Google's fastest and cheapest model Gemini 3.1 Flash-Lite got smarter but also tripled the price
Google Deepmind has released a preview of Gemini 3.1 Flash-Lite, the fastest and most affordable model in the Gemini 3 series.
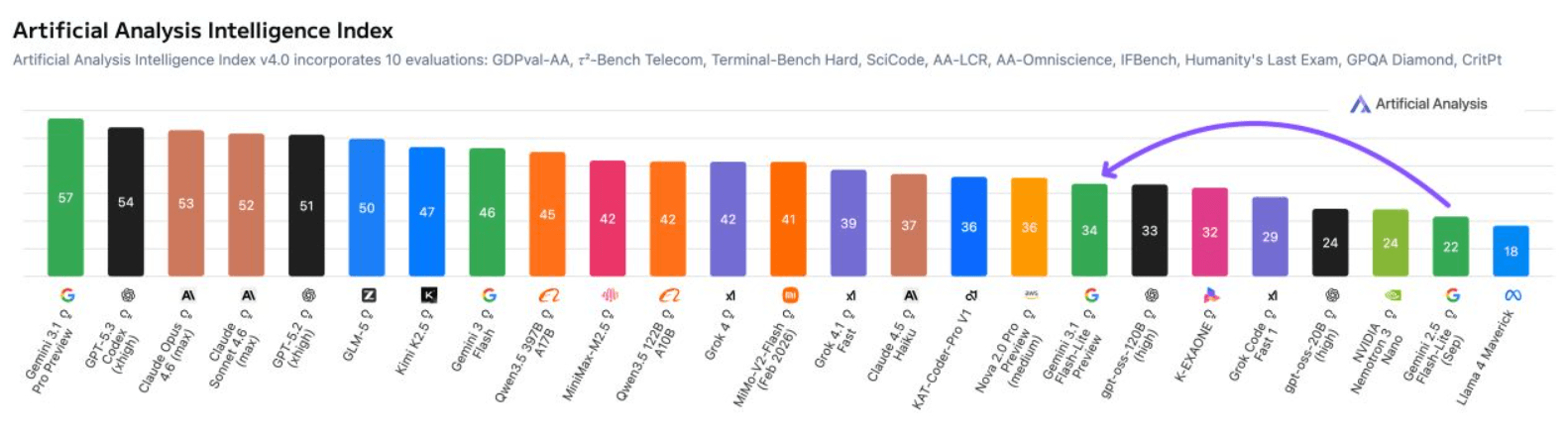
According to Artificial Analysis, the model scores 34 points on their Intelligence Index, a 12-point jump over its predecessor, Gemini 2.5 Flash-Lite. Despite the big leap in capability, it keeps up the same speed as the previous version, cranking out more than 360 tokens per second with an average response time of 5.1 seconds.
On multimodal tasks, it beats top-tier models like Claude Opus 4.6 and Kimi K2.5, hitting 78 percent on the MMMU-Pro benchmark. Artificial Analysis notes that tool usage barely improved. The context window stays at one million tokens.
On the Arena.ai leaderboard, which ranks models based on human preferences in blind comparisons, Gemini 3.1 Flash-Lite lands an Elo score of 1432. It outperforms other models in its weight class on reasoning and multimodal understanding, pulling 86.9 percent on GPQA Diamond (scientific knowledge) and 76.8 percent on MMMU Pro (multimodal understanding and reasoning). Those numbers top even larger previous-generation Gemini models, including 2.5 Flash.
Google says the model also delivers its first response token 2.5 times faster and pushes output 45 percent faster than Gemini 2.5 Flash (not 2.5 Flash-Lite; Flash is a larger model). Developers can dial how much the model "thinks," so it works for simple high-volume jobs like translations as well as heavier lifts like building user interfaces, according to Google.
The speed and quality gains come at a cost. Output pricing has more than tripled: Gemini 3.1 Flash-Lite charges $0.25 per million input tokens (up from $0.10 on the 2.5 version) and $1.50 per million output tokens (up from $0.40).
| Benchmark | Details of | Gemini 3.1 Flash-Lite (High) | Gemini 2.5 Flash (Dynamic) | Gemini 2.5 Flash-Lite (Dynamic) | GPT-5 mini (High) | Claude 4.5 Haiku (Extended Thinking) | Grok 4.1 Fast (Reasoning) |
|---|---|---|---|---|---|---|---|
| Input price ($/1M tokens, no caching) | Lower is better | $0.25 | $0.30 | $0.10 | $0.25 | $1.00 | $0.20 |
| Output price ($/1M tokens) | Lower is better | $1.50 | $2.50 | $0.40 | $2.00 | $5.00 | $0.50 |
| Output speed (Tokens/s) | 363 | 249 | 366 | 71 | 108 | 145 | |
| Humanity's Last Exam (Academic reasoning, full set, text + MM) | No tools | 16.0% | 11.0% | 6.9% | 16.7% | 9.7% | 17.6% |
| GPQA Diamond (Scientific knowledge) | No tools | 86.9% | 82.8% | 66.7% | 82.3% | 73.0% | 84.3% |
| MMMU-Pro (Multimodal understanding and reasoning) | No tools | 76.8% | 66.7% | 51.0% | 74.1% | 58.0% | 63.0% |
| CharXiv Reasoning (Information synthesis from complex charts) | 73.2% | 63.7% | 55.5% | 75.5% (+ python) | 61.7% | 31.6% | |
| Video-MMMU (Knowledge acquisition from videos) | 84.8% | 79.2% | 60.7% | 82.5% | - | 74.6% | |
| SimpleQA Verified (Parametric knowledge) | 43.3% | 28.1% | 11.5% | 9.5% | 5.5% | 19.5% | |
| FACTS Benchmark Suite (Factuality across grounding, parametric, search, and MM) | 40.6% | 50.4% | 17.9% | 33.7% | 18.6% | 42.1% | |
| MMMLU (Multilingual Q&A) | 88.9% | 86.6% | 84.5% | 84.9% | 83.0% | 86.8% | |
| LiveCodeBench (Code generation, UI: 1/1/2025-5/1/2025) | 72.0% | 62.6% | 34.3% | 80.4% | 53.2% | 76.5% | |
| MRCR v2 (8-needle) (Long context performance) | 128k (average) | 60.1% | 54.3% | 30.6% | 52.5% | 35.3% | 54.6% |
| 1M (pointwise) | 12.3% | 21.0% | 5.4% | Not Supported | Not Supported | 6.1% |
The model is available for testing in Google AI Studio and Vertex AI. Full benchmark results are up on Artificial Analysis and the Arena.ai Leaderboard.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now