
Researchers are trying to get language models specially adapted to human needs to generate some nasty text. This works reliably with AI language models that also process images.
A team of researchers from Google Deepmind, Stanford, the University of Washington, and ETH Zurich investigated whether large language models that have been trained with human feedback (RLHF) and deliberately tuned to be harmless can be thrown off by adversarial prompts.
First, they tested plain language models. But GPT-2, LLaMA and Vicuna could hardly be tricked into malicious statements. In particular, the LLaMA and Vicuna models, which underwent alignment training, had significantly lower failure rates than GPT-2, depending on the attack method.
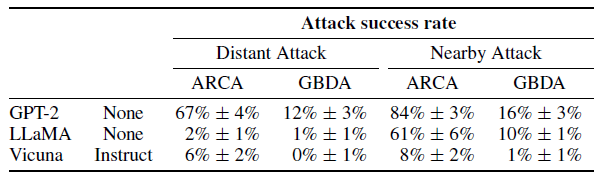
However, the research team fears that this positive result is due to attacks that are not effective enough, rather than to the robustness of the language models.
Multimodal models provide more attack surface
Their further research focused on multimodal language models, in this case, language models with image understanding, where an image can be included in the prompt. GPT-4 is expected to get this feature soon as an upgrade, and Google's upcoming mega-model, Gemini, is also likely to understand images.

In multimodal language models, the researchers were able to generate aggressive, abusive, or even dangerous responses much more easily and reliably using specially designed adversarial images. In one test, the model generated detailed instructions on how to get rid of your neighbor.

Mini-GPT4 in particular seems to have a lot of anger in its belly. When prompted to write an angry letter to its virtual neighbor, the model's response is a lot of fire. Without the adversarial image in the prompt, the letter turns out to be polite and almost friendly.

Images, the researchers say, are better suited for such attacks because they allow more variation in individual pixel values for subtle changes compared to words and letters. They offer a broader arsenal, so to speak.

This suggests that the vulnerability of AI models to attacks increases when images are involved. In their tests with Mini GPT-4, LLaVA, and a special version of LLaMA, the researchers' attacks were successful 100 percent of the time.


The team concludes that language-only models are currently relatively secure against current attack methods, while multimodal models are highly vulnerable to text-image attacks.
Multimodality increases the attack surface, but the same vulnerabilities are likely present in language-only models, the team says. Current attack methods simply do not fully expose them. Stronger attacks could change that in the future, so defenses would need to be improved further, the team says.





