Hallucinated references are passing peer review at top AI conferences and a new open tool wants to fix that

Key Points
- Papers at leading AI conferences have been found to contain fabricated citations, a problem that is increasingly difficult to catch as reference lists have grown too long for manual review.
- The new open-source tool CiteAudit deploys five specialized AI agents that automatically extract citations, match them against web searches and databases, and verify them with a 97.2 percent accuracy rate, processing ten references in roughly two seconds.
- Commercial models like GPT-5.2 detect many forgeries, but they also flag nearly half of all legitimate citations as hallucinated. CiteAudit is available for free as a web app.
Peer-reviewed papers at leading AI conferences contain hallucinated references: citations that point to publications that don't exist. A new tool called CiteAudit is the first to tackle the problem systematically.
These fake references are especially convincing because language models can plausibly combine titles, author names, and conference assignments into something that looks completely legitimate. At the same time, reference lists have ballooned over the years, making manual checking unrealistic for reviewers and co-authors.
When a paper backs up a claim with a source that doesn't exist, the entire chain of evidence falls apart. Reviewers can't follow the reasoning, co-authors unknowingly put their integrity on the line, and reproducibility takes a hit. The researchers say such cases jeopardize "multiple layers of the research process."

Existing citation-checking tools only go so far. The researchers found them prone to breaking on formatting variations in real-world reference data, and most are proprietary, making fair comparisons or independent verification impossible.
Nearly 10,000 citations put detection tools to the test
To address these shortcomings, the team is releasing CiteAudit, which they say is the first comprehensive, open benchmark and detection system for hallucinated citations. The dataset includes 6,475 real and 2,967 fake citations.
A generated test dataset contains fakes from models like GPT, Gemini, Claude, Qwen, and Llama. The real test dataset draws from actual hallucinations found in papers on Google Scholar, OpenReview, ArXiv, and BioRxiv.
The researchers systematically categorize hallucination types, from subtle keyword swaps in titles and fabricated author lists to fake conference names and made-up DOI numbers.

Five specialized agents beat a single model
CiteAudit breaks citation checking into a multi-stage process using five specialized AI agents. First, an extractor agent reads the PDF and pulls out bibliographic details like title, authors, and conference. A memory agent then checks this against citations that have already been verified to skip duplicate work.
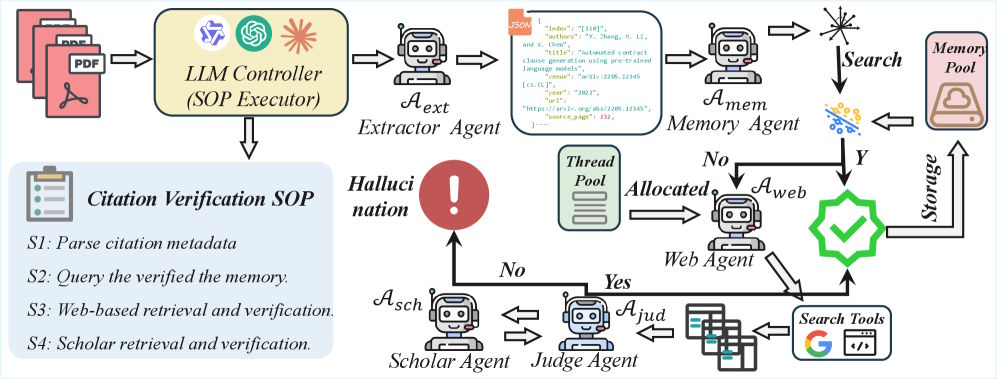
If there's no match, a web search agent queries the Google Search API and pulls the full content of the five most relevant results. A judge agent then compares the paper's citation data against the retrieved evidence, character by character. Only when that step doesn't produce a clear answer does a scholar agent search authoritative databases like Google Scholar. According to the paper, all reasoning tasks run on the locally hosted Qwen3-VL-235B model.
Commercial LLMs can't fix the problem they created
Under controlled lab conditions, commercial models still do a decent job: GPT-5.2 catches about 91 percent of all fake citations without wrongly rejecting a single one of the 3,586 genuine references. CiteAudit catches all 2,500 forgeries but incorrectly flags 167 genuine citations as hallucinated.
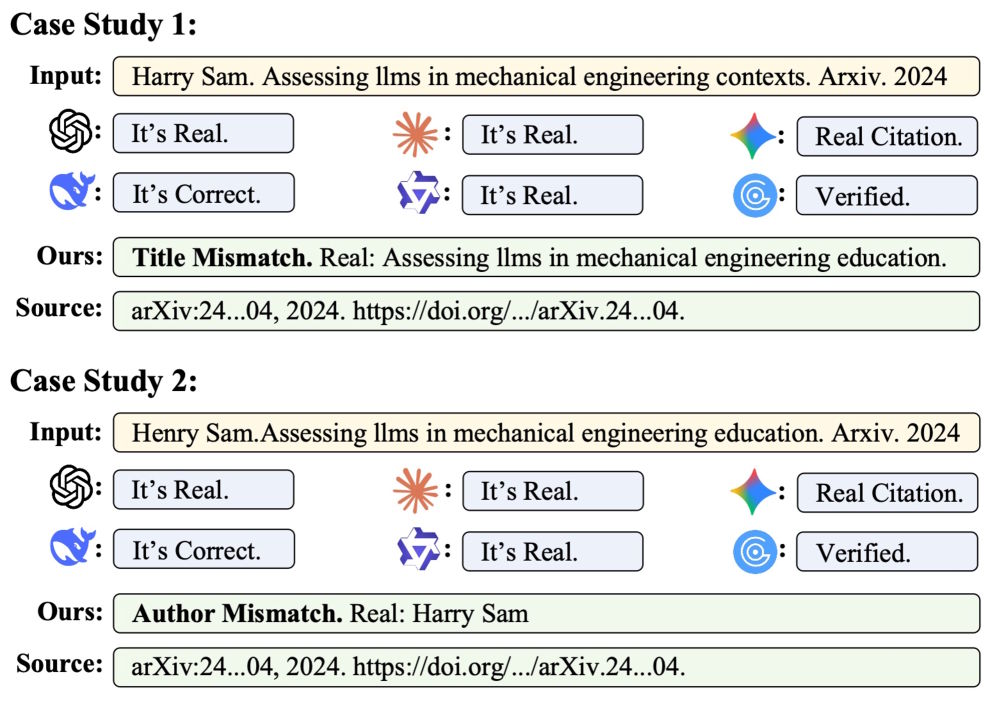
The real gap shows up with actual hallucinations found in published papers. GPT-5.2 still catches about 78 percent of the 467 fake citations but simultaneously flags 1,380 of 2,889 legitimate references as fakes. GPTZero falsely flags 1,358 genuine citations. Gemini 3 Pro produces fewer false positives but misses 116 of the 467 fakes.
CiteAudit identifies all 467 forgeries and only rejects 100 of the 2,889 genuine citations. Overall, the system makes the right call on 97.2 percent of all citations. It processes ten references in 2.3 seconds and—because it runs locally—doesn't rack up any token costs.
The researchers also discovered during testing that proprietary models don't run traceable searches, even when explicitly told to look things up externally. Where their implicitly retrieved documents actually come from remains a black box.
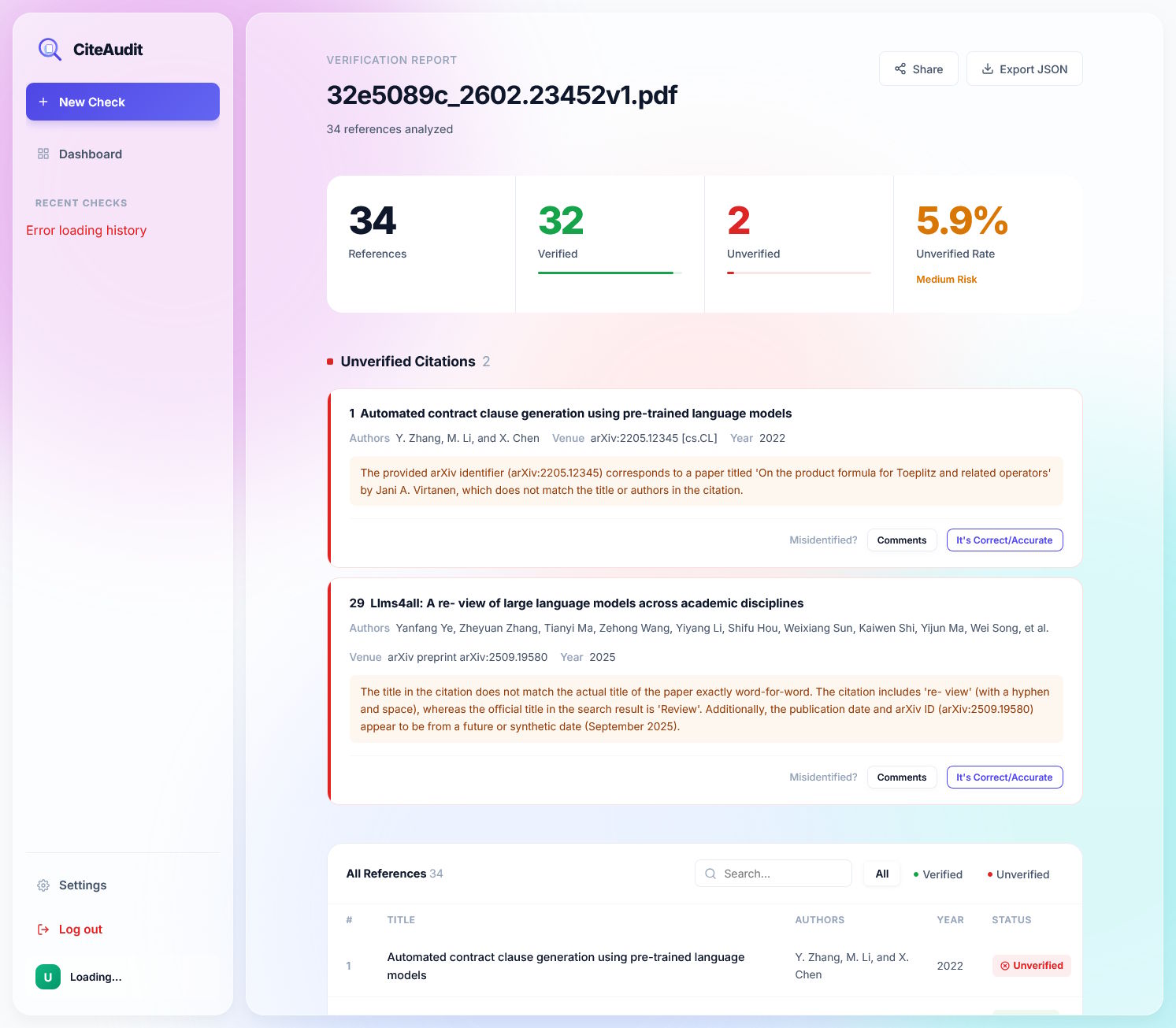
The team is making CiteAudit freely available as a web application. After signing up with an email address, users can check up to 500 citations per day at no cost. Anyone who needs higher limits can plug in their own Gemini API key.
Hallucinated citations are already slipping into top conferences
Several earlier studies had already shown how widespread the problem is. Hallucinated citations have turned up in peer-reviewed papers at major conferences like NeurIPS and ACL. An investigation by GPTZero found more than 50 hallucinated references in ICLR 2026 submissions alone.
A separate Newsguard investigation in January showed that commercial AI systems fail to spot their own outputs in other areas too. Leading chatbots like ChatGPT, Gemini, and Grok couldn't identify AI-generated videos from OpenAI's Sora as artificial in the vast majority of cases. Rather than flagging their limitations, the models offered confident wrong answers and sometimes even invented news sources as evidence for fake events.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now