
A study shows that when large language models (LLMs) see hundreds or thousands of examples right in the prompt, their performance on a variety of tasks improves significantly, according to researchers from Google, DeepMind, and other institutions.
The researchers studied how LLMs' performance improves when they are given many examples to learn from directly in the prompt, rather than just a few. This approach is called Many-Shot In-Context Learning (ICL).
In-context learning (ICL) means that the examples are given directly in the context (prompt), without adjusting the model parameters as in fine-tuning. The latter is much more time consuming and expensive.
Previously, models were usually given only a few examples (one shot, few shot) because they could not process and generate a lot of text at once. With larger "context windows", a kind of short-term memory, it is now possible to provide the model with hundreds or thousands of examples directly in the prompt (many shot).
The researchers tested Many-Shot ICL with Google's Gemini 1.5 Pro language model, which can process up to one million tokens (about 700,000 words) in context. The result: Many-shot prompts significantly outperformed few-shot prompts on tasks such as translating, summarizing, planning, and answering questions.
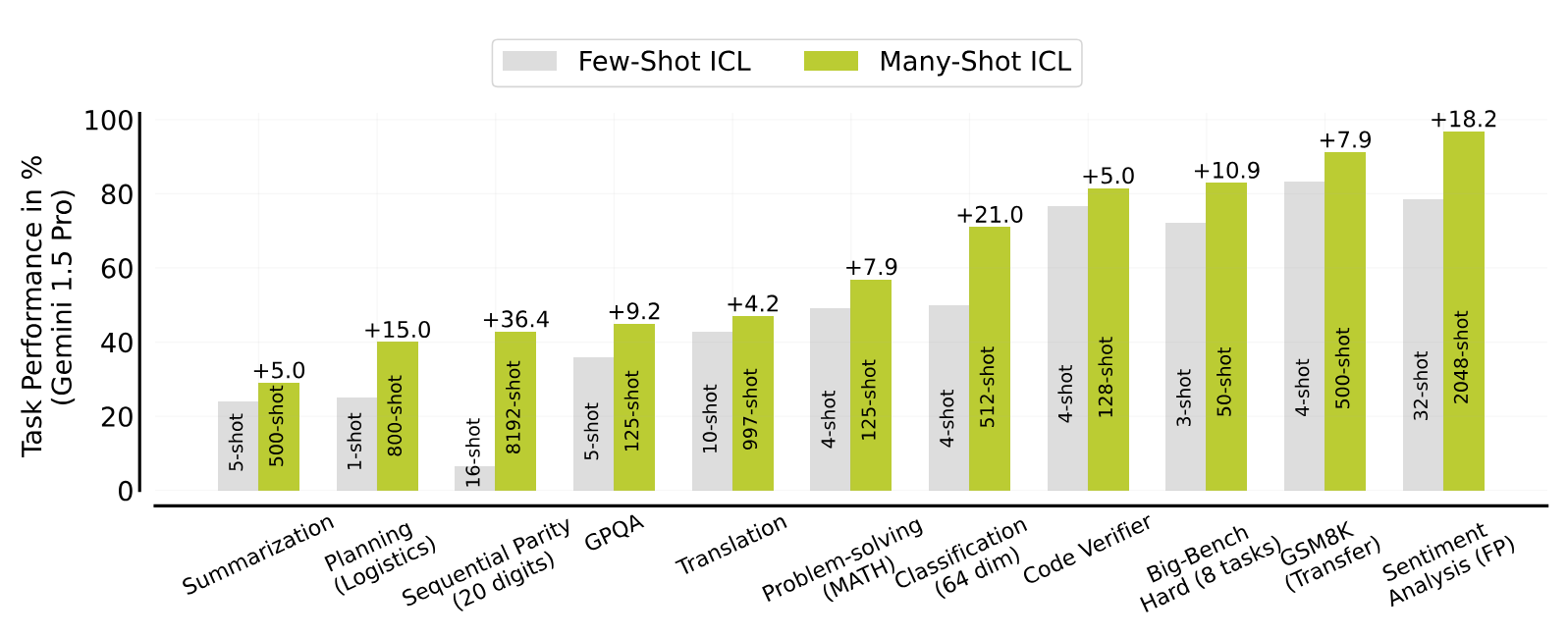
With about 1000 translation examples, Gemini 1.5 even outperformed Google Translate in Kurdish and Tamil, the target languages with the largest reported gap between LLMs and Google Translate to date.
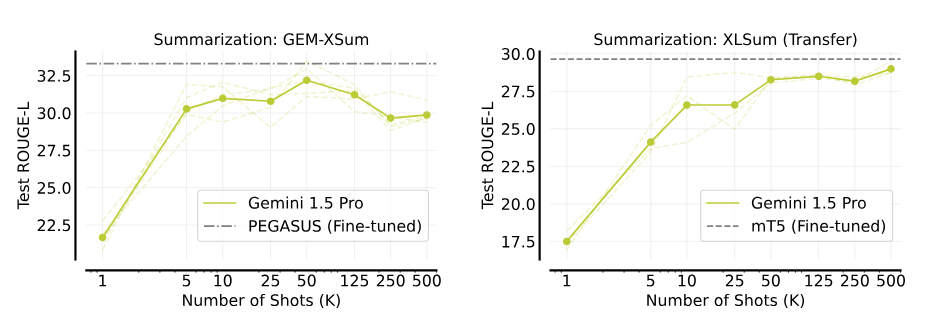
When summarizing news, it could almost keep up with specialized programs, but occasionally had hallucinations such as incorrect data and times that did not appear in the learning examples. In addition, performance dropped off after more than 50 examples, a phenomenon the researchers can't yet explain.
LLMs can generate their own learning examples
For tricky logical tasks, such as mathematical or scientific problems, the researchers had the model create its own solutions and used them as additional learning examples. This approach ("Reinforced ICL") worked more reliably than the human-created solutions.
In one experiment, the model was only given the problems without solutions ("Unsupervised ICL"). For some logical tasks, this still worked better than a few complete examples. However, it usually did not quite match the self-generated solutions with "Reinforced ICL".
The researchers also found that the model "unlearned" errors from pre-training through examples and could even recognize abstract mathematical patterns when shown enough examples.
However, the order in which the examples were given to the model made a difference, making the prompt more complex. It's also an open question why performance sometimes declines with even more examples. Future research is needed to clarify this.
In any case, the results show that language models can learn reliably from many examples in the prompt. This could make time-consuming training for specific tasks unnecessary in the future.
It also results in an additional task for prompt writers: They need to find or generate high-quality examples that fit the task.




