
Google's MobileDiffusion is a fast and efficient way to create images from text on smartphones.
MobileDiffusion is Google's latest development in text-to-image generation. Designed specifically for smartphones, the diffusion model generates high-quality images from text input in less than a second.
With a model size of only 520 million parameters, it is significantly smaller than models with billions of parameters such as Stable Diffusion and SDXL, making it more suitable for use on mobile devices.
The researchers' tests show that MobileDiffusion can generate images with a resolution of 512 x 512 pixels in about half a second on both Android smartphones and iPhones. The output is continuously updated as you type, as Google's demo video shows.
Video: Google
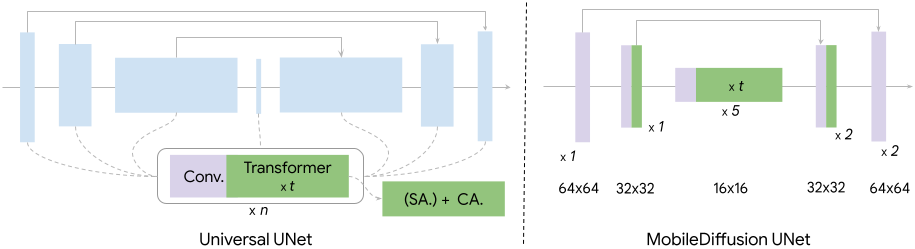
MobileDiffusion consists of three main components: a text encoder, a diffusion network, and an image decoder.
The UNet contains a self-attention layer, a cross-attention layer, and a feed-forward layer, which are crucial for text comprehension in diffusion models.
However, this layered architecture is computationally complex and resource intensive. Google uses a so-called UViT architecture, in which more transformer blocks are placed in a low-dimensional region of the UNet to reduce resource requirements.
In addition, distillation and a Generative Adversarial Network (GAN) hybrid are used for one- to eight-level sampling.

Google has not yet made the model freely available, nor has it announced any plans to do so. Rather, the research should be considered a step toward the goal of democratizing text-to-image generation on mobile devices.
Google has its own family of smartphones with the Pixel series, where generative AI is becoming an increasingly important topic for both hardware and software.
Image generation is getting faster and faster
Last year, Qualcomm demonstrated that a smartphone could quickly generate images based on Stable Diffusion.
By optimizing Qualcomm's AI stack, the U.S. chipmaker was able to run the image generator on what was then a high-end Android smartphone, a remarkable technological advance at the time in February 2023. However, generating an image with 512 x 512 pixels and 20 inference steps still took about 15 seconds.
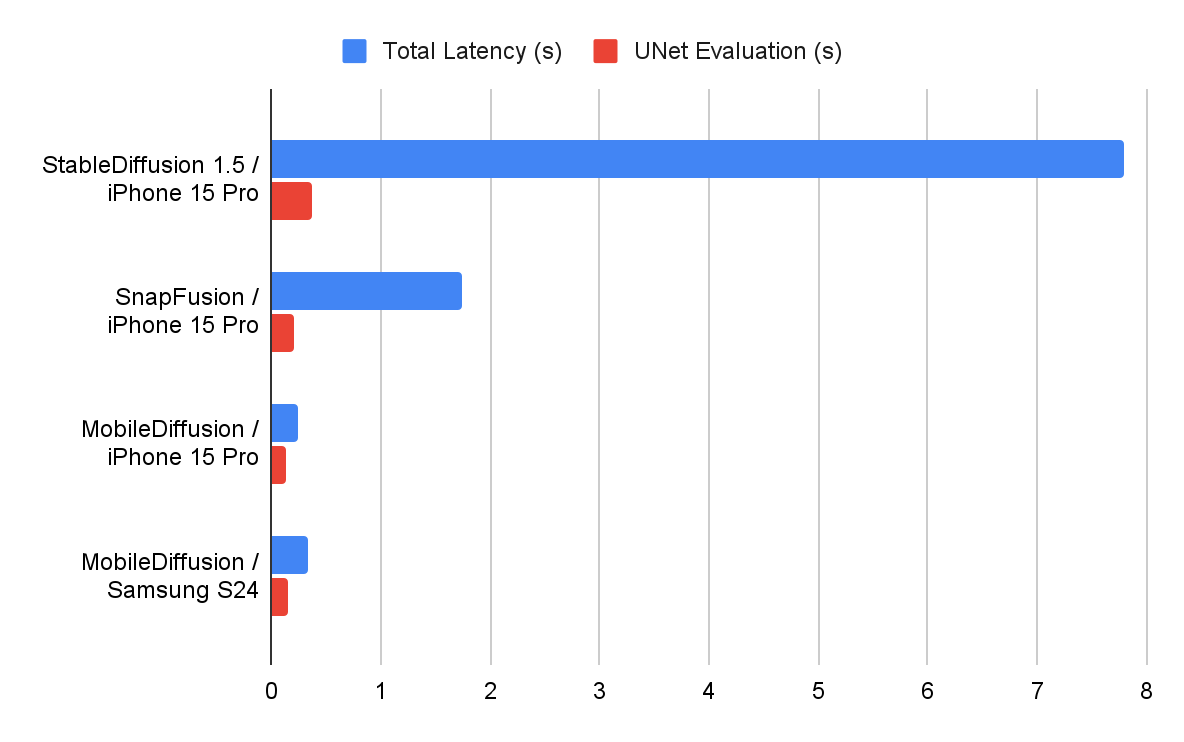
The advantage of Google's MobileDiffusion approach is that it delivers fast results on all systems, regardless of the operating system. It's even better on the iPhone 15 Pro than on Samsung's latest flagship, the Galaxy S24, which runs Google's Android.
More recently, SDXL Turbo or PixArt-δ have also made significant advances in quasi-real-time image generation, albeit on more powerful systems.




