
Researchers at the University of California, Berkeley and Google DeepMind have developed a method that demonstrates AI language models with access to search engines provide more accurate answers than human annotators.
The researchers used Google DeepMind's Search-Augmented Factuality Evaluator (SAFE) tool to assess the factual accuracy of the responses. SAFE uses an AI agent to break down text responses into individual facts, check their relevance, and verify the relevant facts through Google searches, allowing it to assess the accuracy of each factual claim.
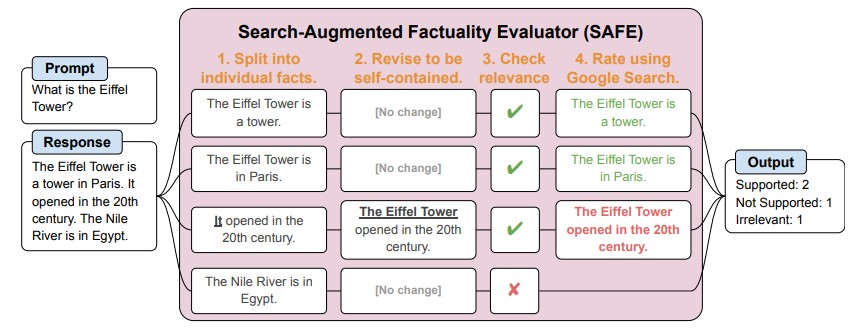
For the study, GPT-4 generated the publicly available "LongFact" dataset, containing 2,280 questions on 38 topics, which contains 2,280 questions on 38 topics and serves as the basis for evaluating the factual accuracy of long answers provided by large language models (LLMs).
A potential weakness of the system is that LongFact and SAFE depend on the capabilities of the language models used. If these models have weaknesses in following instructions or reasoning, this will affect the quality of the questions and scores generated. In addition, fact-checking depends on the capabilities and accesses of Google search.
Language models with internet access hallucinate less than humans
The researchers compared SAFE's ratings for 16,011 individual facts with the ratings of human annotators from an earlier dataset.
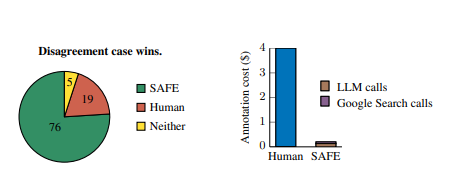
They found that SAFE provided the same rating as human annotators for 72 percent of the facts, suggesting comparable performance in most cases. Moreover, in 100 instances where SAFE and humans disagreed, SAFE was correct in its assessment 76 percent of the time, while human annotators were only correct in 19 percent of cases, demonstrating SAFE's fourfold superiority in these situations.
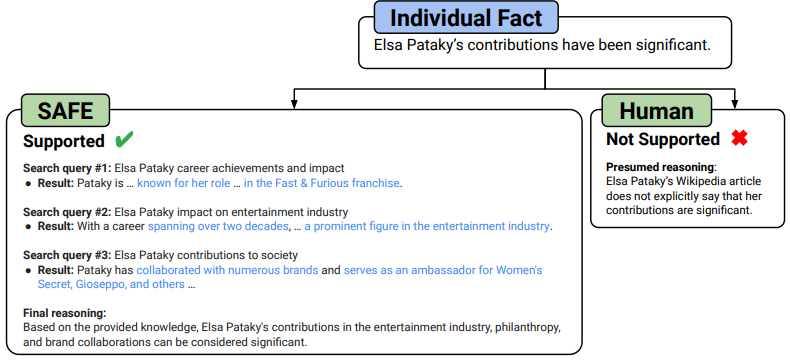
According to the researchers, when the AI model fails, it is primarily due to incorrect reasoning - since only GPT-3.5 was used here, there is still plenty of room for improvement.
In addition to its already superior performance, SAFE was more than 20 times cheaper than human annotators ($0.19 per answer vs. $4 per answer). The researchers attribute AI's advantage to its ability to systematically retrieve and analyze vast amounts of information from the Web, while humans often rely on memory or subjective judgments, leading to more hallucinations.
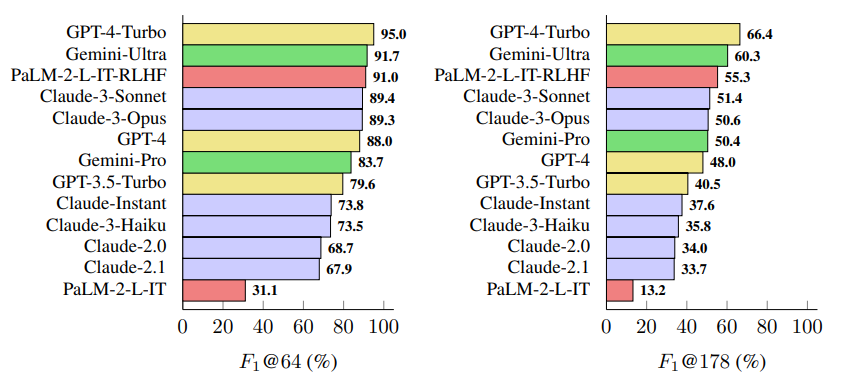
The study examined 13 language models from four model families (Gemini, GPT, Claude, and PaLM-2), with larger language models generally achieving better fact fidelity for long responses. GPT-4-Turbo, Gemini-Ultra and PaLM-2-L-IT-RLHF performed best.

The newly introduced "F1@K" measure considers both accuracy and comprehensiveness of answers, allowing for a standardized comparison of different language models.
The results have significant implications for the use of LLMs in real-world applications, particularly where factual accuracy is crucial. They demonstrate that LLMs with Internet access can be an effective tool for automated fact-checking.
The research findings could also indicate how Google aims to enhance the reliability of generative text AI, especially in the context of search. The Google Check button in the Gemini chatbot, which supports statements generated by the LLM with internet sources, is already a step in this direction. SAFE goes further by incorporating integrated reasoning.
The research may also explain OpenAI's interest in more closely integrating LLM and internet search into a single product. The complete results and code are available on GitHub.


