Is GPT-4 Turbo "smarter" than GPT-4, as announced by Sam Altman? And what does that even mean?
OpenAI's latest AI model GPT-4 Turbo is available as a preview via the OpenAI API and directly in ChatGPT. Since the preview was released on 6 November, the model has already been updated once.
According to OpenAI CEO Sam Altman, GPT-4 Turbo is "much faster", "smarter" and, above all, cheaper than GPT-4. While speed and price are obvious, the "smartness" of the new model is the subject of heated debate on forums and social media. Some report obvious performance losses and see the GPT-4's capabilities as steadily declining since the first version, others report improvements, and still others report gains in some use cases and losses in others.
GPT-4 vs. GPT-4 Turbo in code benchmarks
The developers of Mentat AI, an AI-based coding assistant, tested the new model on coding tasks. GPT-4 (gpt-4-0314) solved 86 out of 122 tasks, while GPT-4 Turbo (gpt-4-1106-preview) solved 84 out of 122 tasks. However, a closer look at the results showed that GPT-4 solved 76 items in the first trial and 10 in the second trial, while GPT-4 Turbo solved only 56 items in the first trial and 28 in the second trial.
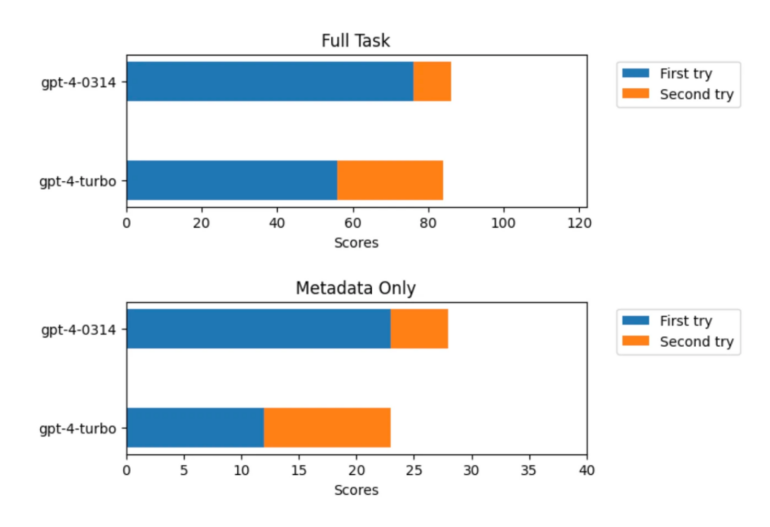
The team, therefore, suspects that GPT-4 memorized a large proportion of the training tasks and that this knowledge may have been lost in GPT-4 Turbo due to optimizations such as distillation. To test this theory, the team repeated the benchmarks without showing the models the instructions for each task, just the names of the tasks, the functions, and a reference to the source of the tests. Without instructions, an AI model can only solve the tasks if it has memorized them.
GPT-4 was able to solve almost 60 percent of the tasks, GPT-4 Turbo only 30 percent. The team interprets these results as a clear indication that GPT-4 memorized more tasks than GPT-4 Turbo. According to these results, GPT-4 could therefore have a kind of "memory bonus" that gives it an advantage in some benchmarks - and in practice. Of course, this could also be a disadvantage in other use cases, for example, if it spits out memorized blocks of code instead of looking for a more efficient solution.
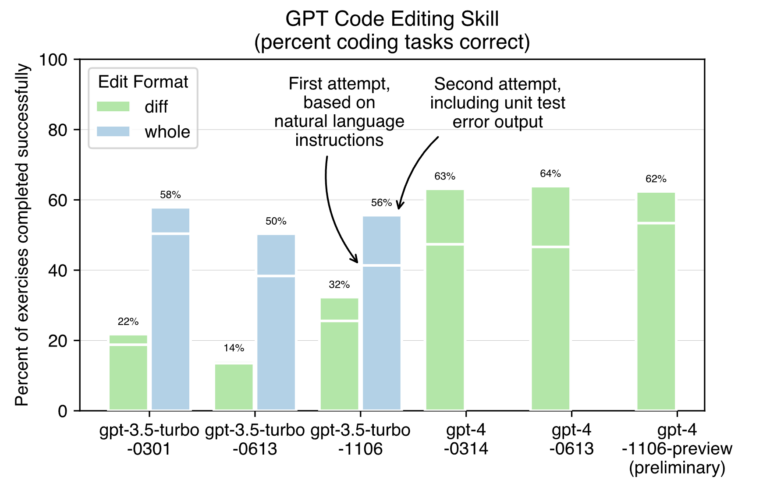
Aider, another AI coding assistant, also tested the new model with coding tasks. As expected, GPT-4 Turbo is significantly faster than previous GPT-4 models. Precise measurements are not yet possible due to the current limitations of OpenAI. It also appears to be better at generating correct code at the first attempt. It solves 53% of code tasks on the first try, while previous models only solve 46-47% of tasks on the first try. In addition, GPT-4 Turbo generally seems to perform similarly (~62%) to the old models (63-64%) after being given a second chance to correct errors by checking the error output of the test suite.
The tested GPT-4 model is expected to be decommissioned in June 2024.
GPT-4 Turbo probably uses chain-of-thought
In another test, X user Vlad, CEO of KagiHQ, shows the performance of the two models in the PyLLM benchmark. According to the results, GPT-4 Turbo has an accuracy of 87% compared to 52% for GPT-4 and is almost five times faster with 48 versus 10 tokens per second. GPT-4 Turbo is also 30% cheaper in practice. According to Vlad, it could be even cheaper - but the output is on average 2 times more verbose than GPT-4. As a possible explanation for this jump in performance, another user points out that GPT-4 Turbo seems to automatically use chain-of-thought prompting in the background - which would also explain the longer output. But even with CoT, GPT-4's accuracy is only just under 60%.

GPT-4 Turbo vs GPT-4 tests fresh from the oven
GPT-4 Turbo has record accuracy (87% vs 52% of GPT-4 on PyLLMs benchmark), it is almost 5x faster with 48 vs 10 tokens/sec). And it is also 30% cheaper in practice (would be more, but it is 2x wordier in output compared to GPT-4) pic.twitter.com/1fjqKpehrD
— Vlad (@vladquant) November 6, 2023
X user Jeffrey Wang, co-founder of Metaphor Systems, tested the new model on SAT reading tests where the model has to provide answers to text. He found that GPT-4 Turbo made significantly more mistakes than GPT-4.
OpenAI claims GPT4-turbo is “better” than GPT4, but I ran my own tests and don’t think that's true.
I benchmarked on SAT reading, which is a nice human reference for reasoning ability. Took 3 sections (67 questions) from an official 2008-2009 test (2400 scale) and got the… pic.twitter.com/LzIYS3R9ny
— Jeffrey Wang (@wangzjeff) November 7, 2023
OpenAI's lack of transparency could be an opportunity for the competition
So is GPT-4 Turbo "smarter"? There is no clear answer yet - at least not if you take "smarter" to mean "better". However, there is no clear leap in performance yet. The open-ended nature of the term - "smarter" can mean many things, including greater resource efficiency in relation to performance - is a deliberate choice. Altman would probably have said that GPT-4 Turbo is smarter or more powerful than GPT-4 if that were clearly the case.
So the focus of the presentation was on the new "smart" features: GPT-4 Turbo can handle more text, has a JSON mode and more modalities integrated, can call functions more reliably and has more up-to-date knowledge.
In addition, unlike GPT-4, OpenAI has not yet published a model map or benchmarks for GPT-4 Turbo - a trend that began with the last update of GPT-4, whose capabilities were also repeatedly criticized. This lack of transparency means that it is up to the community to figure out which model is best suited for which tasks, and how to control it most accurately. The examples given here are not sufficient for this, due to the small sample size. Things get even more complicated in ChatGPT, where OpenAIs model is interfacing with other systems.
The question of which model is better, and not just 'smarter', therefore remains open - as does whether benchmarks can be used to answer it at all. It is unclear, to say the least, to what extent benchmarks always reflect real-world experience. Nevertheless, it would be desirable for end users if OpenAI were a little more open about the specific improvements and capabilities of the new models so that they can make an informed decision. If OpenAI does not take on this role, competitors such as Google could. The lack of transparency could be an opportunity for Google to use Gemini to highlight clear advantages over OpenAI's offering.