GPT-4 Code Interpreter smashes maths benchmarks, hits new SOTA

Researchers have achieved a new SOTA on the MATH benchmark with GPT-4 Code Interpreter using new prompting methods.
The team tested OpenAI's latest AI system, GPT-4 Code Interpreter (GPT4-Code), on mathematical reasoning datasets such as MATH. The dataset is recognized as the most challenging mathematical problem set, the researchers said.
They found that GPT4-Code significantly outperformed GPT-4, achieving 69.7% accuracy on MATH compared to GPT-4's 42.2%, and also significantly surpassed the previous state-of-the-art performance of 53.9%.
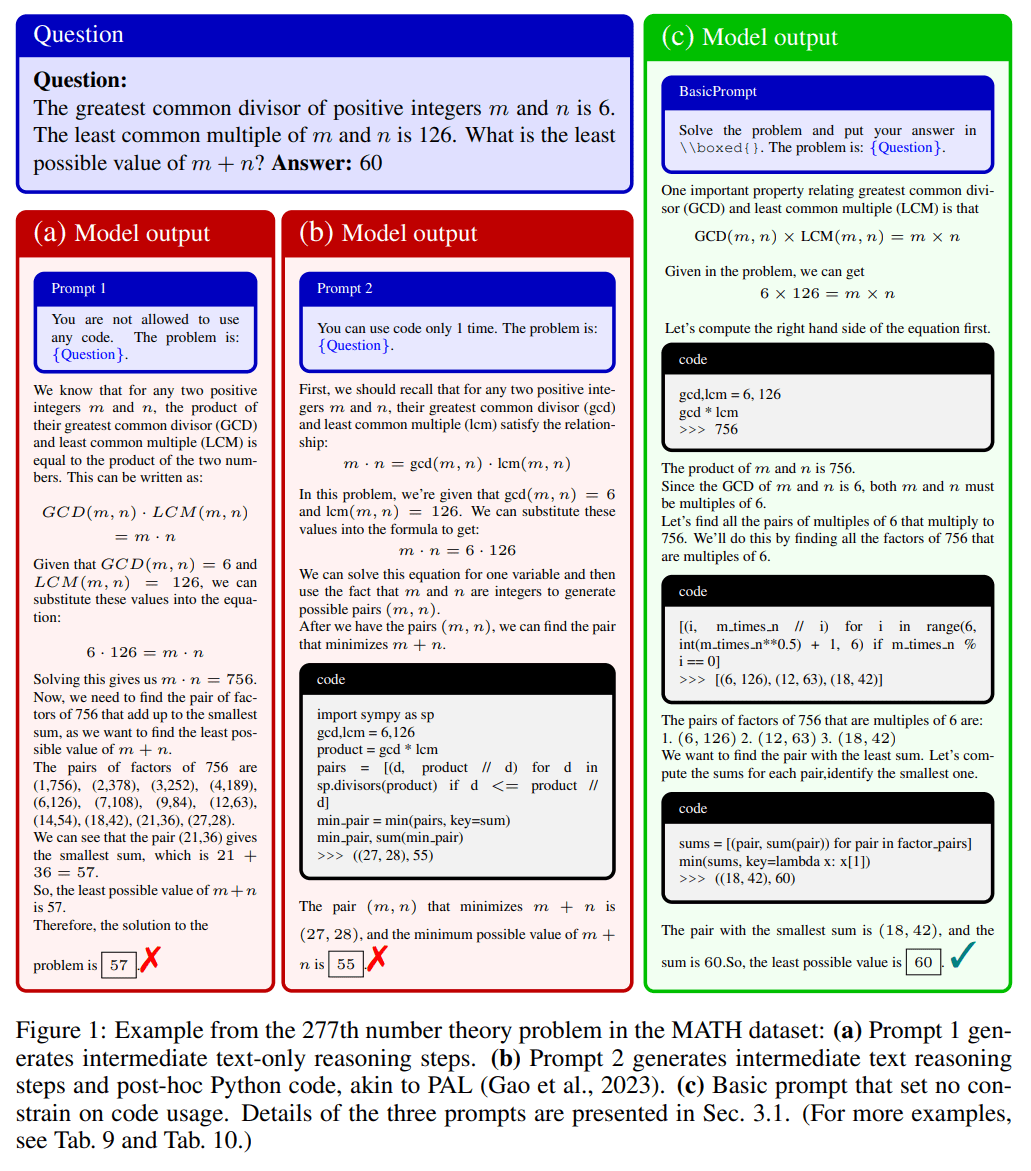
Using different prompts, the team introduced different constraints on the frequency of code usage allowed in the GPT4 Code and found "that its success can be largely attributed to its powerful skills in generating and executing code, evaluating the output of code execution, and rectifying its solution when receiving unreasonable outputs."
Two methods greatly enhance the mathematical capabilities of the GPT-4 Code Interpreter
Based on these findings, the researchers aimed to further improve the GPT4 Code's mathematical capabilities by pushing for more frequent code execution, as this improves performance, especially on harder problems.
They proposed two methods:
- Explicit Code-Based Self-Verification
- This prompts the GPT-4 Code Interpreter to verify its answer with code. If it is wrong, it will keep trying until the verification is successful.
- Verification-Guided Weighted Majority Voting
- This incorporates the verification results into majority voting. Answers verified as true are given higher weights, reflecting greater confidence.
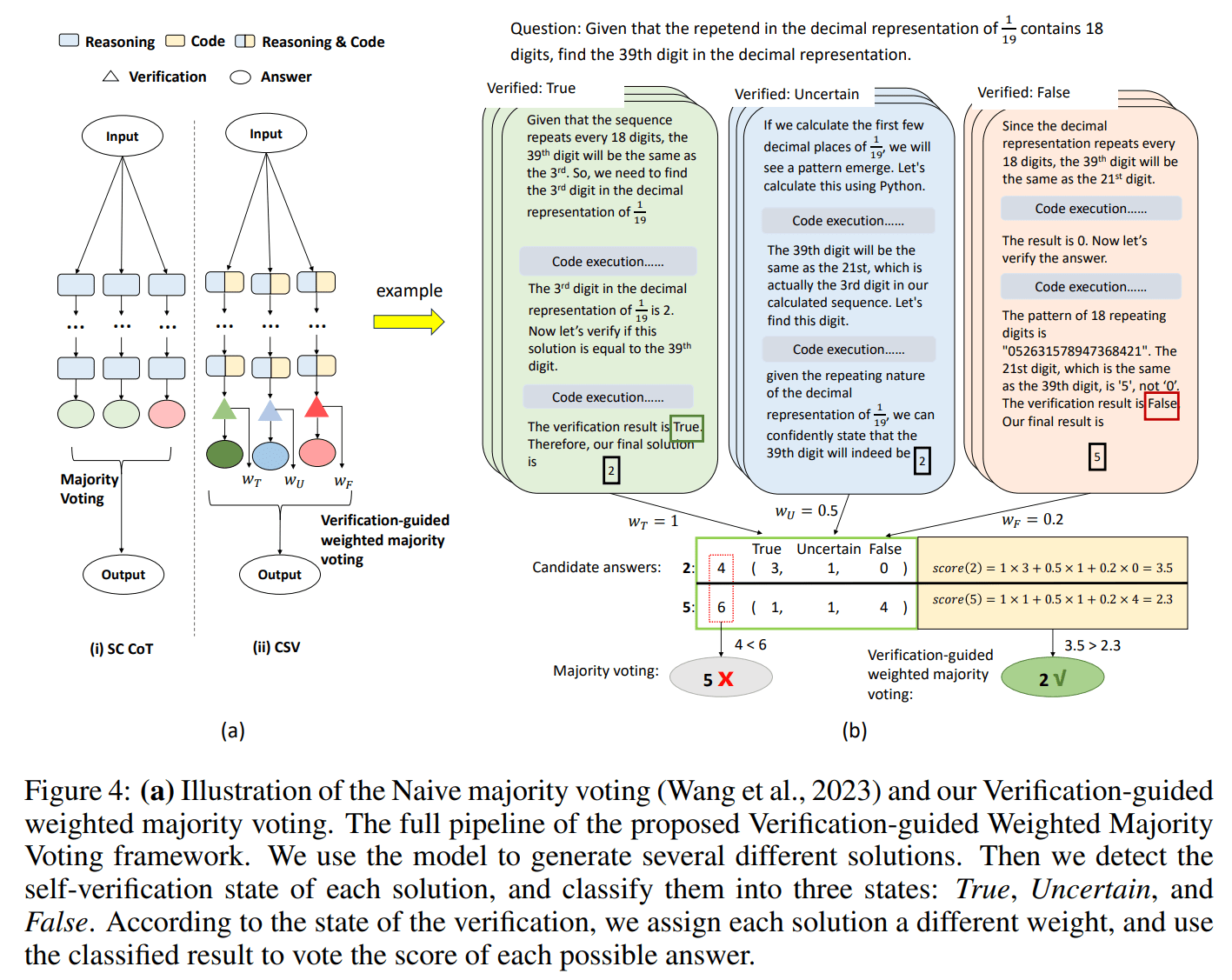
Experiments showed that these methods improved the accuracy of MATH to 84.3%, surpassing the GPT4-Code's 69.7%. The key was exploiting their self-verification capabilities through increased code usage.
Methods could produce more accurate datasets for open-source models such as LLaMA 2
The researchers also evaluated their technique on the MMLU benchmark for math and science problems. Again, it improved the accuracy of the GPT-4 Code Interpreter across all datasets, demonstrating broad applicability.
The team now want to apply their findings on the important role of code usage frequency and their two methods to other LLMs outside GPT-4. They also plan to use them to create more accurate datasets that would include "detailed step-by-step code-based solution generation and code-based validation, which could help improve open-source LLMs like LLaMA 2".
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.