Google outlines MIRAS and Titans, a possible path toward continuously learning AI

A year after publishing its Titans paper, Google has formally detailed the architecture on its research blog, pairing it with a new framework called MIRAS. Both projects target a major frontier in AI: models that keep learning during use and maintain a functional long-term memory instead of remaining static after pretraining.
Google frames the motivation in familiar terms. Traditional Transformers struggle with very long inputs like books, genome sequences, or extended videos because their computational cost grows quadratically with context length. Faster alternatives such as modern RNNs or state-space models scale better but compress the entire context into a single internal state, losing important details. Titans is designed to bridge that gap by combining precise short-term memory through windowed attention with a separate, trainable long-term memory that can update during inference and selectively retain surprising or unexpected information.
The company is also introducing MIRAS, a theoretical framework first described in April in the paper "It's All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization". The researchers argue that many of the new sequence models released in recent years - from Transformer variants to RetNet, Mamba, DeltaNet, and RWKV - can be viewed as different implementations of the same underlying idea: an internal lookup system that links inputs (keys) to outputs (values).
MIRAS breaks this system into four design questions. What does the lookup structure look like - a vector, a matrix, or a small or deep network? What internal scoring rule determines what gets stored well? How quickly does new information overwrite old entries? And what update rule governs how those entries change over time? Using this perspective, Google derives new attention-free models like Moneta, Yaad, and Memora that deliberately explore these design spaces and, in tests with extremely long contexts, sometimes outperform Mamba2 and standard Transformers.
Titans and MIRAS reflect the limits of today’s dominant Transformer architectures and may represent part of the shift toward what Ilya Sutskever recently described as a new era of AI research. In an interview with Dwarkesh Patel, the former OpenAI chief scientist argued that simply scaling data and compute is hitting diminishing returns, and outlined his startup SSI’s vision of a superintelligence that learns on the job more like a talented teenager than a fully formed AGI dropped out of a training cluster.
Google’s approach differs from Sutskever’s but targets the same gap: moving beyond static, one-time pretrained models toward systems that expand their capabilities over time, whether through explicit memory modules like Titans or through new learning paradigms still waiting to be discovered.
Original article from January 17, 2025
Google researchers have developed a new type of Transformer model that gives language models something similar to long-term memory. The system can handle much longer sequences of information than current models, leading to better performance across various tasks.
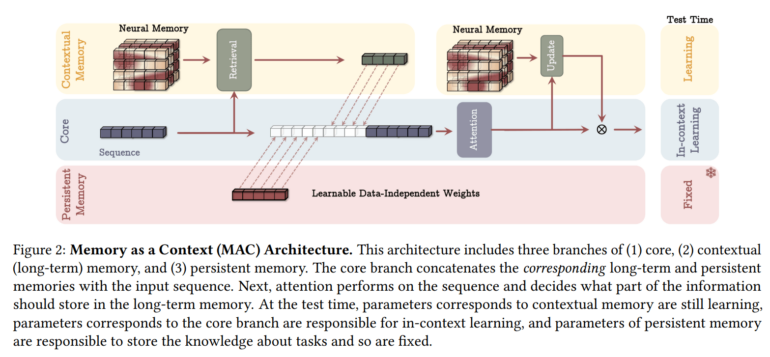
The new "Titans" architecture takes inspiration from how human memory works. By combining artificial short and long-term memory through attention blocks and memory MLPs, the system can work with long sequences of information.
One of the system's clever features is how it decides what to remember. Titans uses "surprise" as its main metric - the more unexpected a piece of information is, the more likely it gets stored in long-term memory. The system also knows when to forget things, helping it use memory space efficiently.
The team created three different versions of Titans, each handling long-term memory differently:
- Memory as Context (MAC)
- Memory as Gate (MAG)
- Memory as Layer (MAL)
While each version has its strengths, the MAC variant works especially well with very long sequences.
Better performance on long-context tasks
In extensive testing, Titans outperformed traditional models like the classic Transformer and newer hybrid models like Mamba2, particularly when dealing with very long texts. The team says it can handle context windows of more than 2 million tokens more effectively, setting new records for both language modeling and time series prediction with long contexts.
The system also excelled at the "Needle in the Haystack" test, where it needs to find specific information in very long texts. Titans achieved over 95% accuracy even with 16,000-token texts. While some models from OpenAI, Anthropic, and Google perform better, they're much larger - Titans' biggest version has only 760 million parameters.
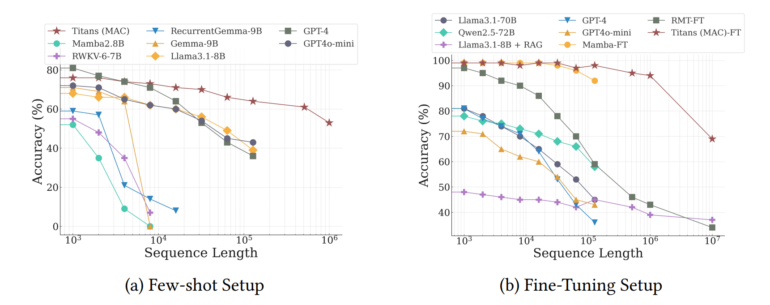
Titans really showed its strength in the BABILong benchmark, a challenging test of long-term comprehension where models need to connect facts spread across very long documents. The system outperformed larger models like GPT-4, RecurrentGemma-9B, and Llama3.1-70B. It even beat Llama3 with Retrieval Augmented Generation (RAG), though some specialized retrieval models still perform better.
The team expects to make the code publicly available in the near future. While Titans and similar architectures could lead to language models that handle longer contexts and make better inferences, the benefits might extend beyond just text processing. The team's early tests with DNA modeling suggest the technology could improve other applications too, including video models - assuming the promising benchmark results hold up in real-world use.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.