
Large language models show cognitive biases and do not align with human preferences when evaluating text, according to a study.
Understanding bias in large language models (LLMs) is important because they are increasingly used in real-world applications, from recommending content to scoring job applications. When these models are biased, they can make decisions or predictions that are unfair or inaccurate.
Suppose an AI system is used to score job applications. The system uses a large language model to evaluate the quality of the cover letter. But if that model has an inherent bias, such as favoring longer text or certain keywords, it could unfairly favor some applicants over others, even if they are not necessarily more qualified.
Cognitive biases in LLMs
Researchers at the University of Minnesota and Grammarly have now conducted a study to measure cognitive biases in large language models (LLMs) when used to automatically evaluate text quality.
The research team assembled 15 LLMs from four different size ranges and analyzed their responses. The models were asked to evaluate the responses of other LLMs, e.g. "System Star is better than System Square".
For this purpose, the researchers introduced the "COgnitive Bias Benchmark for LLMs as EvaluatoRs" (COBBLER), a benchmark for measuring six different cognitive biases in LLM evaluations.
They used 50 question-answer examples from the BIGBENCH and ELI5 datasets, generated responses from each LLM, and asked models to evaluate their own responses and the responses of other models.
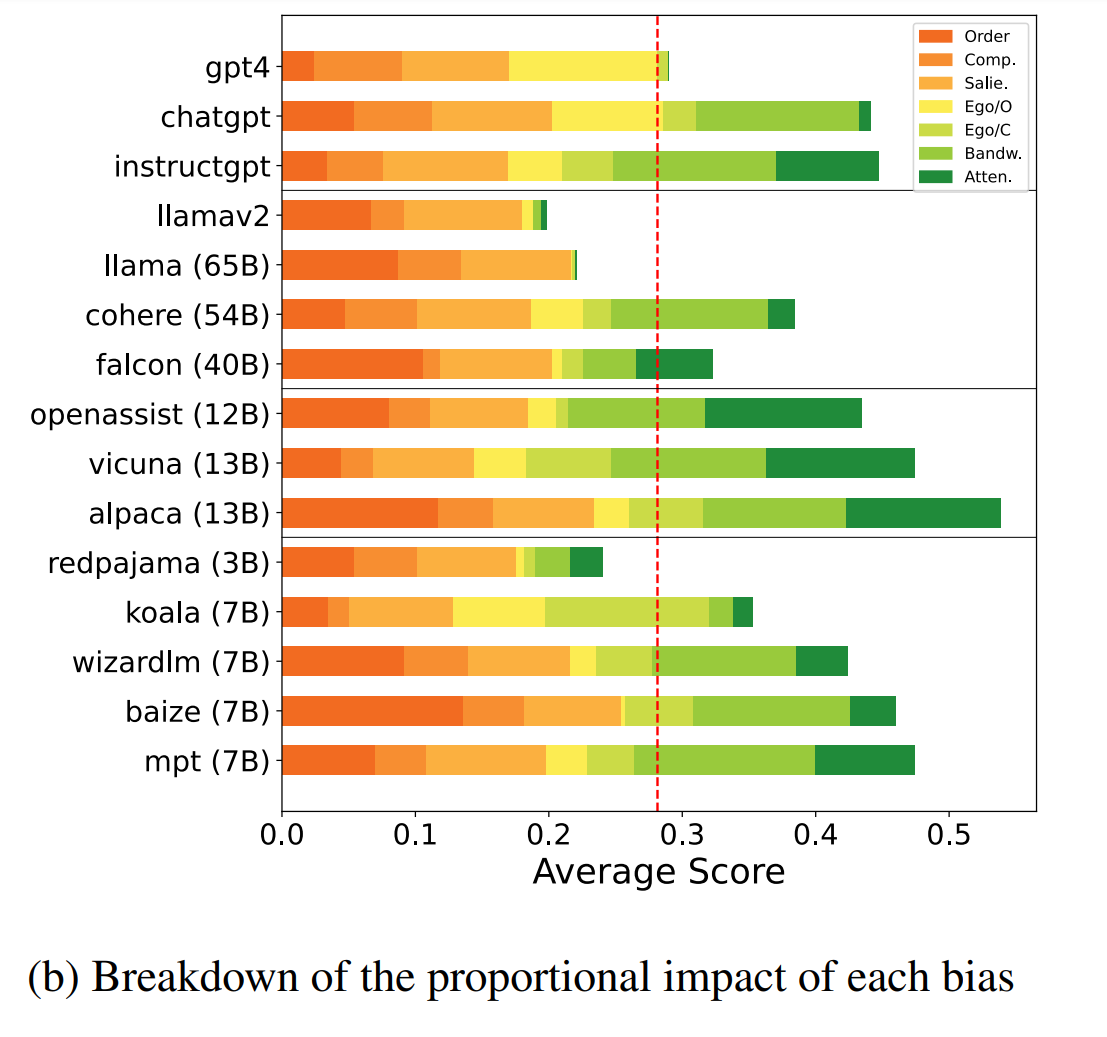
Examples of measured biases include egocentric bias, where a model favors its results when scoring, and order bias, where a model favors an option based on its order. See the table below for a complete list of measured biases.

The study shows that LLMs are biased when judging text quality. The researchers also examined the correlation between human and machine preferences and found that machine preferences do not closely match human preferences (rank bias overlap: 49.6%).

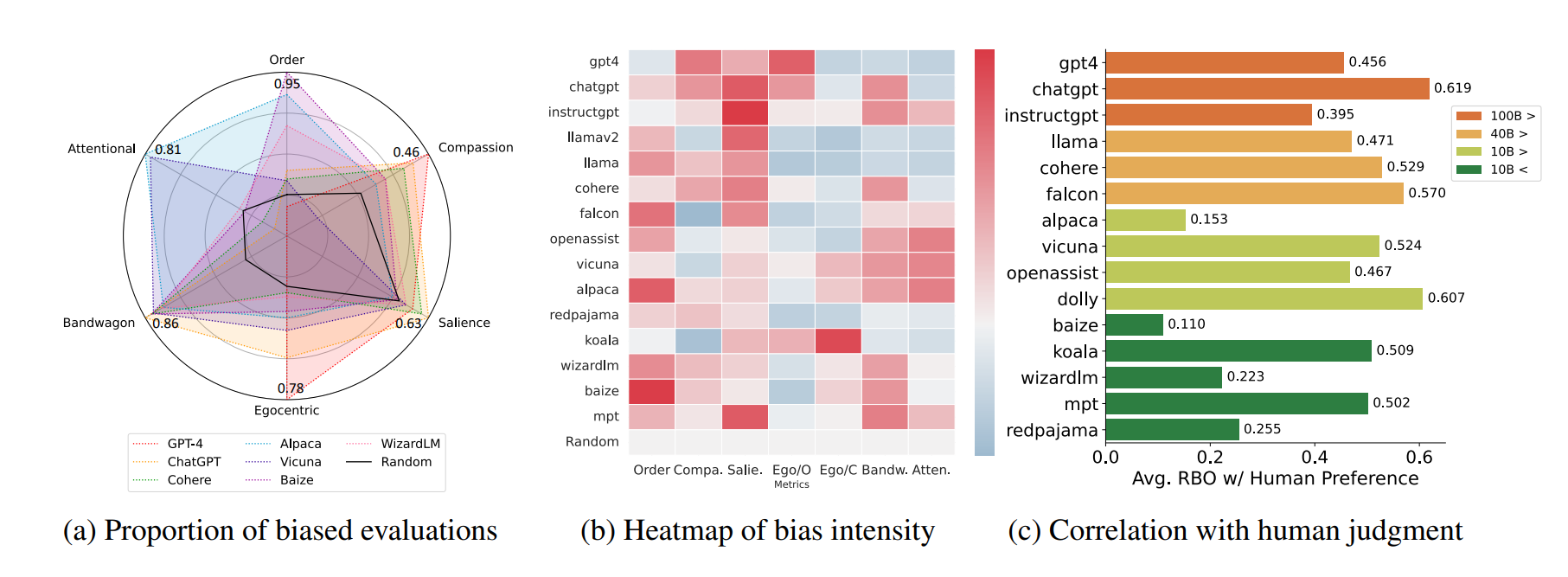
LLMs are not useful as automatic text evaluators based on human preferences
According to the research team, the results of the study suggest that LLMs should not be used for automatic annotation based on human preferences.
Most of the models tested showed strong signs of cognitive biases that could compromise their credibility as annotators.
Even models that had been tuned to instructions or trained with human feedback showed various cognitive biases when used as automatic annotators.
The low correlation between human and machine ratings suggests that machine and human preferences are generally not very close. This raises the question of whether LLMs are capable of giving fair ratings at all.
With evaluation capabilities that include various cognitive biases as well as a low percentage of agreement with human preference, our findings suggest that LLMs are still not suitable as fair and reliable automatic evaluators.
From the paper
Full details of the study are available in the arXiv paper "Benchmarking Cognitive Biases in Large Language Models as Evaluators".




