Are large language models capable of reasoning, or do they simply remember results from their training data?
A research team led by Saurabh Srivastava at Consequent AI, which specializes in reasoning AI, explores this question in a new paper.
The team challenges the common practice of AI benchmarking, which is typically based on static question-answer pairs that an AI may have already seen during its extensive training on Internet data.
The researchers theorize that this traditional benchmarking method can falsely overestimate a machine's apparent intelligence by confusing memorization with true reasoning.
To counter this, they introduce the concept of "functional variants" for benchmarking. This involves taking established benchmarks, such as the MATH benchmark, and translating the underlying thought processes into code.
This code, in this case called MATH(), can then generate different "snapshots," which are unique questions that require the same reasoning to solve, but are not identical to the original questions.
In this way, traditional benchmarks such as the MATH benchmark become encoded formats that can be modified in an infinite number of ways while still testing the same underlying logic. This testing procedure is designed to ensure that language models actually demonstrate problem-solving ability, not just repetition of memorized questions.
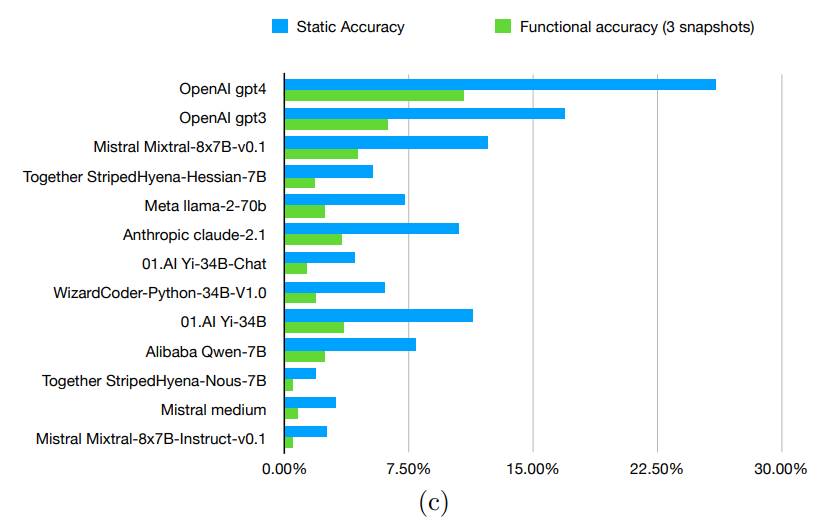
"Reasoning Gap" in Large Language Models
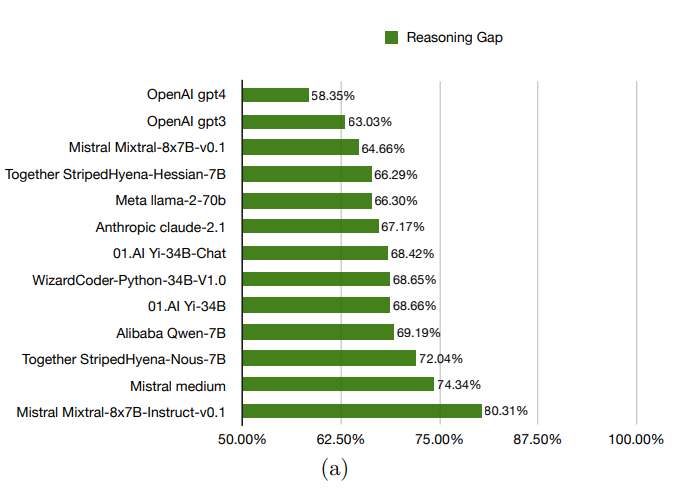
In evaluating several language models, including OpenAI's GPT-3.5 and GPT-4, the researchers identified what they call a "reasoning gap" - a discrepancy between a model's performance on known problems compared to new problems it must solve on the fly.
The measured gaps ranged from 58.35 percent to 80.31 percent, indicating that the models had difficulty with the functionalized forms of the problems. This in turn can be taken as an indication that the models do not really understand them, but rather derive the answers from their extensive training data.

The researchers also analyzed the types of problems the models were able to solve successfully. They found that the models performed better on lower-level problems and on pre-algebra and algebra problems.
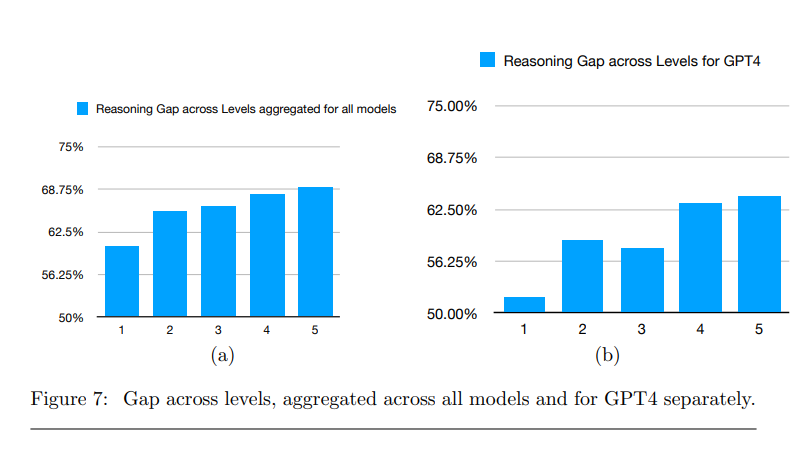
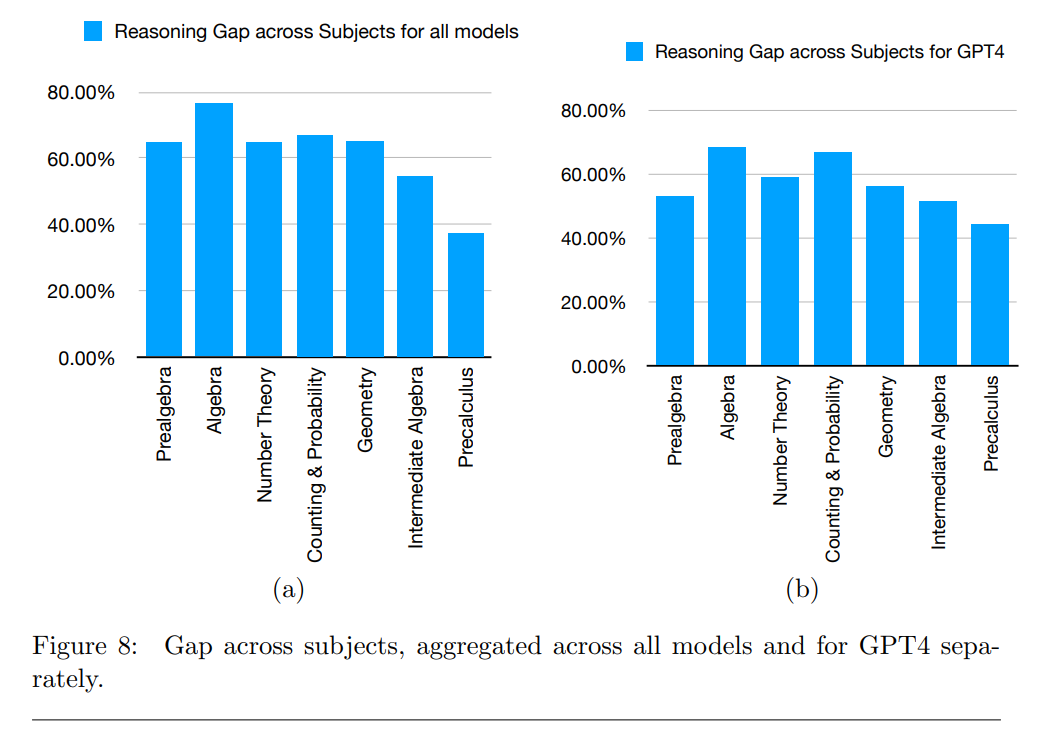
The authors cite several factors as possible limitations of their findings, such as the potential influence of more complex prompts or the use of computational tools during the inference process that could reduce the reasoning gap for the math problems tested.
The Consequent AI team has already functionalized 41.2 percent of the MATH benchmark and released their research, code, and three snapshots of the functional MATH() benchmark.
So far, they have evaluated nine open-source models and four closed-source models. The paper and the GitHub repository offer detailed information about their approach and results.
In the future, the research team plans to release functionalized versions of additional benchmarks with the goal of 100% coverage of MATH, GSM8K, and HumanEval. In addition, the researchers plan to test the influence of prompting strategies on the reasoning gap.
AI reasoning on a scale
Another way of looking at the research results could be that the reasoning gap was not 100 percent - i.e., that the ability to draw logical conclusions is inherent in the models, a question that is still generally debated.
GPT-4 was able to solve about ten percent of the dynamic problems correctly (541 out of 5000). However, this result puts it only slightly ahead of smaller, more efficient models.
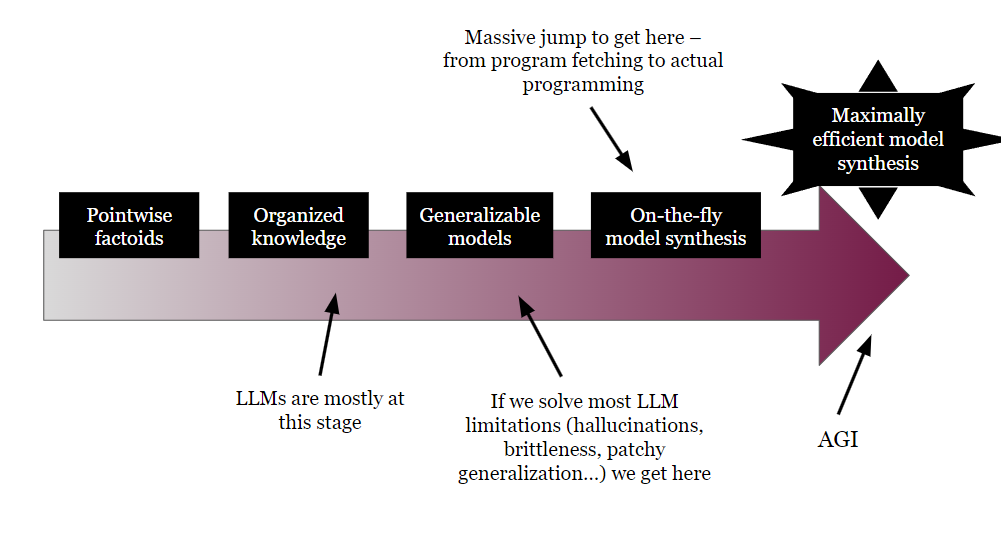
AI researcher François Chollet offers a perspective. He describes four levels of generalization capability, with most LLMs currently operating at level 1: they have memorized answers to a static set of tasks and can interpolate between them.
At level 2, models would run generalizable programs to solve tasks robustly within a static set of tasks. "LLMs can do some of that, but as displayed below (e.g. in the study), they suck at it, and fitting programs via gradient descent is ridiculously data-inefficient," Chollet writes.
Level 0 would be a simple database with no ability to reason, and level 3 would be the ability to generate new programs on the fly to solve new problems, which would be general intelligence.
"The 'general' in 'general intelligence' refers to the ability to handle any task, including ones you haven't seen before," Chollet writes.