Meta's new LLM architecture tackles fundamental flaw in how language models process text

Meta has developed a new AI architecture called Byte Latent Transformer (BLT) to solve a fundamental problem with today's language models: they can't reliably work with individual letters.
Current AI systems struggle with tasks as simple as counting how many times the letter "n" appears in "mayonnaise." This limitation comes from how these models process text—they split it into short strings of characters called tokens, which means they lose direct access to individual letters.
The token-based approach also makes it difficult to work with different types of data like images and sound. While companies continue using tokens because processing raw bytes requires intense computing power, Meta says it has found a way around this limitation.
A new approach using bytes
Instead of using tokens, BLT processes data directly at the byte level. To keep computing requirements under control, the system groups bytes into patches dynamically. When processing simple, predictable text, BLT combines bytes into larger patches. For complex text passages, it creates smaller patches and dedicates more computing power to process them.
BLT processes data through five distinct stages. In the first stage, a local model converts the bytes into encoded form and combines them into patches. These patches then move through a large transformer for processing, after which another local model converts them back into bytes. In the final stage, a smaller transformer analyzes the sequence to predict what byte should come next.
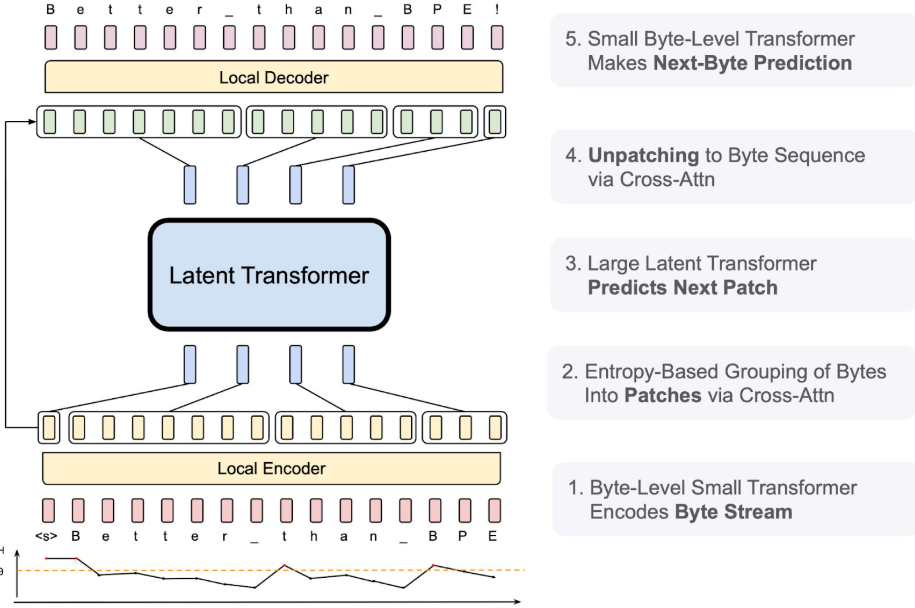
According to Meta, BLT performs better than larger models when tested on tasks that require understanding individual characters. Using just 8 billion parameters, the system outperforms Llama 3.1, despite Llama having trained on 16 times more data.
The new architecture also proves more efficient at scaling than current systems. Meta's research team discovered they could improve performance without increasing costs by expanding both patch and model sizes simultaneously. This method achieved up to 50 percent better efficiency during inference while maintaining similar performance.
More robust and flexible processing
According to Meta researchers, the system's greatest strength is its ability to handle unusual or corrupted text. BLT performs better when working with rare text patterns and maintains performance even when there is noise or other disturbances in the input.
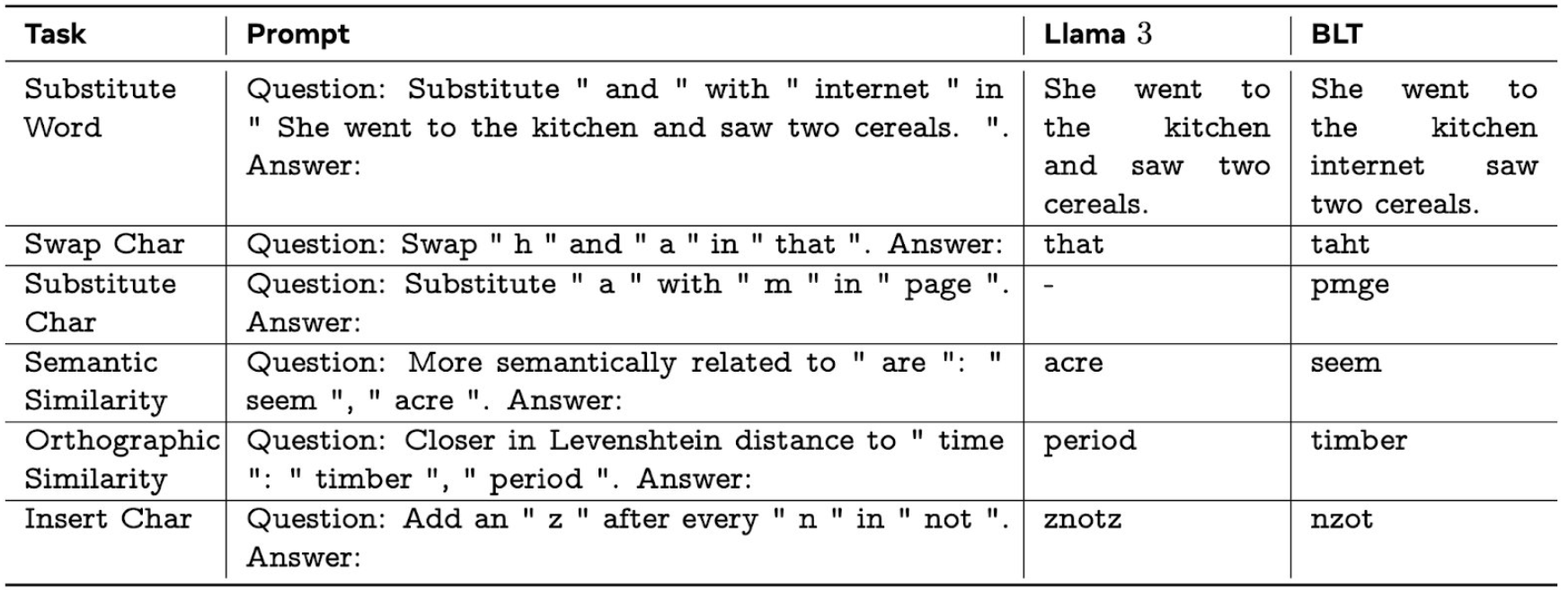
This isn't Meta's first effort to move past tokenizers. In May 2023, the company released MegaByte, a similar but less flexible approach. At that time, well-known AI developer Andrej Karpathy pointed to removing tokenizers as a key goal in advancing language models, though these methods haven't gained widespread adoption.
Meta has published both the code and research findings on GitHub. The company hopes this will speed up advances in processing less common languages, computer code, and making AI systems more accurate with facts.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.