Google shows generative AI model for speech and music

Google's AudioLM uses techniques from large language models to complete spoken sentences, generate new speech - or continue piano music.
Large language models like OpenAI's GPT-3 transform their text input into so-called tokens, which can then be processed by the model and used for text generation, for example.
By relying on tokens, as well as the attention mechanism of the transformer blocks used, the models can process certain syntactic and semantic information.
Text-based models for natural language processing have been so successful that similar approaches are being used in other areas. One of these areas is called "textless NLP" and deals with processing language without text.
One example is Meta's Generative Spoken Language Model (GSLM), which was trained with undocumented audio data. The dGSLM variant, which was introduced in April 2022 and optimized for dialogs, can even imitate laughing or yawning.
Google's AudioLM generates speech and music
Google's AudioLM takes a similar approach to ensure high-quality, long-term coherent audio. To do this, the team uses a number of techniques from the field of language models, including an encoder variant of Google's BERT language model that specializes in audio.
The researchers first construct semantic tokens from raw audio waveforms, which Google says capture local dependencies, such as phonetics of speech or local melody in piano music. They can also process global long-term structure such as language syntax, semantic content, harmony, or rhythm.
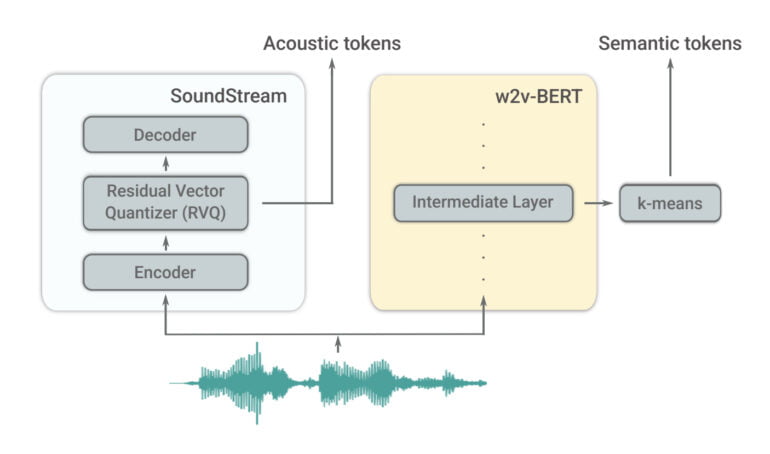
This process is additionally supported by another encoder (SoundStream), which processes acoustic tokens, capturing details of the audio waveform and enabling high-quality synthesis. According to Google, both encoders working together result in high audio quality and long-term consistency. The tokens are then converted to audio by a SoundStream decoder.
AudioLM: Google warns against misuse
Google AudioLM was trained with 60,000 hours of English speech, and another variant was trained with 40,000 hours of piano music. Both models use semantic and acoustic tokens and can continue speech and music of previously unheard speakers and pieces after their training.
Speech - Original
Language - Prompt
Language - Completion
Music - original
Music - prompt
Music - Completion
The model's ability to continue voices and replicate recording conditions at comparatively high quality raises new questions about the future of such AI systems.
AudioLM inherits all the concerns about language models for text, such as reflecting the societal biases in the underlying data, the researchers said.
Furthermore, the "ability to continue short speech segments while maintaining speaker identity and prosody can potentially lead to malicious use-cases such as spoofing biometric identification or impersonating a specific speaker.," the paper states.
Google has therefore trained another AI model, that can reliably recognize audio snippets synthesized by AudioLM. The AudioML model is not yet available.
More examples and comparisons with different variants are available on the AudioLM project page.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.