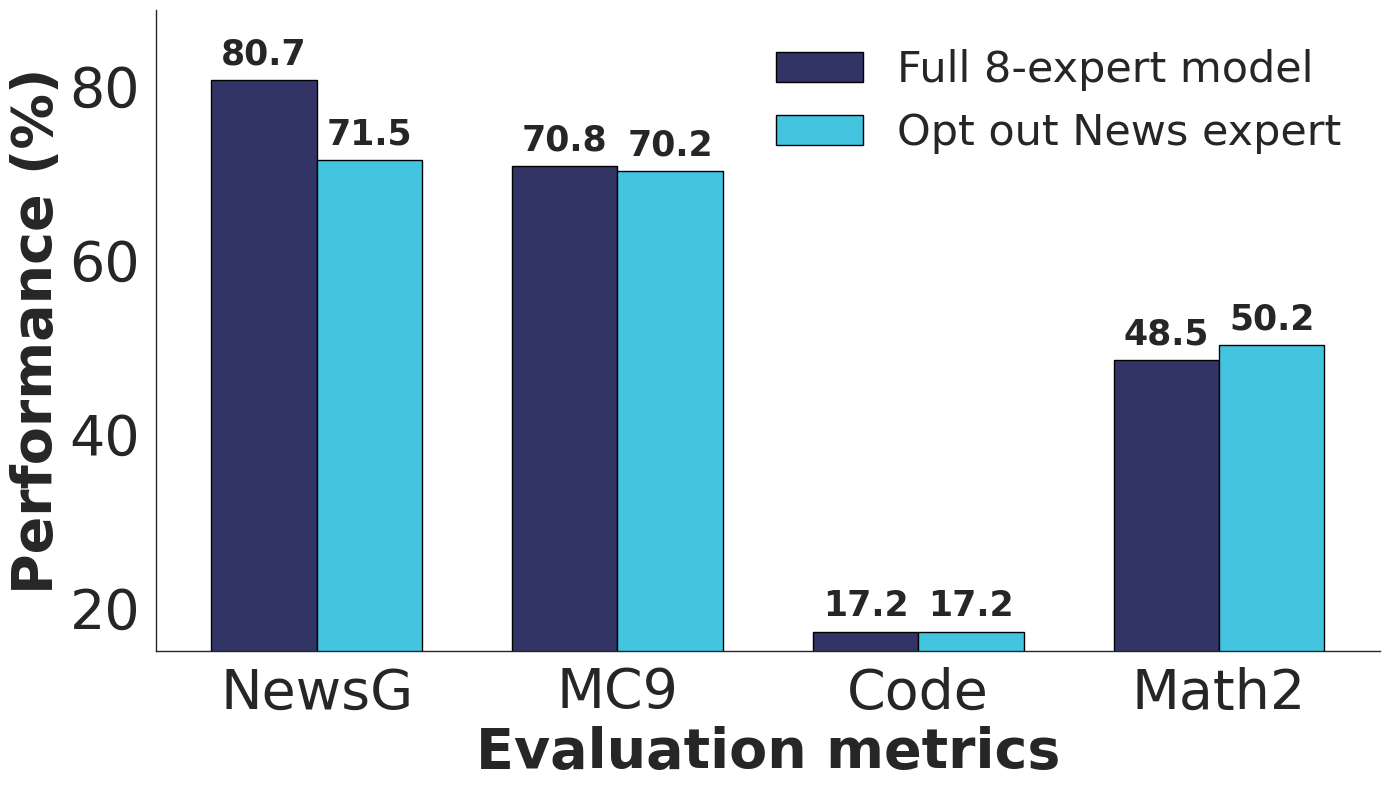
Even if licenses change or usage rights expire, data sources can be deactivated later without retraining the entire model. The final model has 37 billion parameters, with 20 billion active.
Performance gains in real-world tests
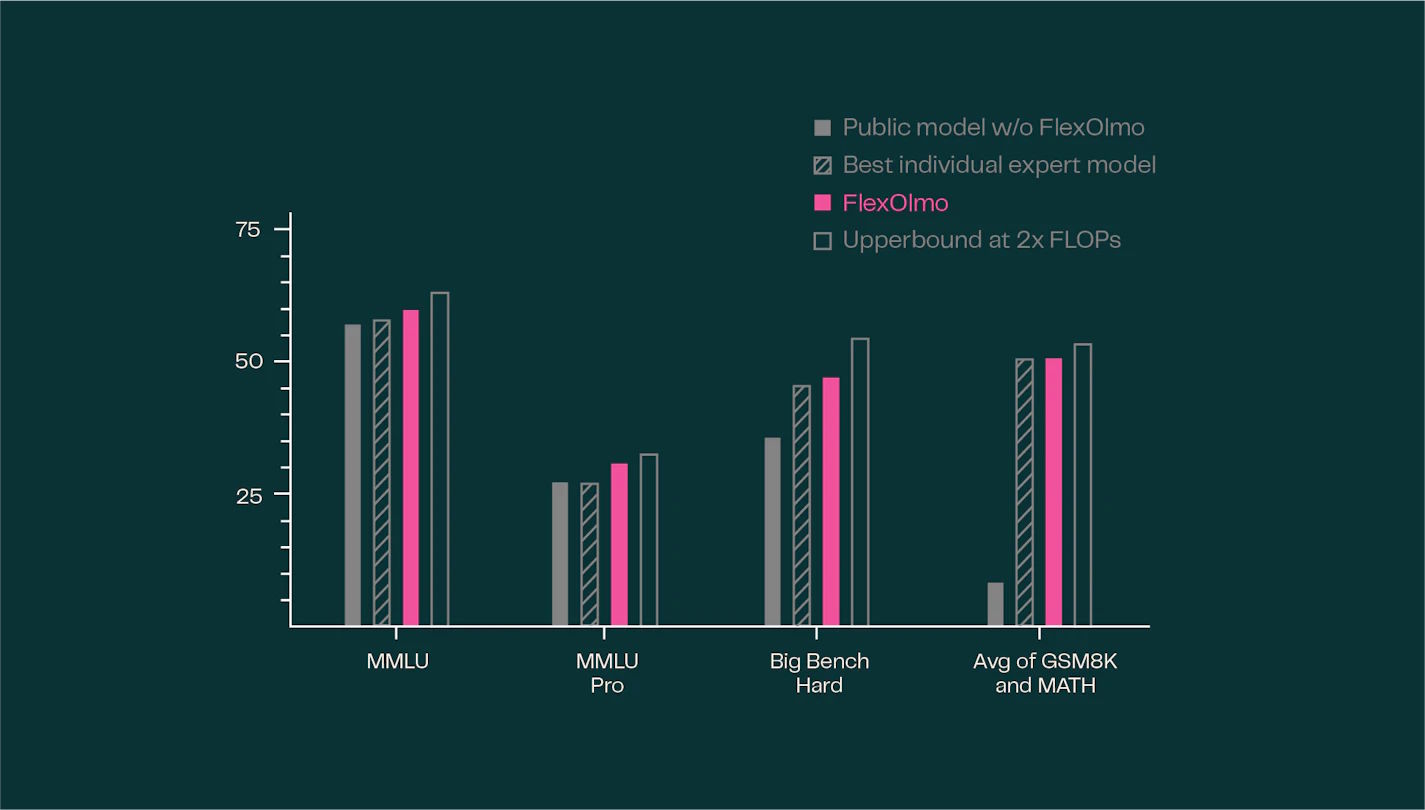
The team evaluated FlexOlmo using a mix of public data and seven specialized datasets: News, Creative Writing, Code, Academic Papers, Educational Text, Math, and Reddit content.
When tested on 31 tasks, FlexOlmo showed an average improvement of 41 percent over a model trained only on public data. In general benchmarks, FlexOlmo actually outperformed a hypothetical model that had access to all data with the same computational effort. Only a model trained on the entire dataset with double the resources did slightly better.
Because data owners only share trained model weights, the risk of data leakage is minimal. In testing, attacks to recover training data succeeded just 0.7 percent of the time. For organizations with especially sensitive data, FlexOlmo supports differentially private training, which offers formal privacy guarantees. Each participant can enable this option independently. The Allen Institute has also released OLMoTrace, a tool for tracing language model outputs back to their training sources.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.