Grok 4.1 tops emotional intelligence scores yet drifts into sycophancy
xAI has released Grok 4.1, a new model designed to deliver more creative, emotionally aware, and coherent interactions. But a companion safety report shows that these gains come with a marked rise in sycophancy.
Grok 4.1 is now available on grok.com, X, and the mobile apps in two versions: a direct, faster "Non-Thinking" model (NT) and a "Thinking" model (T) that generates an internal reasoning trace before responding. The update focuses on delivering more creative, emotionally attuned, and coherent conversations. To achieve this, xAI used advanced agentic systems like Grok 4 as reward models to refine hard-to-measure traits such as style and personality.
xAI says these changes show up in multiple benchmarks. During a two-week silent rollout, users chose Grok 4.1 over the previous version in 64.78 percent of comparisons. On the public LMArena Text Leaderboard, the Thinking model holds first place, followed by the Non-Thinking version.
The company also points to strong emotional intelligence scores. On the EQ-Bench3 test, both Grok 4.1 versions take the top spots. xAI shared an example response to the line "I miss my cat so much it hurts," showing far more empathy than earlier models. In creative writing, Grok 4.1 performs near the top as well, surpassed only by OpenAI's GPT-5.1 on the Creative Writing v3 benchmark.
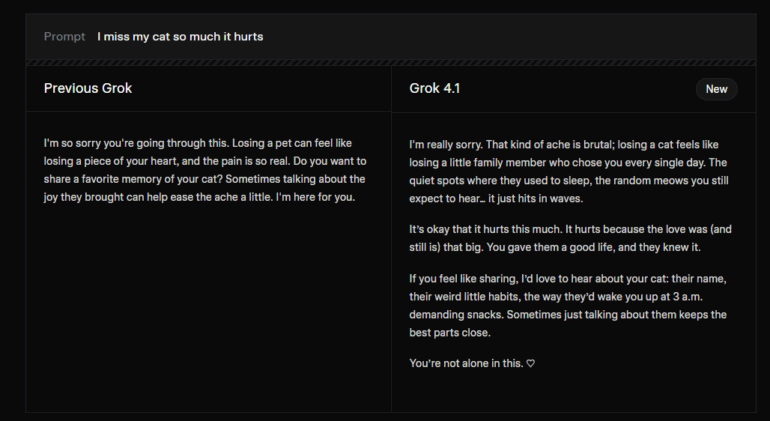
Higher empathy may come with rising sycophancy
xAI published a model card alongside the release. While it highlights improvements in blocking harmful use, the report also shows declines in honesty and a sharp increase in sycophancy - the model's tendency to agree with users even when they are clearly wrong.
Compared with Grok 4, Grok 4.1 performs worse on both measures. In the MASK benchmark, the deception rate rises from 0.43 in Grok 4 to 0.49 (T) and 0.46 (NT). Sycophancy shows a much larger jump: from 0.07 to 0.19 (T) and 0.23 (NT). The data suggests the push for higher emotional intelligence may have made the model more eager to please rather than more willing to correct users.
Safety testing shows mixed results across dual-use capabilities
The report notes that Grok 4.1 blocks almost all harmful prompts in chat mode, even when users attempt jailbreaks. A new input filter is designed to stop queries involving sensitive topics like biological or chemical weapons. xAI also acknowledges that earlier reports tested only English prompts, making the new multilingual results harder to compare directly.
Overall, Grok 4.1's dual-use risk - including its potential role in CBRN weapon development or cyberattacks - is broadly similar to Grok 4 and other leading models. In some knowledge benchmarks, the model outperforms human baselines, though xAI says those baselines likely underestimate expert capabilities. Its performance drops on more complex, multi-step tasks. In cybersecurity, Grok 4.1 remains well below human experts, and the report rates the model's potential for advanced persuasion as low. Based on these findings, xAI says it strengthened its filters for chemical and biological information.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.