Google DeepMind's SCoRe teaches AI to fix some of its own mistakes without outside help

Google DeepMind researchers have developed a new technology called SCoRe to help large language models recognize and fix their own mistakes.
Current large language models (LLMs) struggle with self-correction, often requiring multiple models or external checks. SCoRe, which stands for "Self-Correction via Reinforcement Learning," uses reinforcement learning to train a single model using only self-generated data.
SCoRe works in two phases. First, it optimizes model initialization to generate corrections on the second try while keeping initial responses similar to the base model. This uses a special loss function considering both aspects.
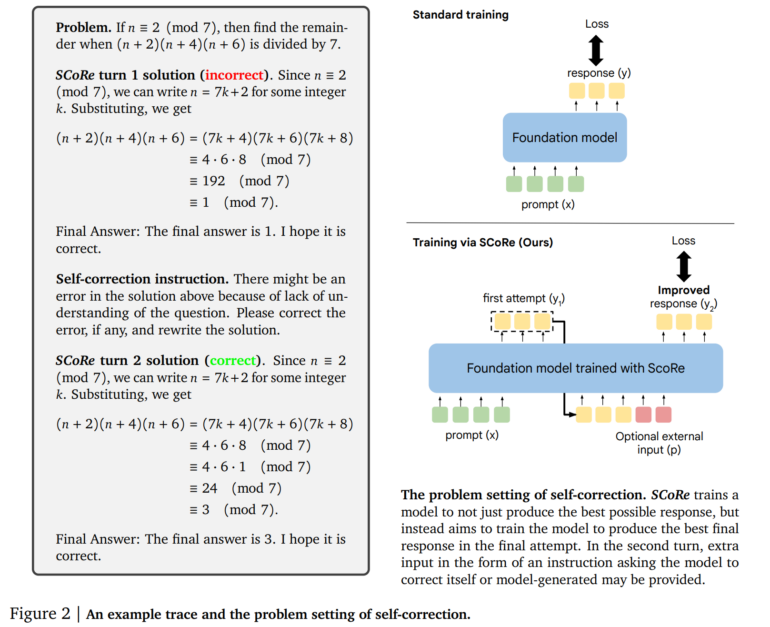
The second phase applies multi-stage reinforcement learning. The model learns to improve both first and second answers. A reward function encourages self-correction by giving more weight to improvements between attempts. Unlike methods needing external verification, SCoRe uses only self-generated training data. The model creates its own examples by solving problems and trying to improve solutions.
SCoRe achieves significant self-correction
Tests with Google's Gemini 1.0 Pro and 1.5 Flash models showed significant gains. On the MATH benchmark for mathematical reasoning, self-correction improved by 15.6 percentage points. For code generation on HumanEval, it rose 9.1 percentage points.
The researchers say SCoRe is the first approach achieving meaningful positive intrinsic self-correction, allowing models to improve answers without external feedback.
However, SCoRe currently only trains for one round of self-correction. Future work could explore multiple correction steps.
The team concludes that teaching metastrategies like self-correction requires going beyond standard LLM training. Multi-stage reinforcement learning may offer new possibilities in this area.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.