Google's ScreenAI reliably navigates smartphone screens

Google is taking another step on the long road to language and voice-controlled computer interfaces.
Google Research has introduced a new AI model called ScreenAI that can understand user interfaces and infographics.
It sets new benchmarks for various tasks, including answering content questions based on infographics, summarizing them, and navigating through user interfaces.
At the heart of ScreenAI is a new method for textual representation of screenshots, where the model identifies the type and location of UI elements. Using Google LLM PaLM 2-S, the researchers generated synthetic training data for the model to answer questions about on-screen information, on-screen navigation, and summarizing screen content.
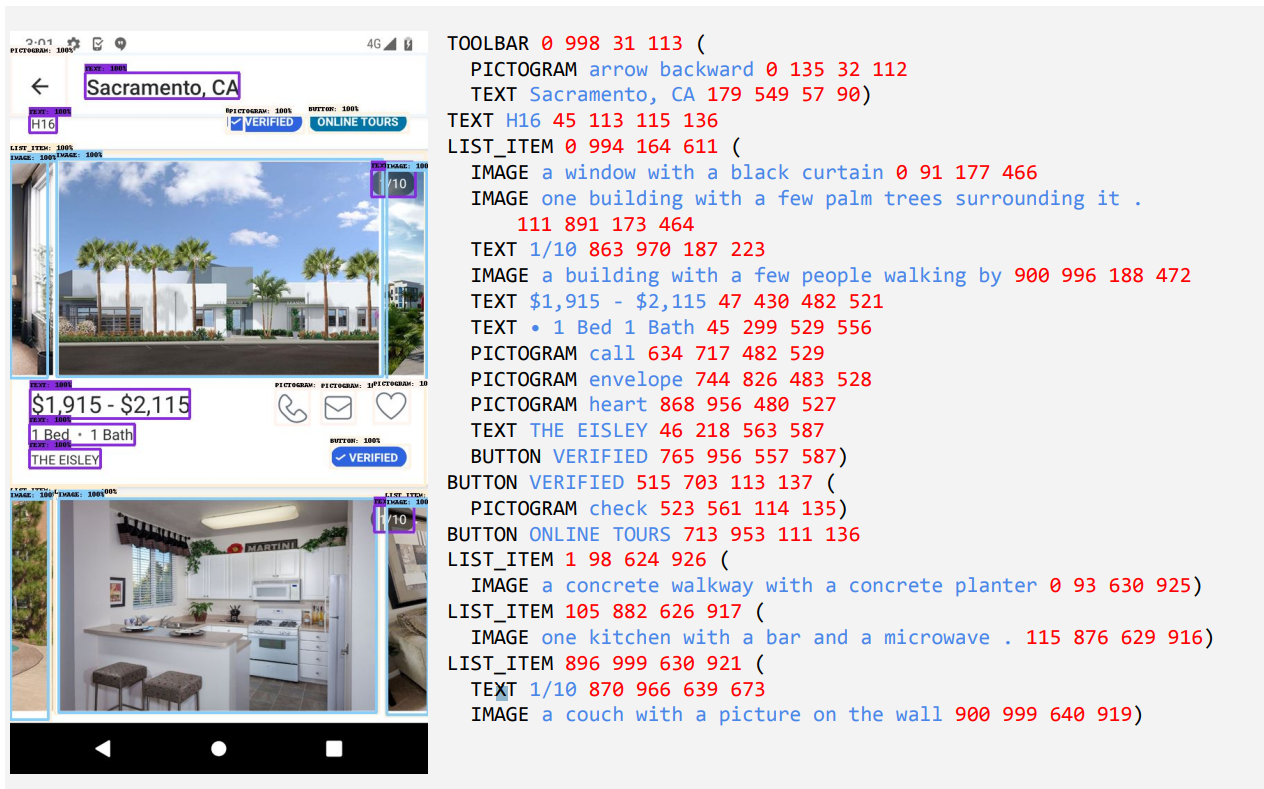
The screen scheme used in the pre-training tasks. | Image: Google ResearchThe model combines previous Google developments such as the PaLI architecture with the flexible patching mechanism of Pix2Struct, which splits a graphic into a variable grid depending on the aspect ratio.
ScreenAI uses an image encoder and a multimodal encoder to process image and text input, followed by an autoregressive decoder to generate text output.

The result is three models with 670 million, two billion, and five billion parameters. The researchers' experiments show that model performance improves as model size increases. This suggests that there is great potential for further performance improvements by scaling the model.
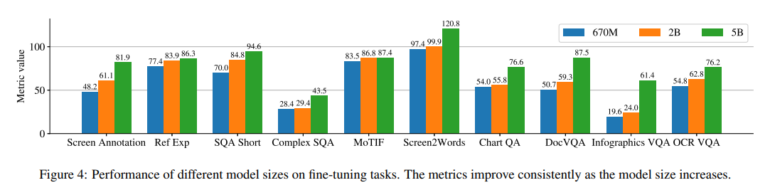
When compared to models of similar size, ScreenAI performs best in all benchmarks and often outperforms larger models. The use of OCR (Optical Character Reconition) to extract textual content from screenshots has a slightly positive impact.
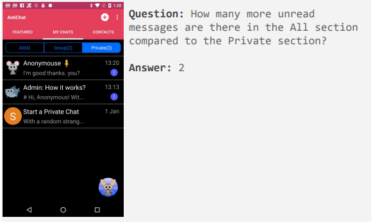
Progress in research, but lack of practical application
While ScreenAI represents a small milestone in improving the understanding of digital content, the part of the model that can actually execute the generated actions is still missing.
Although there are recent language models that run on smartphones, there is a lack of more powerful multimodal models that combine text, images, audio, and video.
Nevertheless, it seems likely that automated handling of smartphones and UX interfaces using natural language alone will become more advanced in the near future, thanks to models like ScreenAI.
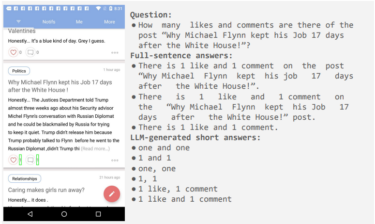
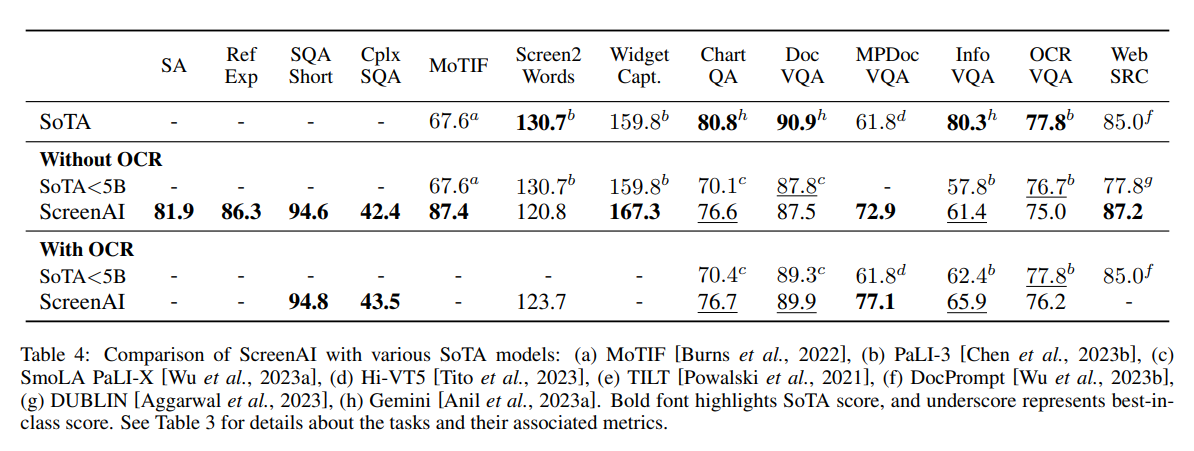
The researchers say their specialized model is the best in its class, but more research is needed on some tasks to close the gap with much larger models such as GPT-4 and Gemini.
To encourage further development, Google Research plans to release evaluation datasets as part of ScreenAI. ScreenQA is already available with a collection of 86,000 question-answer pairs for 36,000 screenshots; a more complex variant and a collection of screenshots and their text descriptions will follow.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.