With Imagen, Google follows OpenAI and shows that artificial intelligence can produce credible and useful images.
Imagen is Google's answer to OpenAI's recently unveiled image AI DALL-E 2. With one difference: OpenAI has introduced DALL-E 2 directly as a product, including beta testing that will be available to more people starting this summer.
According to the Google researchers, Imagen outperforms DALL-E 2 in terms of precision and quality, but currently it is only available as a scientific paper. For ethical reasons, this is unlikely to change in the near future, but more on that later.
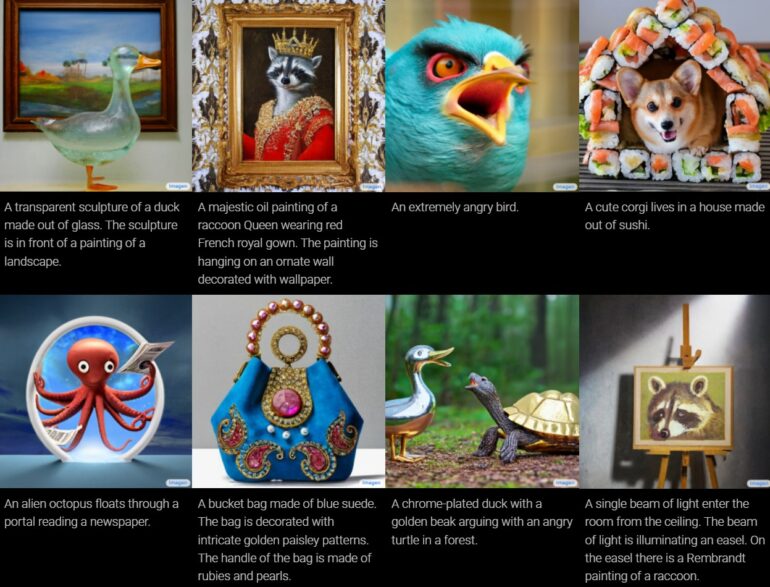
Text becomes image
Imagen relies on a large, pre-trained Transformer language model (T5) that generates a numerical image representation (image embedding), from which a diffusion model creates an image. Diffusion models see images that gradually become noisy during training. The models can reverse this process after training, i.e. produce an image out of the noise.
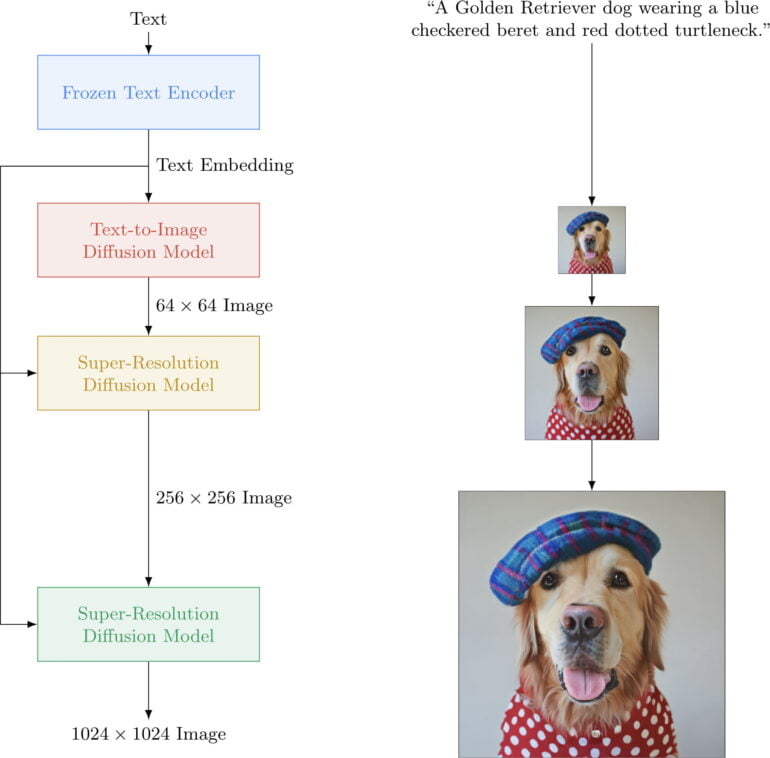
The low-resolution original image (64 x 64) is then enlarged to 1024 x 1024 pixels using AI scaling - the same resolution as DALL-E 2. Similar to Nvidia DLSS, AI scaling adds new details to the original image that match the content, so that it also offers high sharpness in the target resolution. This upscaling process saves Imagen a lot of computing power that would be necessary if the model were to output high resolutions directly.
Imagen performs better than DALL-E 2 in human evaluation
A key finding of the Google AI team is that a large pre-trained language model is surprisingly effective for encoding text for subsequent image synthesis. Moreover, for more realistic image generation, they say, increasing the size of the language model has a greater effect than more extensive training of the diffusion model that creates the actual image.
The team developed the "DrawBench" benchmark, in which humans evaluate the quality of a generated image and how well the image details match the input text. The testers compare the results of several systems in parallel.
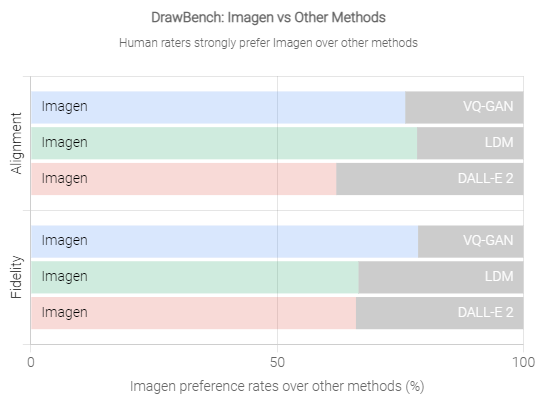
Imagen performed significantly better than DALL-E 2 in this test, which the researchers attribute in part to the text model's greater understanding of language. In most cases, Imagen was able to translate the instruction "A panda making latte art" into the appropriate motif: a panda perfectly pouring milk into a latte. DALL-E 2 instead creates a panda face in the milk foam.

Move slowly and let things heal
Google AI does not currently plan to release the model for ethical reasons, as the underlying text model contains social biases and constraints, so Imagen could generate harmful stereotypes, for example.

In addition, Imagen currently has "significant limitations" in generating images with people on them, "including an overall bias towards generating images of people with lighter skin tones and a tendency for images portraying different professions to align with Western gender stereotypes." For this reason, Google does not want to release Imagen or similar technology "without further safeguards in place."
DALL-E 2 also has these issues. OpenAI is therefore rolling out the image AI very slowly to circa 1000 testers per month. A recent study after three million generated images has shown that currently only a fraction of DALL-E motifs violate OpenAI's content guidelines.
Jeff Dean, senior AI researcher at Google AI, sees AI as having the potential to foster creativity in human-computer collaboration. Imagen, he said, is "one direction" Google is pursuing in this regard. Dean shares numerous Imagen examples on Twitter. More information and an interactive demo are available on the Imagen project page.