Meta develops AI system MoCha that turns text into animated characters

Meta and University of Waterloo researchers have built MoCha, an AI system that generates complete character animations with synchronized speech and natural movements.
Unlike previous models that focused only on faces, MoCha can render full-body movements from various camera angles, including lip synchronization, gestures, and interactions between multiple characters. Early demonstrations focus on close-up and semi-close-up shots, where the system generates upper body movements and gestures that align with spoken dialogue.
Video: Wei et al.
MoCha runs on a diffusion transformer model with 30 billion parameters. It produces HD video clips around five seconds long at 24 frames per second, putting it on par with current video generation models.
Improving lip sync accuracy
The system introduces a "Speech-Video Window Attention" mechanism to solve two persistent challenges in AI video generation: video compression during processing while audio stays at full resolution, and mismatched lip movements during parallel video generation.
The system achieves this by limiting each frame's access to a specific window of audio data. This approach reflects how human speech works - lip movements depend on immediate sounds, while body language follows broader patterns in the text. Adding tokens before and after each frame's audio helps create smoother transitions and more accurate lip synchronization.
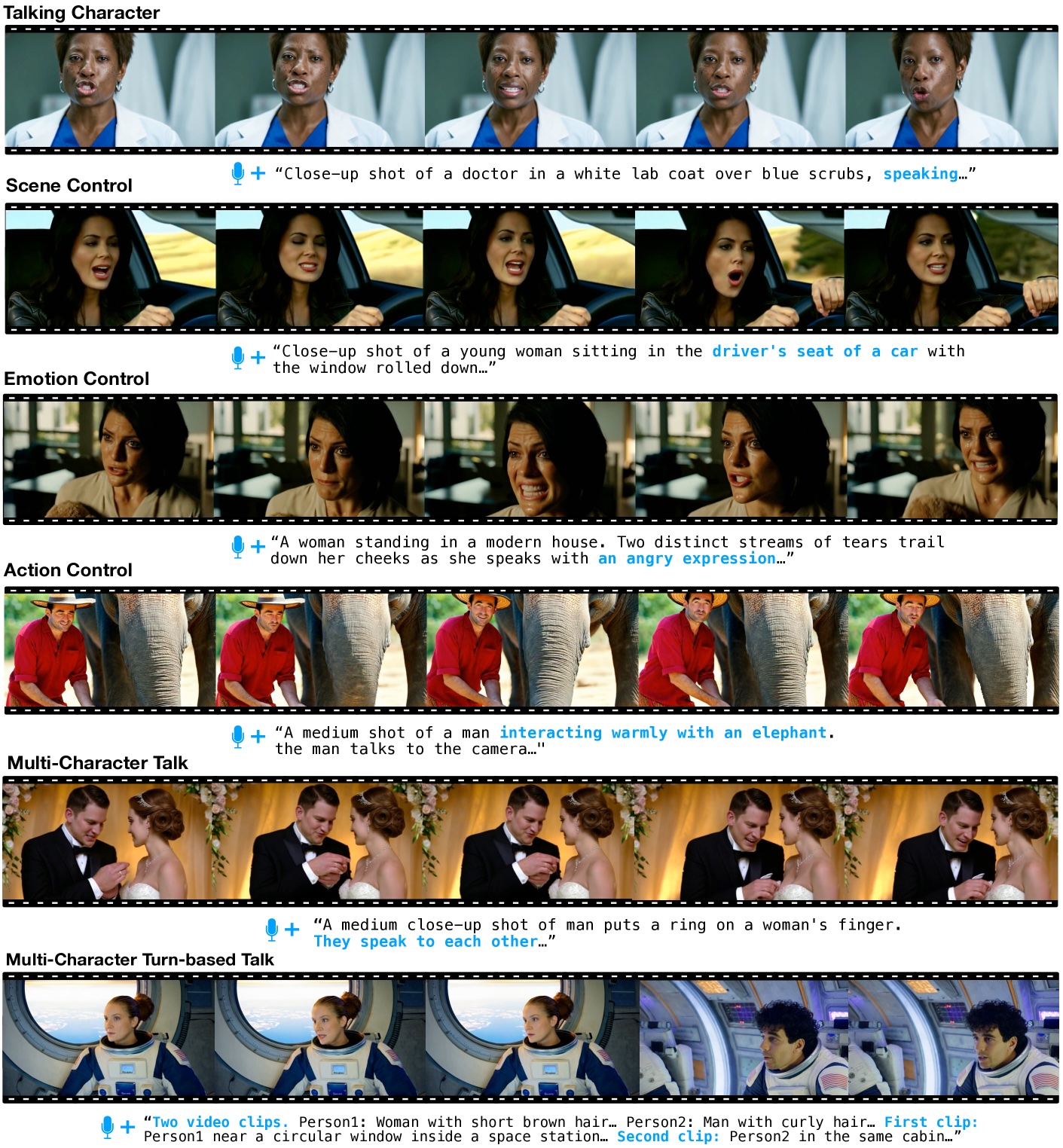
The researchers built the system using 300 hours of carefully filtered video content, though they haven't disclosed the source material. They supplemented this with text-based video sequences to expand the range of possible expressions and interactions.
Managing multiple characters
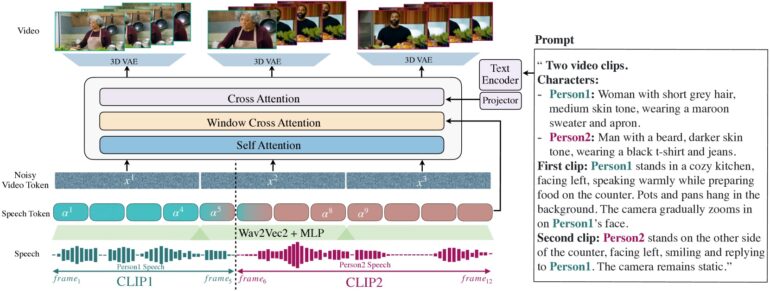
For scenes with multiple characters, the team developed a streamlined prompt system. Users can define characters once and refer to them with simple tags like 'Person1' or 'Person2' throughout different scenes, eliminating the need for repeated descriptions.
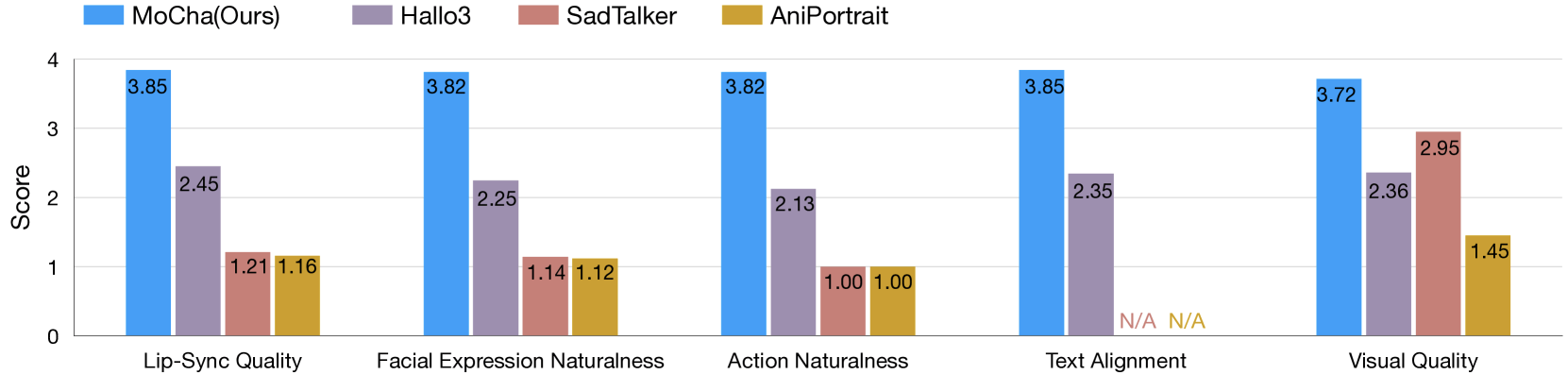
In tests across 150 different scenarios, MoCha outperformed similar systems in both lip synchronization and natural movement quality. Independent evaluators rated the generated videos as realistic.
According to the research team, MoCha shows promise for applications ranging from digital assistants and virtual avatars to advertising and educational content. Meta hasn't revealed whether the system will become open source or remain a research prototype.
The timing of MoCha's development is notable, as major social media companies race to advance AI-powered video technology. Meta recently launched MovieGen, while TikTok parent company ByteDance has been developing its own suite of AI animation systems - including INFP, OmniHuman-1, and Goku.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.