Google's ReCapture lets users change camera angles in existing videos

Google researchers have developed ReCapture, a new AI technique that allows users to modify camera movements in videos after they've been recorded. The system aims to bring professional-grade video editing capabilities to casual users.
Changing camera angles in existing footage has traditionally been challenging. Current methods often struggle to maintain complex movements and details while processing different types of video content.
Rather than using an explicit 4D representation as an intermediate step, ReCapture taps into the motion knowledge stored in generative video models. The researchers reframed the task as video-to-video translation using Stable Video Diffusion.
Video: Zhang et al.
Two-step process combines temporal and spatial layers
ReCapture operates in two phases. First, it creates an "anchor video" – an initial version of the desired output with new camera movements. This preliminary version might contain some temporal inconsistencies and visual artifacts.
To generate the anchor video, the system can use diffusion models like CAT3D, which create videos from multiple angles. Alternatively, it can generate the anchor through frame-by-frame depth estimation and point cloud rendering.
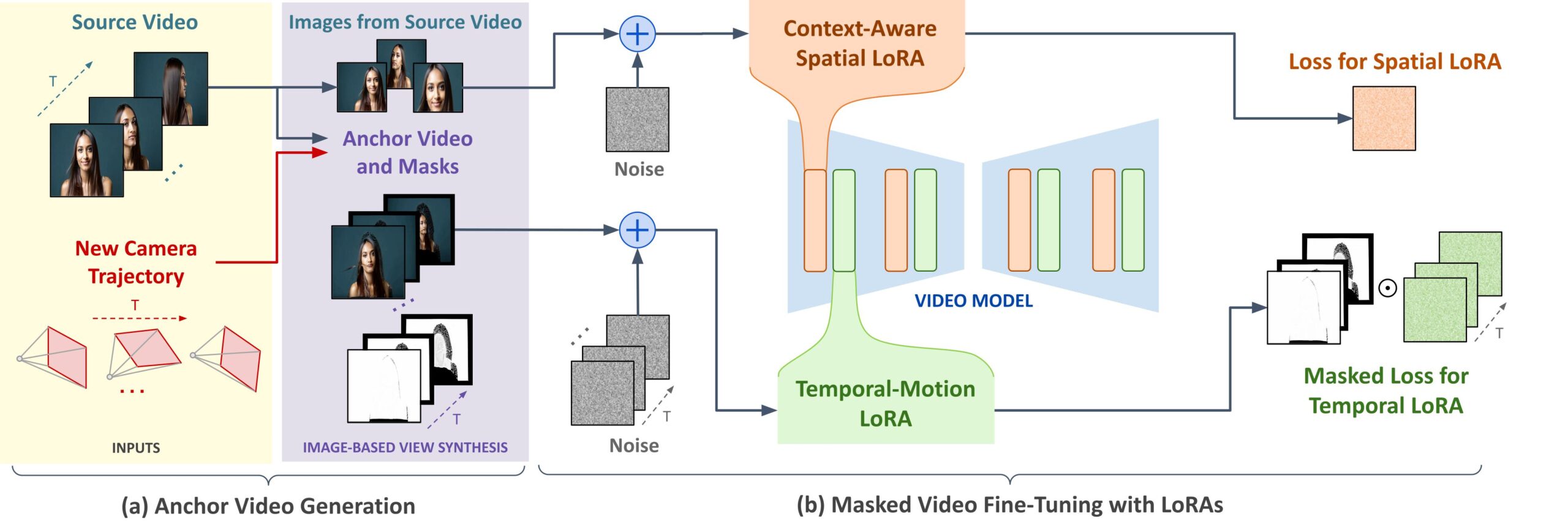
In the second phase, ReCapture applies masked video fine-tuning. This step uses a generative video model trained on existing footage to create realistic movements and temporal changes.
The system incorporates a temporal LoRA (Low-Rank Adaptation) layer to optimize the model for the input video. This layer specifically handles temporal changes, allowing the model to understand and replicate the anchor video's specific dynamics without requiring full model retraining.
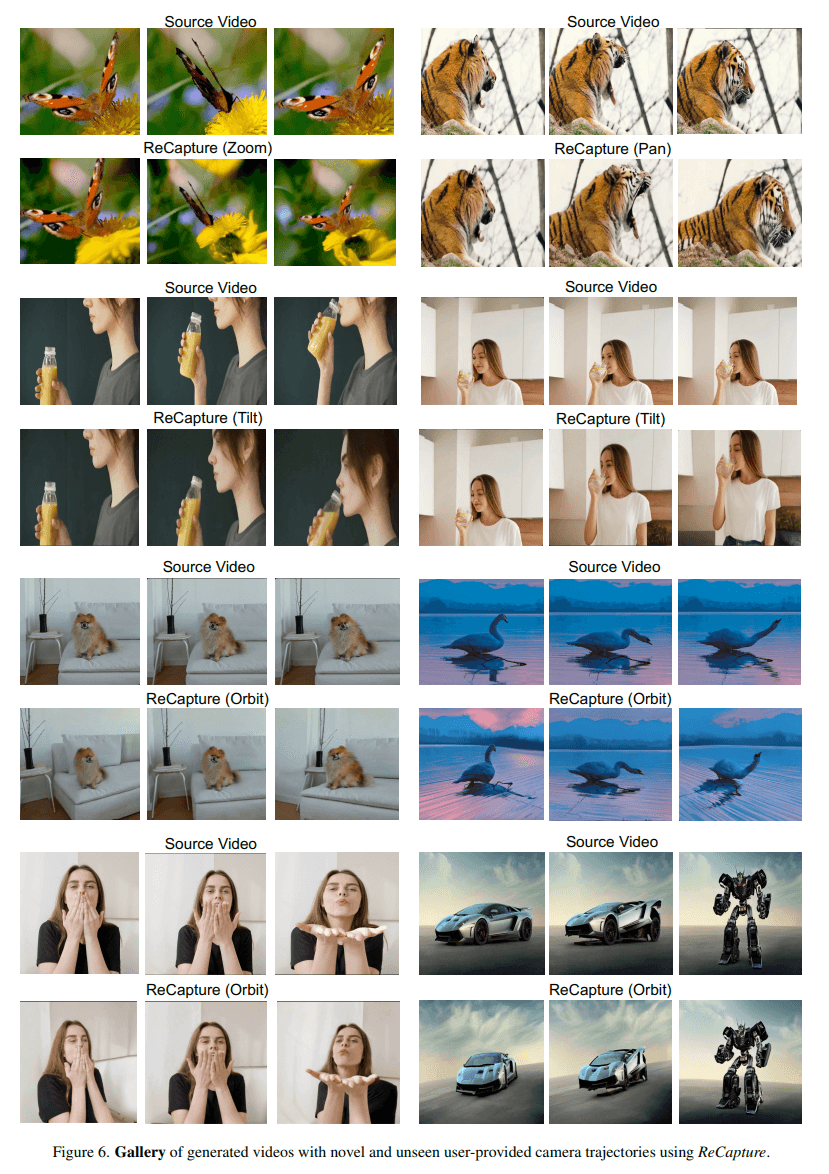
A spatial LoRA layer ensures image details and content remain consistent with the new camera movements. The generative video model can perform zooming, panning, and tilting while maintaining the original video's characteristic movements.
The project website and research paper provide additional technical details, including post-processing techniques like SDEdit to enhance image quality and reduce blur.
Generative AI for video is still experimental
While the researchers see their work as progress toward user-friendly video manipulation, ReCapture remains a research project far from commercial release. Google hasn't yet brought any of its numerous video AI projects to market, though its Veo project might be close.
Meta also recently introduced its Movie-Gen model, but like Google, it's not commercializing it. And let's not get into Sora, OpenAI's video frontier model, which was unveiled earlier this year but hasn't been seen since. Currently, startups like Runway are leading the video AI market, having launched their latest Gen-3 Alpha model last summer.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.