Google unveils MedGemma, an open-source AI model suite for medical applications

Google Research and DeepMind have released MedGemma, an open-source collection of AI models built specifically for medical use.
The MedGemma family includes a 4B model that can handle text, images, or both, along with a larger 27B version in text-only and multimodal formats. Google introduced the collection at this year's I/O conference.
MedGemma is designed for a variety of medical fields, including radiology, dermatology, histopathology, and ophthalmology. According to Google, the models can serve as a foundation for new healthcare AI tools and work either independently or within agent-based systems.
MedGemma delivers gains over standard models
The technical report indicates that MedGemma delivers substantial improvements compared to similarly sized foundation models. On specialized medical tasks, the models deliver up to 10 percent higher accuracy in multimodal Q&A, 15.5 to 18.1 percent better results for X-ray classification, and a 10.8 percent boost in complex, agent-based evaluations.
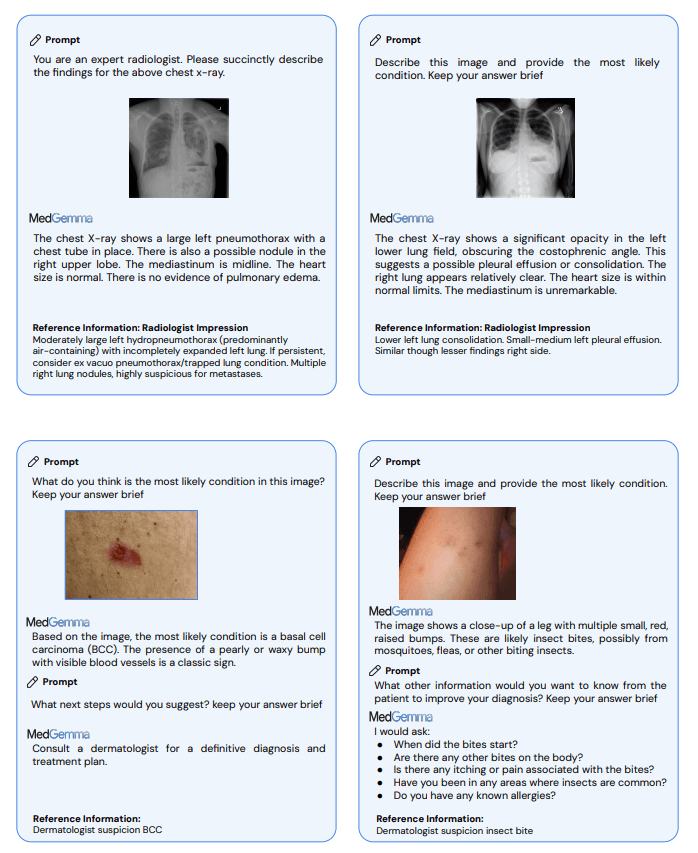
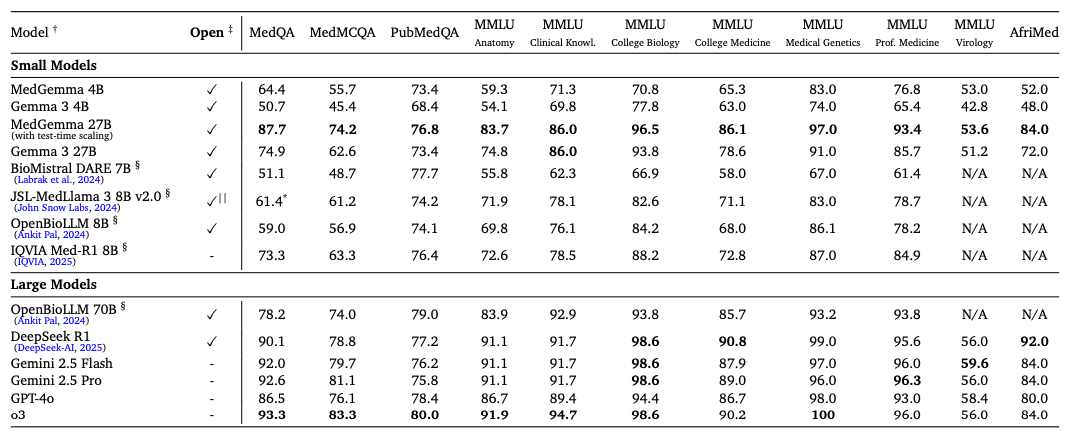
Benchmark scores bear this out. On MedQA, which tests medical exam questions, the 4B model reaches 64.4 percent accuracy, compared to 50.7 percent for the baseline. The 27B version scores 87.7 percent, up from 74.9 percent.
MedGemma also outperforms its base model on medical benchmarks. In testing on the MIMIC-CXR dataset of X-ray images and reports, the 4B version posted a macro F1 score of 88.9, compared to 81.2 for the original Gemma 3 4B model. The F1 score tracks accuracy across different medical conditions.
MedSigLIP: Specialized image encoder
For image processing, Google is introducing MedSigLIP, a medical image encoder with 400 million parameters. MedSigLIP builds on SigLIP ("Sigmoid Loss for Language Image Pre-training"), a system designed to link images with text. The medical version extends this, allowing MedGemma to interpret medical images more effectively.
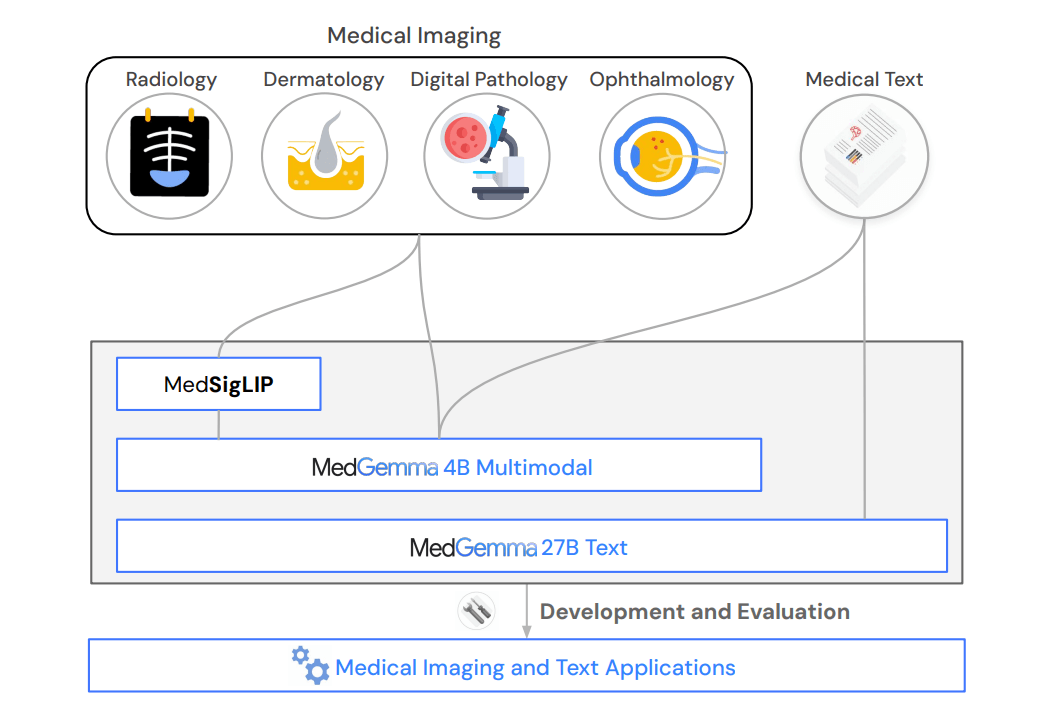
MedSigLIP processes medical images as MedGemma 27B interprets clinical text, making them a powerful multimodal system for healthcare. The encoder works at a 448 x 448 pixel resolution, which is more efficient than the higher-res 896 x 896 variant used in MedGemma.
The model was trained on over 33 million image-text pairs, including 635,000 examples from different medical domains and 32.6 million histopathology patches. To preserve SigLIP’s general image recognition, the original dataset was kept and medical data made up 2 percent of the total, letting the encoder handle both general and medical content.
Fine-tuning for real-world medical tasks
Researchers showed how MedGemma can be fine-tuned for specific medical tasks. For automated X-ray report generation, the RadGraph F1 score improved from 29.5 to 30.3, indicating better capture of essential clinical information. For pneumothorax (collapsed lung) detection, accuracy jumped from 59.7 to 71.5. In histopathology, the weighted F1 score for tissue classification rose from 32.8 to 94.5.
Video: Google
A major leap came in electronic health record analysis: reinforcement learning cut the error rate in data retrieval by half, promising new efficiencies in handling patient data.
MedGemma is available on Hugging Face. The license permits research, development, and general AI uses, but not direct medical diagnosis or treatment without regulatory approval. Commercial use is allowed as long as the restrictions are followed.
Benchmarks aren't the same as the real world
Last year, Google launched a medical AI model built on its closed Gemini platform. MedGemma’s open-source foundation and support for customization could encourage broader adoption.
Still, strong benchmark results don’t always translate into clinical practice. One study found that real-world effectiveness can be limited by misunderstandings or incorrect user interactions, highlighting the gap between test scores and practical results.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.