Grok 4 edges out GPT-5 in complex reasoning benchmark ARC-AGI

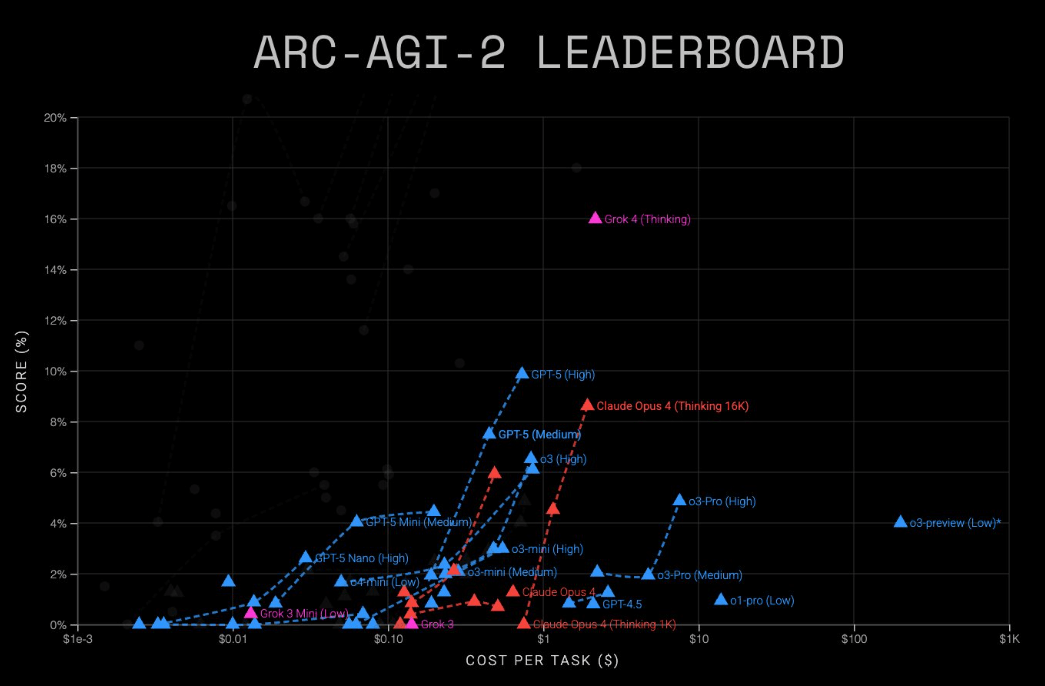
In the ARC-AGI-2 benchmark, which tests a model's general reasoning skills, GPT-5 (High) scored 9.9 percent at a cost of $0.73 per task, according to ARC Prize.
Grok 4 (Thinking) did better on ARC-AGI-2 at roughly 16 percent, but at a much higher $2 to $4 per task. The ARC-AGI benchmarks emphasize reasoning over memorization and rank models by both accuracy and cost per solution.
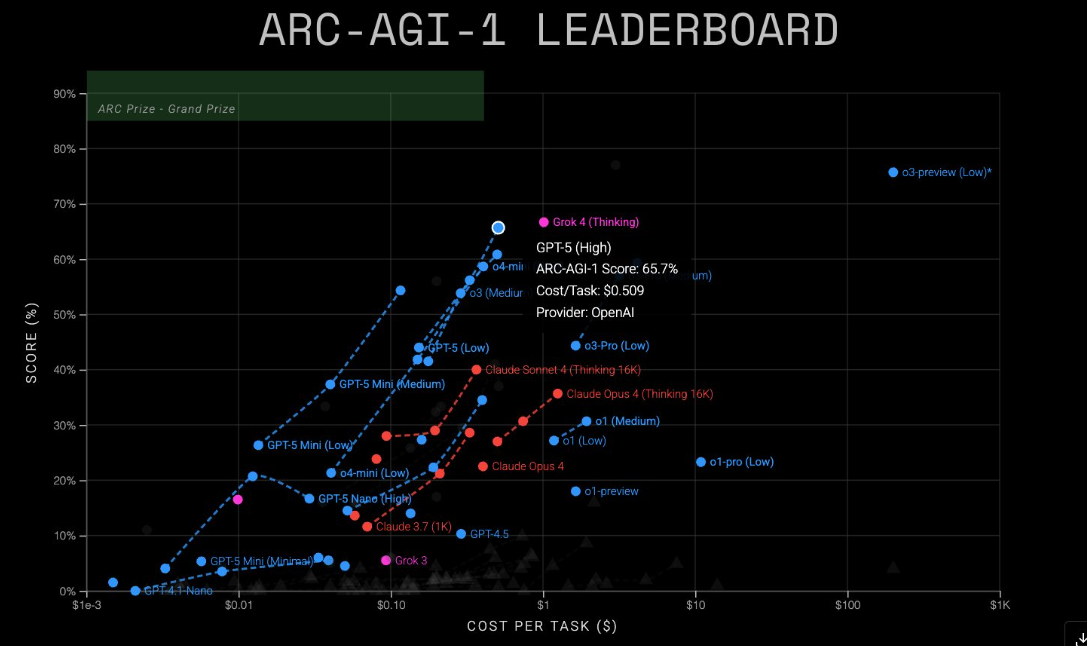
On the less demanding ARC-AGI-1 test, Grok 4 again led with about 68 percent, edging out GPT-5 at 65.7 percent. Grok 4 cost about $1 per task, while GPT-5 delivered similar performance for $0.51. That makes GPT-5 the better value for now, though xAI could narrow the gap with pricing changes.
Lighter, cheaper versions are also available. GPT-5 Mini achieved 54.3 percent on AGI-1 ($0.12) and 4.4 percent on AGI-2 ($0.20). GPT-5 Nano managed 16.5 percent ($0.03) and 2.5 percent ($0.03), respectively.
According to ARC Prize, early, still unofficial tests are also underway for the interactive ARC-AGI-3 benchmark, which requires models to solve tasks through trial and error in a game-like setting. While humans breeze through these challenges, most AI agents still struggle with the visual puzzle games.
It's worth noting that Grok 4's strong showing here doesn't necessarily make it the better model overall, just the stronger performer on this particular benchmark—assuming XAI played by the rules.
The o3-preview puzzle
OpenAI did not mention the ARC Prize during its GPT-5 presentation, despite its significance in earlier model launches. Notably, in the ARC-AGI-1 test, the o3-preview model, introduced in December 2024, still holds the top score by a wide margin at nearly 80 percent, although its cost is much higher than that of competing models.
The Information reported that OpenAI had to make major reductions to o3-preview for the later chat version, but the company has yet to comment. ARC Prize confirmed the weaker results for the publicly released o3 model at the end of April.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.