
- Added LeoLM 70B
Update from 02. December 2023:
LAION releases the 70 billion version of LeoLM trained with 65 billion tokens. It is based on Llama-2-70b, but according to LAION it can beat Meta's base model - in both German and English.
"With this release, we hope to bring a new wave of opportunities to German open-source and commercial LLM research and accelerate adoption," the team writes.
According to LAION, LeoLM surpasses the translation performance of gpt-3.5.turbo-instruct in few-shot applications and achieves better benchmark results than the Llama-2 base model. All models, including a chat version, are available from Hugging Face under the Llama license.
Original article from September 29. 2023:
Laion and Hessian.AI launch the German language model LeoLM (Linguistically Enhanced Open Language Model).
Laion and Hessian.AI have jointly developed LeoLM, the first commercially viable open-source "German Foundation Language Model". It is based on Meta's Llama 2 and has been trained on the Hessian.AI supercomputer 42 with an extensive corpus of high-quality German and country-specific texts.
The now released models LeoLM/leo-hessianai-7b and LeoLM/leo-hessianai-13b as well as the upcoming LeoLM-70B are intended to advance the German LLM landscape for open-source and commercial applications.
All models feature an 8K context window. The most powerful model is leo-hessianai-13b-chat, which almost reached the performance of GPT-3.5 in the humanities task of the GPT-4 based AI test "MT-Bench".


Overcoming language barriers in LLMs
LeoLM serves as a feasibility study for language learning with pre-trained models, the team writes. To improve Llama-2's German capabilities, LeoLM underwent Level 2 pre-training, in which the models were initialized with Llama-2 weights and trained on a large German text corpus containing 65 billion tokens. The goal was to preserve as much of the model's previous capabilities as possible.
The project team translated several high-quality instructional datasets from English into German using GPT-3.5. They also used existing datasets with German texts and created two datasets focusing on creative writing and rhyming to address weaknesses identified during initial testing.
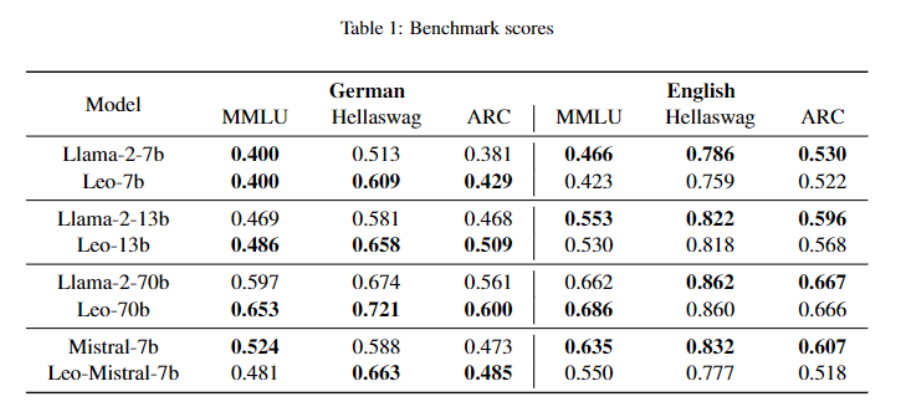
For the evaluation, the team translated a set of English benchmarks into German to standardize the comparison of the models and to provide a comprehensive evaluation approach for the basic and chat models ("GermanBench"). The results show that the training improved the benchmark results for German, while the results for English decreased slightly.

However, the average increase in benchmark scores for German exceeds the average decrease in benchmark scores for English. The team sees this as evidence that an LLM can learn a new language without forgetting existing skills.
All LeoLM models and the datasets used for training are available on HuggingFace. For productive use of a language model for German-language tasks, the announced 70 billion parameters should be where things get interesting.




