- Added Oriol Vinyals's statement
Update from January 27, 2024:
Oriol Vinyals, head of deep learning at Google and co-lead of Gemini, points out that evaluating language models is "hard and nuanced," with academic evaluations leaking into the training datasets of AI models.
Vinyals calls human evaluation "far superior," and says it "feels good that Bard Gemini Pro (free tier) climbed quite high on lmsys," suggesting that Gemini Ultra may perform even better.
Original article dated January 26, 2024:
Google's Bard chatbot is powered by a new Gemini model. Early users rate it as similar to GPT-4.
Google's head of AI, Jeff Dean, announced the new Gemini model on X. It is a model from the Gemini Pro family with the suffix "scale".
Thanks to the Gemini updates, Bard is "much better" and has "many more capabilities" compared to the launch in March, according to Dean.
Dean does not explain what "scale" means, but the name suggests that it could be a larger (scaled) version of the previous Pro model, which according to benchmarks does not even beat GPT-3.5 (free ChatGPT).
Pro is Google's second-tier Gemini model, behind the top-of-the-line Gemini Ultra, which has yet to be released.

GPT-Pro "scale" tied with GPT-4 in human evaluation
Remarkably, the new Pro model immediately took second place in the neutral Chatbot arena benchmark, ahead of the two GPT-4 models 0314 (March 2023) and 0613 (Summer 2023), but behind GPT-4 Turbo (November 2023). The new Bard model is the first to break into the GPT-4 phalanx.
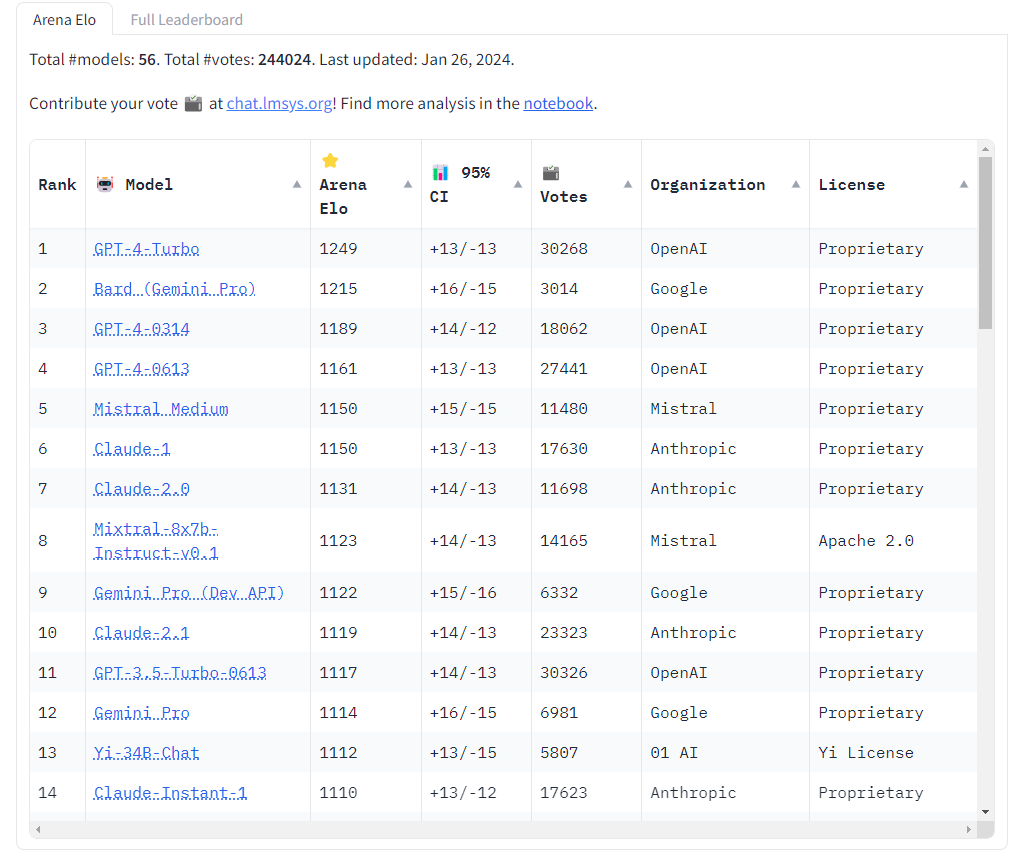
Chatbot Arena applies the Elo rating system used in chess and e-sports to evaluate and compare the performance of different language models. In the Arena, different models compete against each other in anonymous, randomly selected duels.
Users interact with the models and vote for their preferred responses. These votes are used to determine the ranking in the leaderboard. The platform collects all user interactions but only counts the votes cast if the names of the models are unknown, i.e., the user did not ask for the name.
Because these are user ratings or perceived quality, Chatbot Arena's results may differ from the results of a typical synthetic benchmark.
This is also the problem: the new Bard model has only been rated about 3,000 times so far, while the GPT-4 models have been rated up to 30,000 times. So the result could still shift, and the gaps in the benchmark are generally small anyway. Alternative benchmark results for GPT Pro-Scale are not available.
In any case, this is a respectable achievement for Google and makes one curious about Gemini Ultra, Google's most capable AI model, which will be released soon and is expected to outperform Gemini Pro-Scale.