Over 40 researchers have conducted the first large-scale systematic study of prompting techniques. The resulting "Prompt Report" covers hundreds of techniques and offers insights into the possibilities and features of prompting.
While prompting seems ubiquitous these days, the generative AI industry has lacked a thorough and systematic examination of the hundreds of techniques that have emerged.
To address this gap, a group of over 40 researchers from various universities and companies, including OpenAI and Microsoft, have published the "Prompt Report" - the first large-scale, systematic review of prompting techniques.
The researchers analyzed a dataset of more than 1,500 publications on prompting, which they collected using a machine-assisted version of the PRISMA method for systematic reviews.
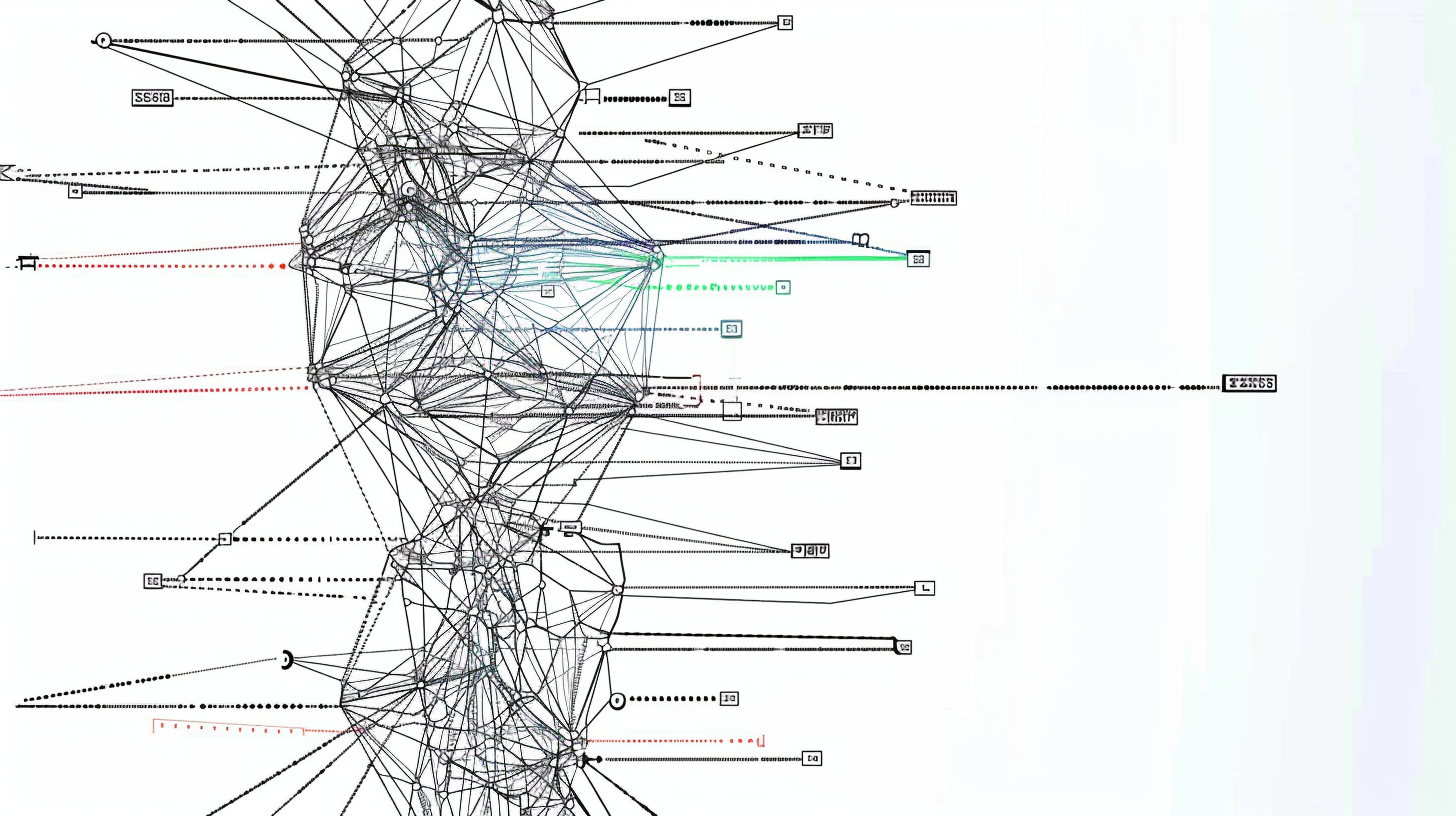
From this analysis, they derived a taxonomy comprising 58 text-based prompting techniques, 40 multimodal techniques, agent-based extensions, and topics such as safety and alignment.
LLMs are weird
The researchers discovered some curious artifacts, such as the fact that duplicating parts of a prompt can significantly increase performance.
In a case study on suicidal crisis detection, an email with context about a case was accidentally included twice in the prompt, and removing this duplication reduced accuracy.
There is no clear explanation for this effect. According to the researchers, it is reminiscent of instructing an LLM to reread a task before performing it, which can also improve output quality.
The inclusion of people's names in the prompts can also be significant, according to the tests. When the names in the email mentioned above were anonymized by replacing them with random names, the model's accuracy decreased.

This sensitivity to seemingly irrelevant details is puzzling, and the researchers see both positive and negative aspects. On the positive side, they suggest that performance improvements can be achieved through exploration.
On the negative side, the email example shows that "prompting remains a difficult to explain black art," where the language model is unexpectedly sensitive to details the user considers irrelevant.
Due to this sensitivity, the authors recommend close collaboration between prompt engineers, who know how to control the models, and domain experts, who precisely understand the goals.
"These systems are being cajoled, not programmed, and, in addition to being quite sensitive to the specific LLM being used, they can be incredibly sensitive to specific details in prompts without there being any obvious reason those details should matter," the researchers write.
Prompts with examples are most effective
Few-shot prompting, i.e., prompting with examples directly in the prompt, is generally the most efficient prompting method.
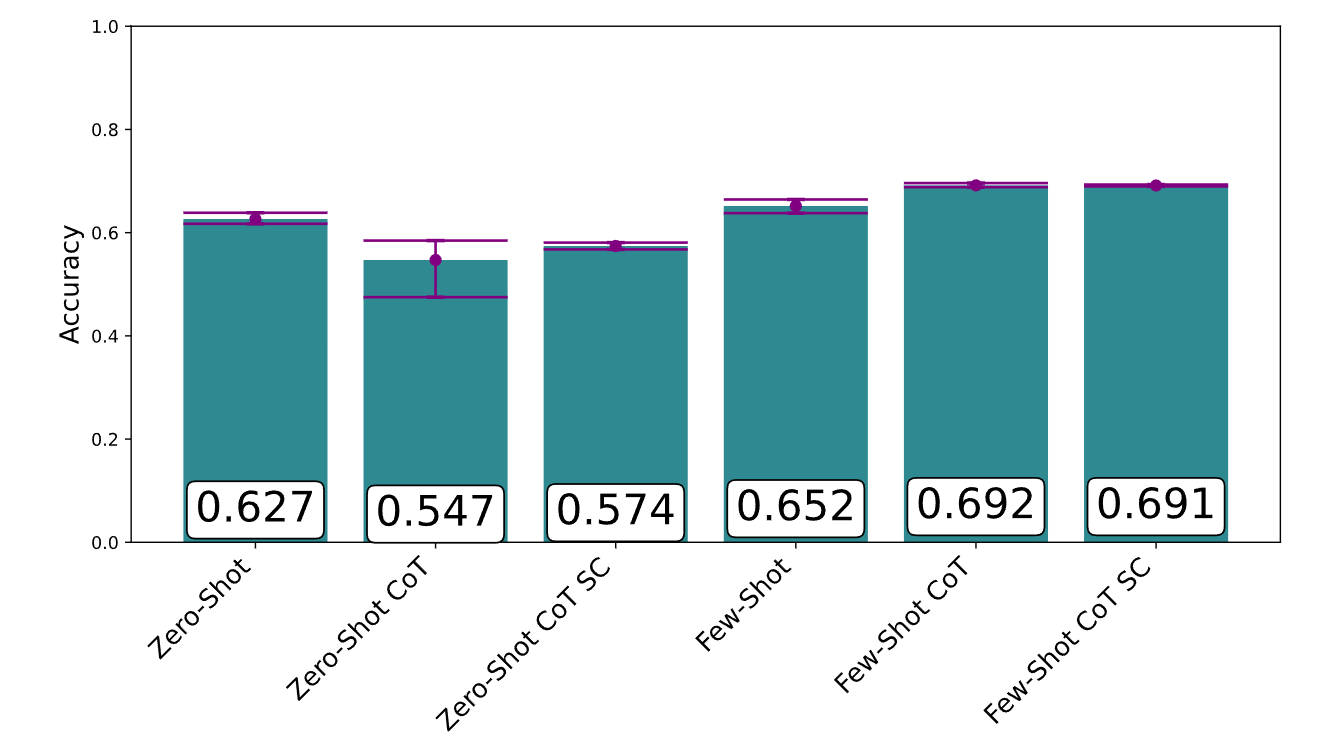
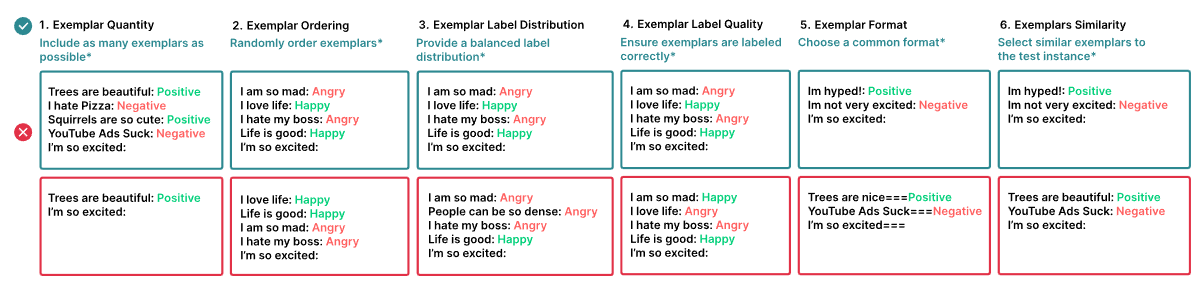
However, there are some strange pitfalls here as well. LLMs are very sensitive to the selection and order of examples.
Depending on the order, performance can vary from less than 50 percent to more than 90 percent accuracy. Selecting similar examples for the test case is usually helpful, but in some cases, different examples work better.
The report also shows that only a small proportion of prompting techniques have been widely used in research and industry to date, with few-shot and chain-of-thought prompting being the most common. Techniques such as Program-of-Thoughts, where code is used as an intermediate step for reasoning, are promising but not yet widely used.
Due to the challenges of manual prompting, the researchers see great potential in automation. In a case study, an automated approach achieved the best results. However, a combination of human fine-tuning and machine optimization could be the most promising approach, according to the researchers.
In addition to systematizing the knowledge, the researchers aim to develop a common terminology and taxonomy. With their work, they hope to create a foundation for better understanding, evaluation, and further development of prompting.
For now, they recommend not blindly relying on benchmark results, but thoroughly testing techniques in practice.



