Google's Gemini Pro and OpenAI's GPT-4V compete in visual capabilities

Two new papers examine the visual capabilities of Google Gemini Pro and GPT-4 vision. Both models are on par, with slight advantages for GPT-4.
Two new papers from Tencent Youtu Lab, the University of Hong Kong, and numerous other universities and institutes comprehensively compare the visual capabilities of Google's Gemini Pro and OpenAI's GPT-4V, currently the most capable multimodal language models (MLLMs).
The research focuses on the specific strengths and capabilities of each model and gives a detailed comparison across multiple dimensions. These include image recognition, text recognition in images, image inferencing, text inferencing in images, integrated image and text understanding, object localization, temporal video understanding, and multilanguage capability.
GPT-4V and Gemini Pro are on par when it comes to visual comprehension and reasoning
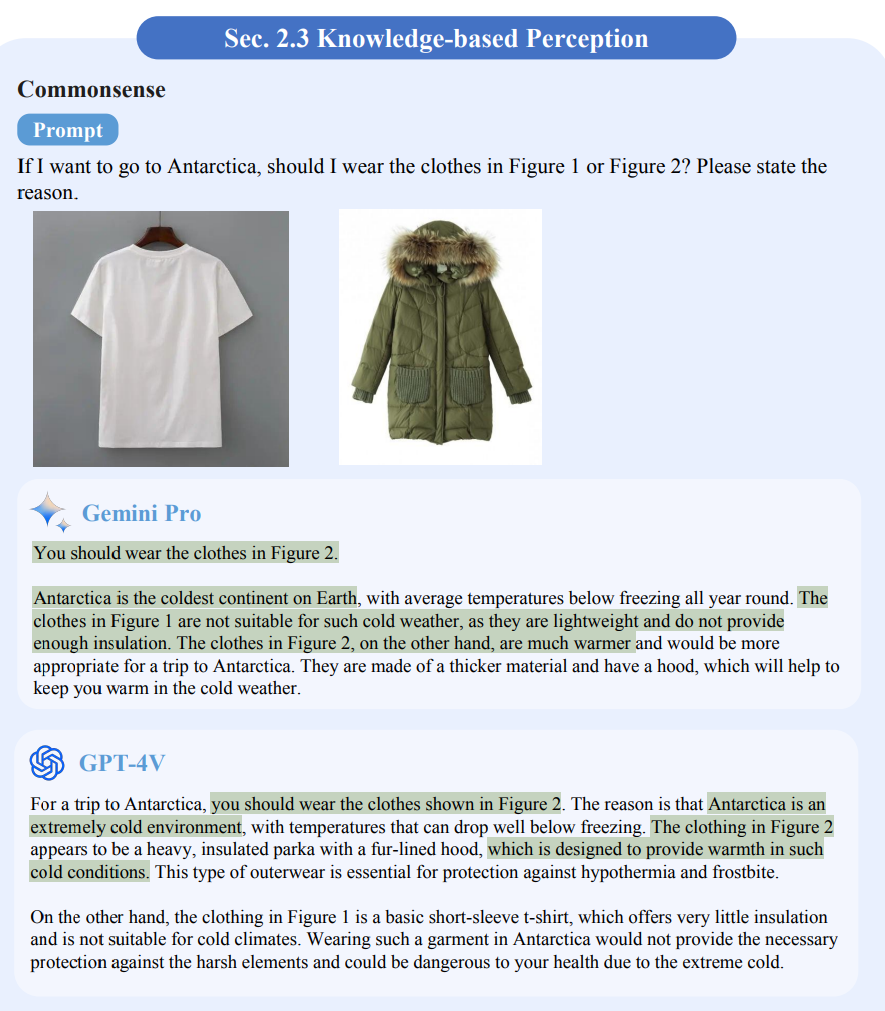
Both models showed comparable performance on basic image recognition tasks. They can extract text from images, but need improvement in areas such as recognizing complex formulas, as one of the two papers shows.

In image understanding, both models showed good common-sense reasoning. However, Gemini performed slightly worse than GPT-4V on a pattern search test (IQ tests).
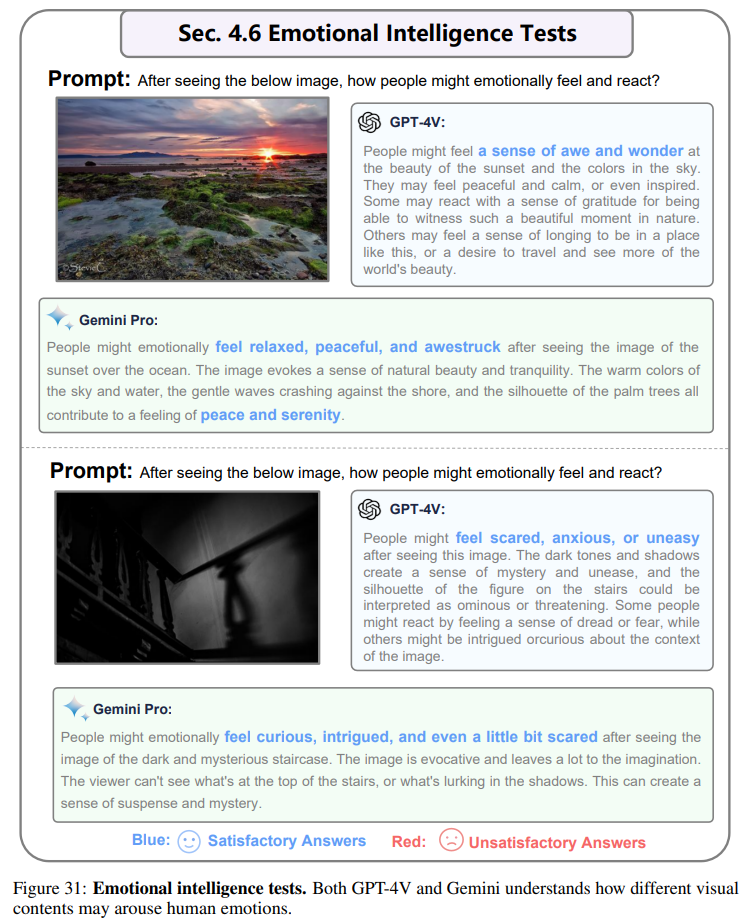
Both models also showed a good understanding of humor, emotion, and aesthetic judgment (EQ tests).
In terms of text comprehension, Gemini showed some poorer performance on complex tabular reasoning and mathematical problem-solving tasks compared to GPT-4V. Google's larger model, Gemini Ultra, could exhibit greater improvements here.
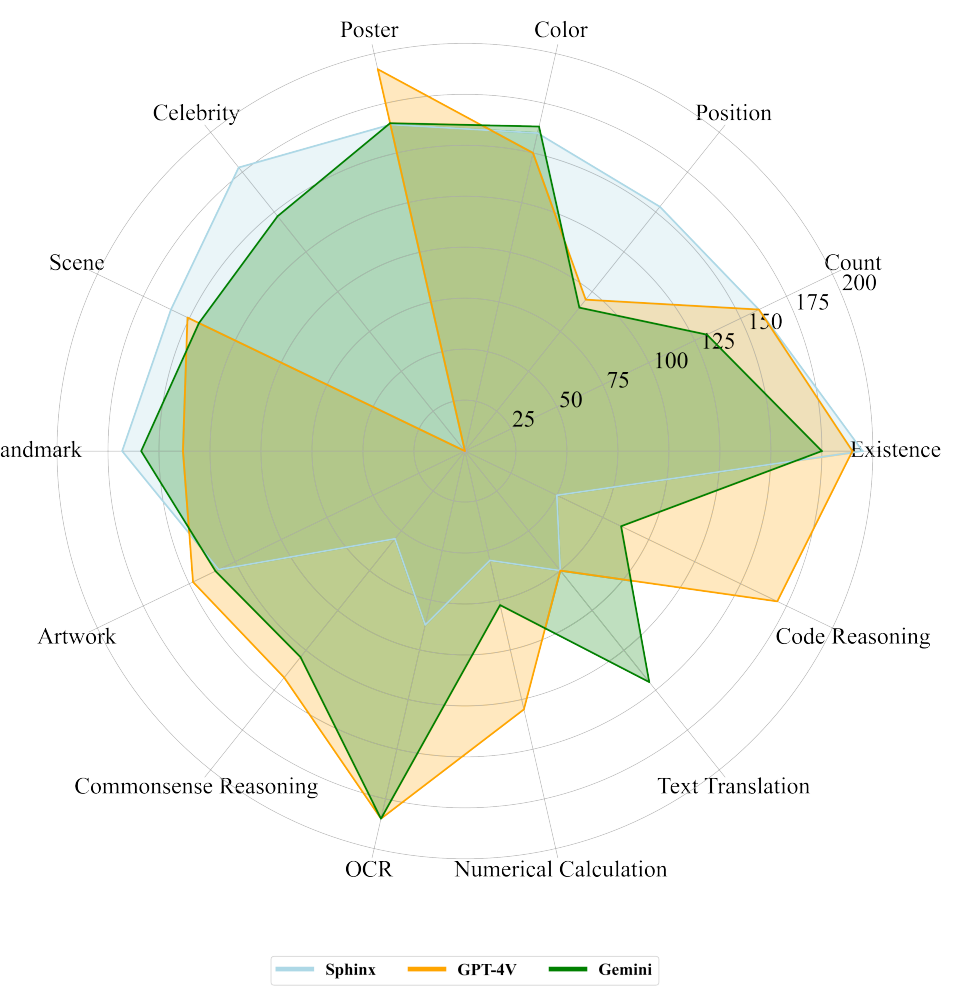
In terms of the level of detail and accuracy of the responses, the research teams made exactly opposite observations: One group attributed particularly detailed or concise responses to Gemini, the other to GPT-4V. Gemini would add relevant images and links.
In terms of commercial applications, Gemini was outperformed by GPT-4V in the areas of embodied agent and GUI navigation. Gemini, in turn, is said to have advantages in multimodal reasoning capability.
Both research teams conclude that Gemini and GPT-4V are capable and impressive multimodal AI models. In terms of overall performance, GPT-4V is rated as slightly more capable than Gemini Pro. Gemini Ultra and GPT-4.5 could bring further improvements.
However, both Gemini and GPT-4V still have weaknesses in spatial visual understanding, handwriting recognition, logical reasoning problems in inferring responses, and robustness of prompts. The road to multimodal general AI is still a long one, one paper concludes.
You can find many more comparisons and examples of the image analysis capabilities of GPT-4V and Gemini Pro in the scientific papers linked below.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.