
Google's latest image AI Parti generates images from particularly comprehensive descriptions. This allows the results to be controlled even more precisely.
Recently, Google introduced Imagen, an image AI that uses a similar architecture (diffusion) to Open AI's DALL-E 2 to generate images, but applies a large AI language model for input - and can generate better images from text descriptions thanks to its higher level of language understanding.
The new Parti (Pathways Autoregressive Text-to-Image) AI model, now unveiled by Google, is testing an alternative architecture (autoregressive) that is even closer to the function of large language models for translation, for example. These language models predict appropriate new words based on previous words and in the context of the sentence or paragraph. Parti applies this principle to images - successfully.
Parti scales - and has world knowledge, according to Google
This is because, like many large language models, Parti shows that it achieves significantly better results with more extensive training that leads to more parameters. Simply put, the AI model scales - and very much so. It can also precisely convert particularly long, complex text inputs into images, which speaks to an even better understanding of the connection between language and motifs.
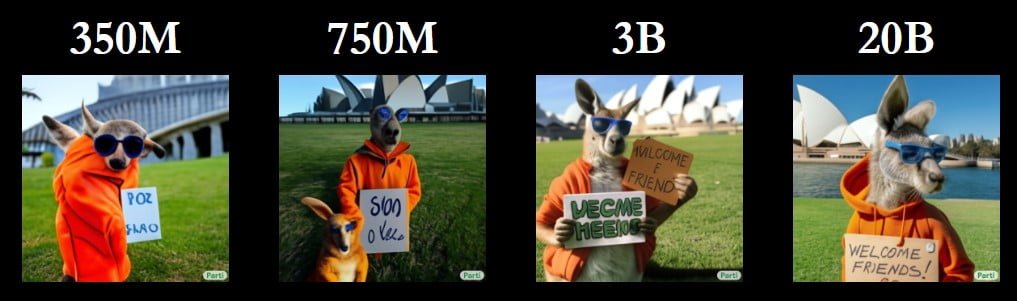
The image above shows the difference in quality at the same prompt for four Parti models trained to different degrees. The largest model with 20 billion parameters produces the most error-free image corresponding to the extensive text input. Unlike DALL-E 2, Parti in its largest version can even spell words correctly ("Welcome Friends").
"The 20B model especially excels at prompts that are abstract, require world knowledge, specific perspectives, or writing and symbol rendering," Google's research team writes.
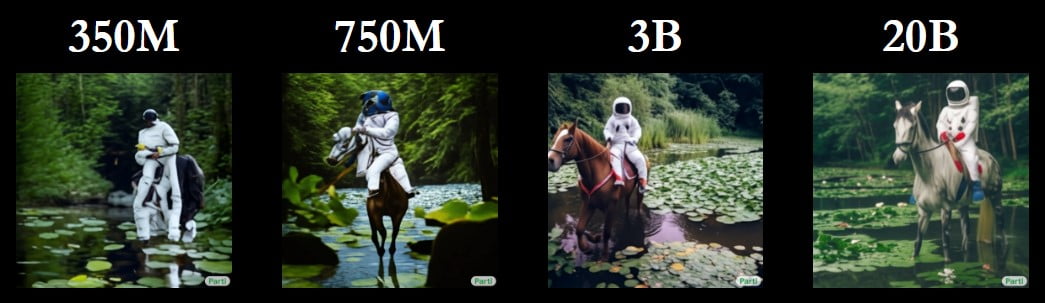
Human testers preferred the output of the largest model over the three-billion model about 63 percent of the time. In about 76 percent of the cases, they attributed the 20-billion model to generate more suitable images for the input text.

Parti generates all images with a resolution of 256 x 256 pixels and then uses an upscaler to bring them to 1024 x 1024 pixels.
Parti can't count either
Parti can also generate fantastic images of subjects that were not part of the training material and that do not exist. The researchers credit the image AI with the ability to accurately reflect world knowledge, compose many protagonists and objects with fine details and interactions, and adhere to a specific image format and style.

Nevertheless, the system still has numerous problems, for example in the representation of proportions or in the differentiation and - like DALL-E 2 - counting of objects within an image.
With the text input "Two baseballs to the left of three tennis balls" the system generates two tennis balls and to the right of them another tennis ball with the seams of a baseball. In addition, there are technical errors such as color bleeding.

The research team has concerns that Parti represents biases and stereotypes, an issue that Imagen and DALL-E 2 also struggle with. For example, stereotypes about typical male and female occupations are amplified. Moreover, according to the researchers, there is an additional deepfake risk due to the possible photorealistic generation of people.
For this reason, the researchers are refraining from publishing the model, code and other data for now. The team plans to continue working on the problems.
Is Parti Google's Image AI for Pathways?
The name is interesting, too: The P in Parti stands for Pathways, Google's next-generation AI architecture first unveiled by Google's AI chief Jeff Dean in late 2021.
The goal of Pathways is an intelligent AI multipurpose system that can one day "generalize across millions of tasks." The fact that Parti has Pathway in its name could indicate that it will take on the role of image generation in this future architecture. According to the Google research team, combinations of the Parti and Imagen architectures are also worth a try.
The team shows many additional positive and negative examples of Parti images on an interactive website and explains the structure of the system in detail.




