
Researchers have found that giving large language models (LLMs) many examples directly in the prompt can be more effective than time-consuming fine-tuning, according to a study from Carnegie Mellon and Tel Aviv University.
This "in-context learning" (ICL) approach becomes more effective as the context window of LLMs grows, allowing for hundreds or thousands of examples in prompts, especially for tasks with many possible answers.
One method for selecting examples for ICL is "retrieval," where an algorithm (BM25) chooses the most relevant examples from a large dataset for each new question. This improves performance compared to random selection, particularly when using fewer examples.
However, the performance gain from retrieval diminishes with large numbers of examples, suggesting that longer prompts become more robust and individual examples or their order become less important.
While fine-tuning usually requires more data than ICL, it can sometimes outperform ICL with very long contexts. In some cases, ICL with long examples can be more effective and efficient than fine-tuning, even though ICL does not actually learn tasks but solves them using the examples, the researchers noted.
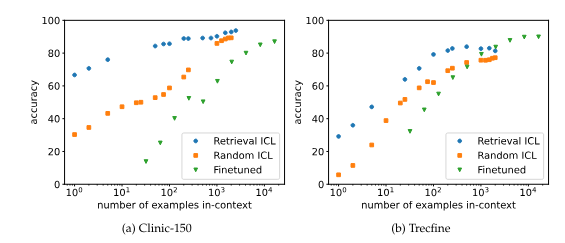
The experiments used special variants of the Llama-2-7B and Mistral-7B language models, which can process particularly long input text. The results suggest that ICL with many examples can be a viable alternative to retrieval and fine-tuning, especially as future models improve at handling extremely long input texts.
Ultimately, the choice between ICL and fine-tuning comes down to cost. Fine-tuning has a higher one-time cost, while ICL requires more computing power due to the many examples in the prompt. In some cases, it may be best to use many-shot prompts until you get a robust, reliable, high-quality result, and then use that data for fine-tuning.
While finetuning with full datasets is still a powerful option if the data vastly exceeds the context length, our results suggest that long-context ICL is an effective alternative– trading finetuning-time cost for increased inference-time compute. As the effectiveness and effiency of using very long model context lengths continues to increase, we believe long-context ICL will be a powerful tool for many tasks.
From the paper
The study confirms the results of a recent Google Deepmind study on many-shot prompts, which also showed that using hundreds to thousands of examples can significantly improve LLM results.



