Google researchers make voice a solid smartphone interface

Until now, AI has had a hard time controlling smartphone interfaces. But Google researchers seem to have found a way.
To improve voice-based interaction with mobile user interfaces, researchers at Google Research have been investigating the use of large language models (LLM). Current mobile intelligent assistants are limited in conversational interactions because they cannot answer questions about specific on-screen information.
Researchers have developed a set of techniques for applying LLMs to mobile user interfaces, including an algorithm that converts the user interface to text. These techniques allow developers to quickly prototype and test new voice-based interactions. LLMs lend themselves to contextual prompt learning, where the model is fed a few examples from the target task.
Large language models as an interface for smartphones
Four key tasks were studied in extensive experiments. According to the researchers, the results show that LLMs are competitive for these tasks, requiring only two examples per task.
1. Generate on-screen questions: For example, when presented with a mobile user interface (UI), the language model can generate relevant questions about the UI elements that require user input. According to the study, language models were able to generate questions with near-perfect grammar (4.98/5) that were 92.8 percent relevant to the input fields displayed on the screen.

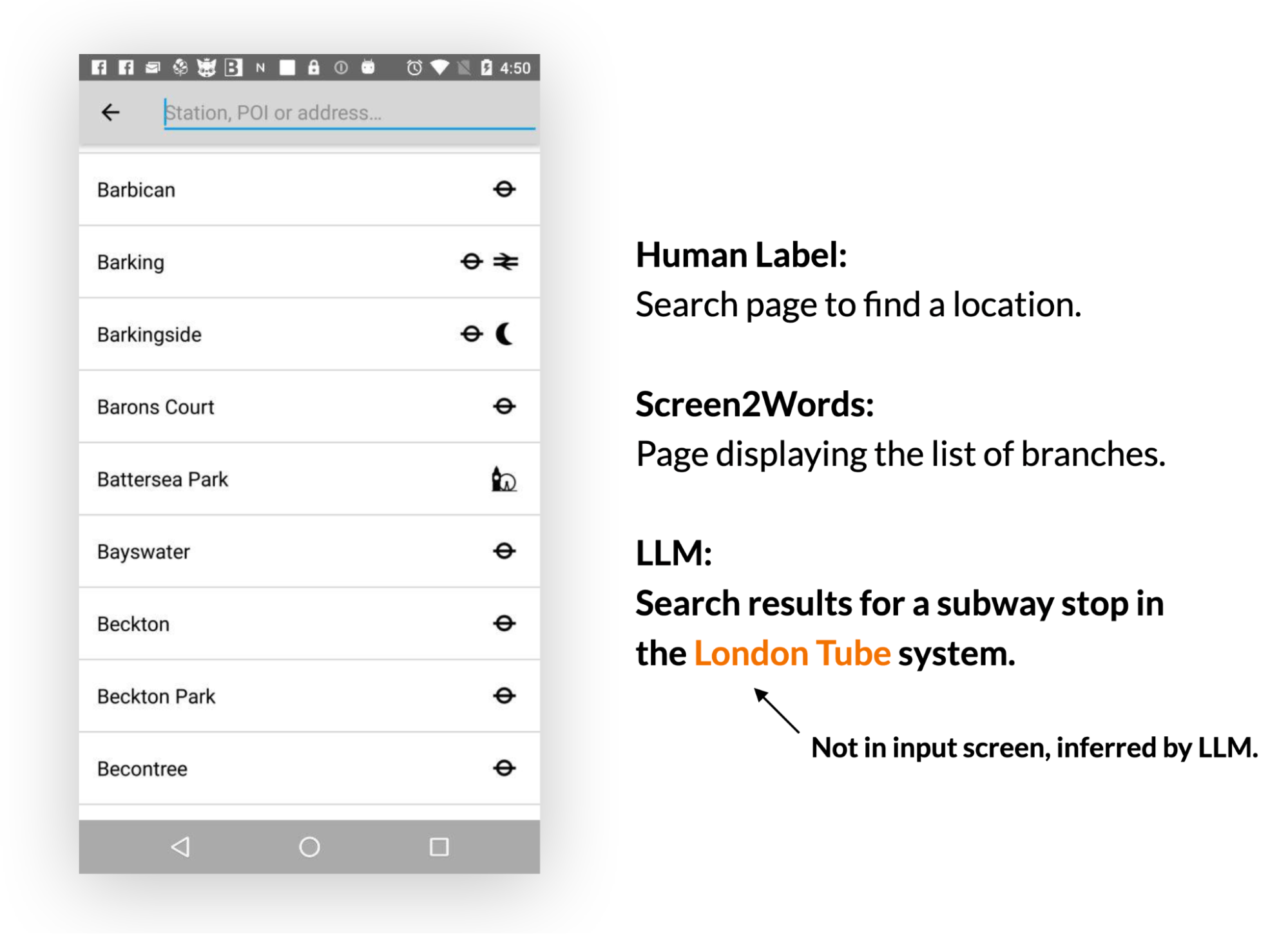
2. Screen summary: LLMs can effectively summarize the main features of a mobile UI. They generate more accurate summaries than the previously introduced Screen2Words model and can even infer information that is not directly presented in the UI.
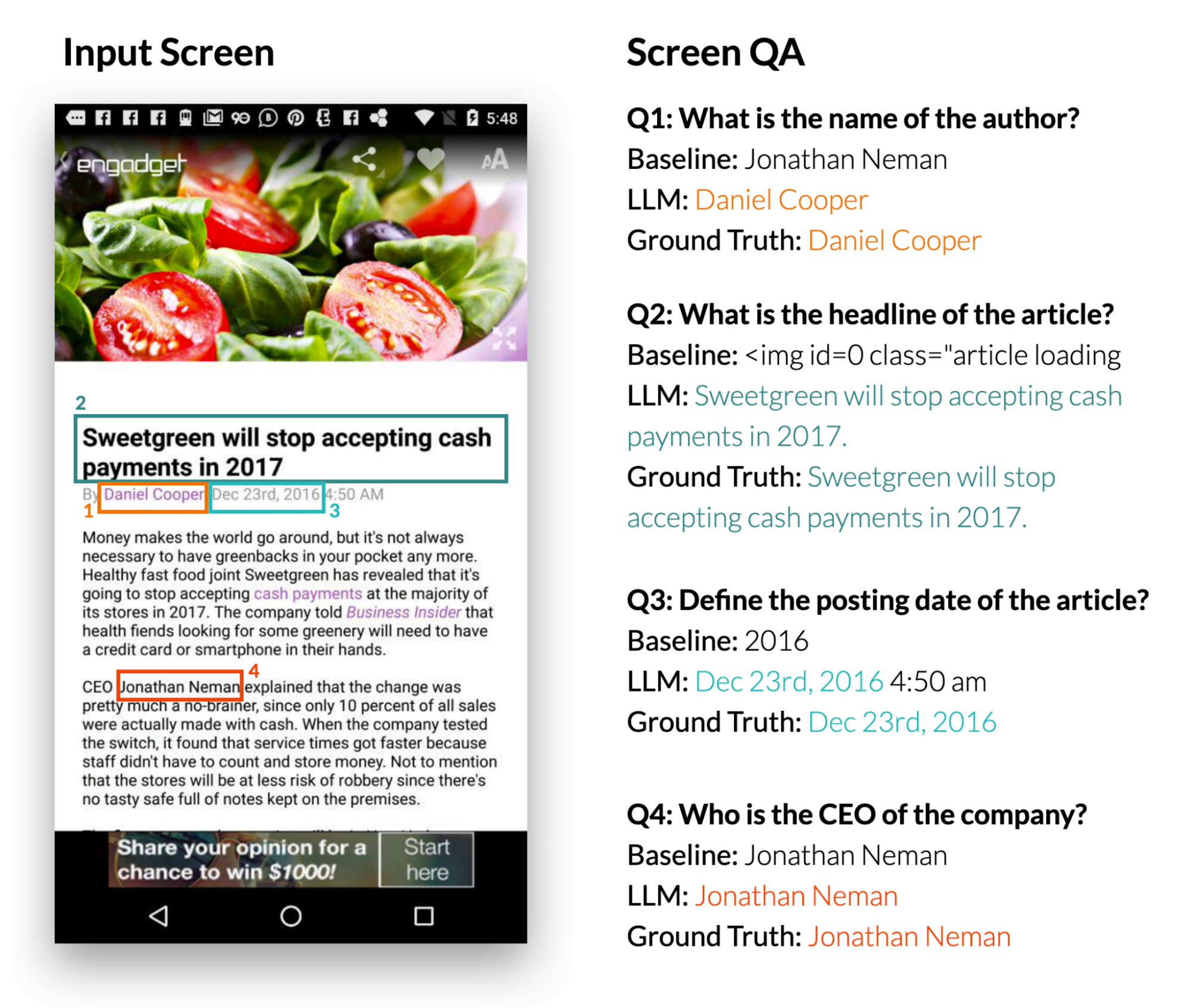
3. Answer on-screen questions: When presented with a mobile UI and an open-ended question that requires information about the UI, LLMs can provide the correct answer. The study shows that LLMs can answer questions such as "What's the headline?" The LLM performed significantly better than the baseline DistilBERT QA model.
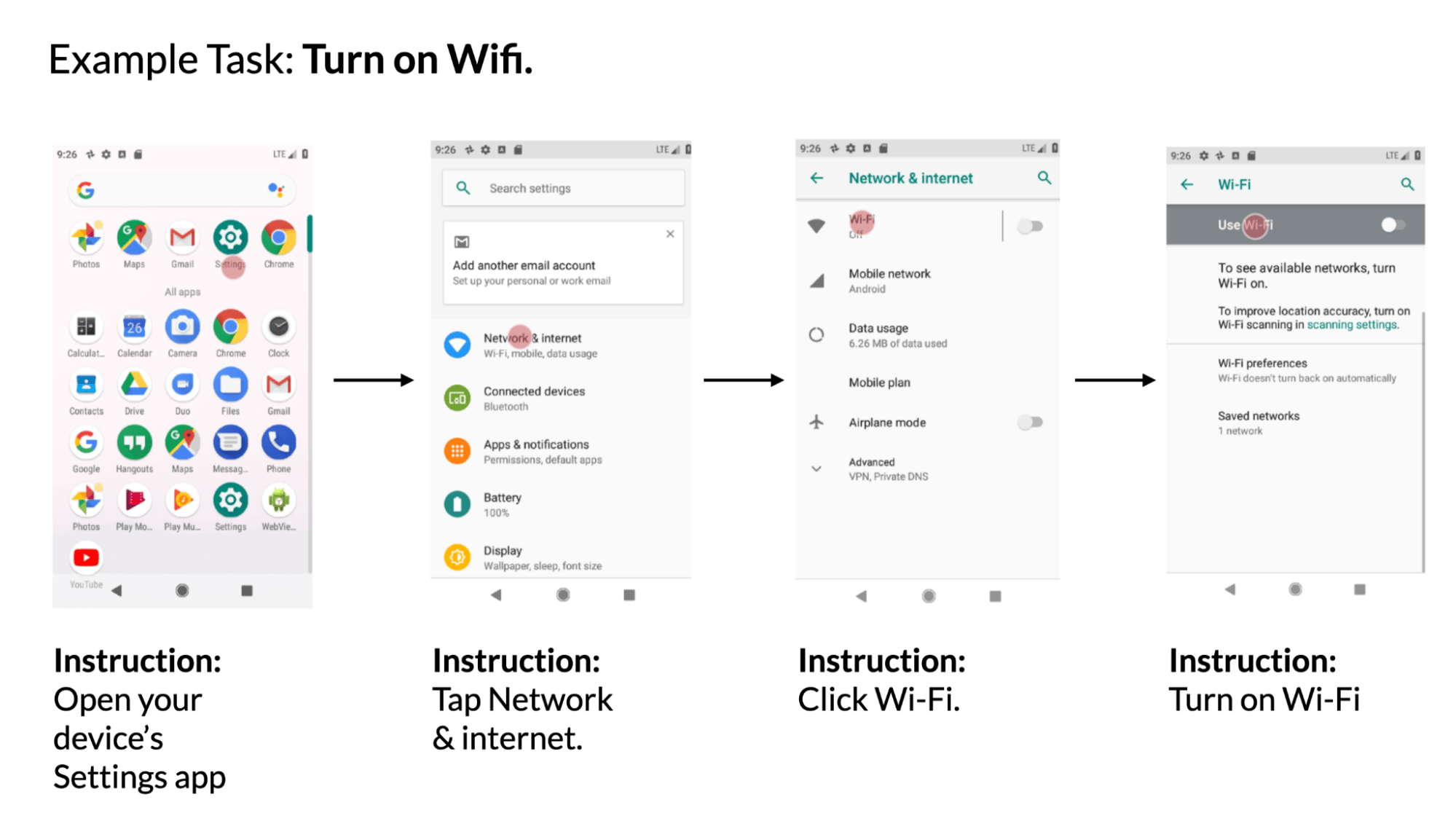
4. Map instructions to UI actions: When given a mobile UI and a natural language instruction to control it, the model can predict the ID of the object for which the given action should be performed. For example, when given the instruction "Open Gmail," the model was able to correctly identify the Gmail icon on the home screen.
The Google researchers conclude that prototyping new voice-based interactions on mobile UIs can be simplified by using LLMs. This opens up new possibilities for designers, developers, and researchers before they invest in developing new databases and models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.