MetaClaw framework trains AI agents while you're in meetings by checking your Google Calendar

Key Points
- MetaClaw is a framework that enables AI agents to learn from their own mistakes during operation. When an agent fails at a task, a behavioral rule is automatically derived and injected into the prompt, while model weights are updated via reinforcement learning during idle phases.
- A background process monitors the user's Google calendar, keyboard activity, and sleeping times to schedule training windows without causing disruption.
- In testing, the framework nearly elevated a weaker language model to the performance level of a significantly stronger one.
Researchers from four US universities have built a framework that improves AI agents during operation. It checks the user's Google calendar to figure out when to train.
Most AI agents built on large language models get trained once and then shipped as-is. But user needs constantly shift, and the model never adapts.
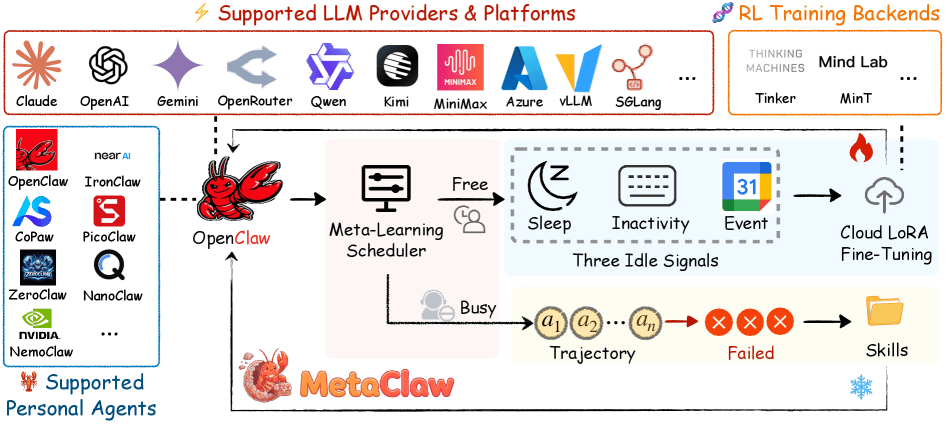
Researchers at UNC-Chapel Hill, Carnegie Mellon University, UC Santa Cruz, and UC Berkeley are tackling this with MetaClaw - a framework that continuously improves an AI agent by learning from its own mistakes, mostly without the user noticing or the service going down.
Failed tasks turn into new behavioral rules
The first mechanism kicks in whenever the agent fails a task. A separate language model analyzes the failed interaction and distills a compact behavioral rule from it. That rule gets injected straight into the agent's system prompt and immediately applies to all future tasks. The model itself stays untouched, and the service keeps running.
According to the paper, three main types of rules come out of this process: correctly normalizing time formats, creating backups before destructive file operations, and following naming conventions. Since these rules aren't tied to a single task, one mistake can drive improvements across completely different tasks later on.
Training happens when you're not looking
The second mechanism updates the model weights through reinforcement learning with cloud-based LoRA fine-tuning. Since this kind of update briefly interrupts the agent, it can't run while the user is actively working.
To handle this, the researchers built a background process called OMLS (Opportunistic Meta-Learning Scheduler) that watches three signals: configurable sleep times, keyboard, and mouse inactivity at the OS level, and Google calendar events. If the calendar shows the user is sitting in a meeting, a training window opens up. The trainer can pause and resume, so even short idle stretches get put to use.
The system draws a hard line between data collected before a rule change and data collected after. Only post-change data goes into training. Otherwise, the model would get penalized for mistakes the new behavioral rule already fixed.
The researchers say both mechanisms feed off each other: a better model produces more informative errors, which lead to better rules. Better rules then generate higher-quality training data for the next weight update.
Weaker model nearly closes the gap
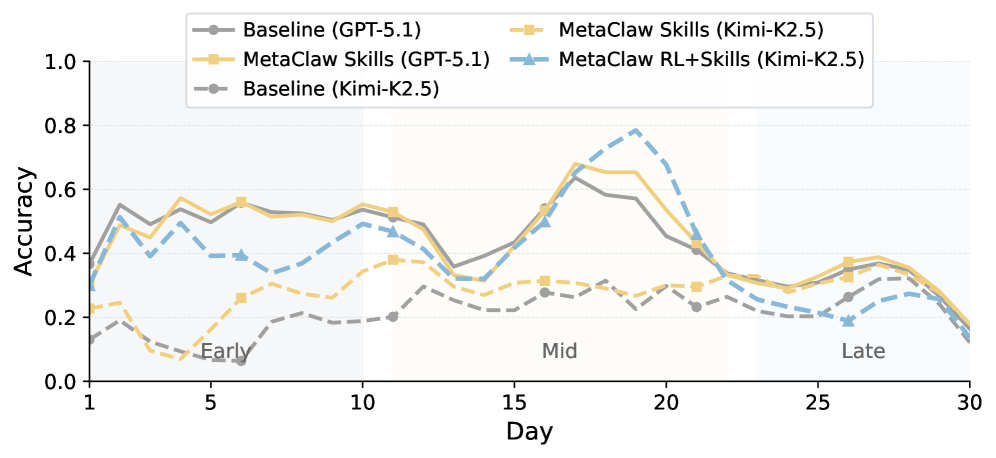
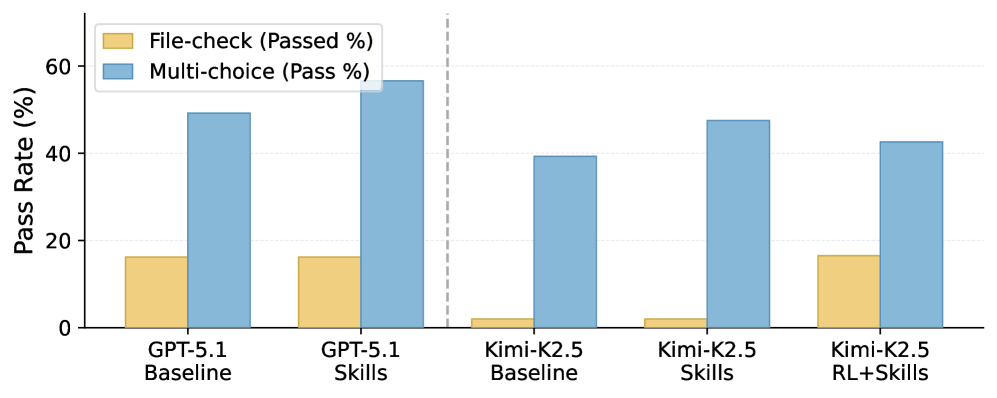
The researchers tested MetaClaw on a custom benchmark with 934 questions across 44 simulated workdays, running GPT-5.2 and Kimi-K2.5. The behavioral rules alone boost Kimi-K2.5's accuracy by up to 32 percent relative. The full framework pushes Kimi-K2.5 from 21.4 to 40.6 percent - nearly matching GPT-5.2's baseline of 41.1 percent. The rate of fully solved tasks jumps by a factor of 8.25.
The pattern holds across the board, according to the paper: weaker models benefit far more because they lack the procedural knowledge the rule library spells out. GPT-5.2 already starts at a higher level and has less room to grow.
To check whether MetaClaw works beyond CLI tasks, the researchers also plugged the framework into AutoResearchClaw. This pipeline autonomously runs through 23 step, from literature review to experiments to a finished paper. The behavioral rules alone, without any model training, cut the repetition rate of individual steps by 24.8 percent and the number of refinement cycles by 40 percent.
Simulated benchmark comes with caveats
The researchers acknowledge their benchmark is a simulation, not real user sessions. The raw numbers don't translate directly to production environments. On top of that, detecting idle time windows depends on how the user configures the system. The code is available on GitHub. MetaClaw doesn't need a local GPU and runs through a proxy architecture with cloud endpoints.
Recently, researchers at Princeton University introduced OpenClaw-RL, a related framework also designed to improve AI agents during operation. OpenClaw-RL uses follow-up signals from each interaction, like user responses or test results, as a live training source. MetaClaw builds on the OpenClaw infrastructure but takes a different approach: instead of feeding all interaction signals directly into training, it explicitly separates fast rule adaptation in the prompt from delayed weight optimization during idle windows.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now