Meta introduces MegaByte, a method that could take the performance and efficiency of transformer models to a new level.
Currently, all Transformer models use tokenizers. These algorithms convert words, images, audio, or other input into tokens that can then be processed by GPT-4 or other models as a series of numbers. For language models, short words are converted to one token, and longer words are converted to multiple tokens.
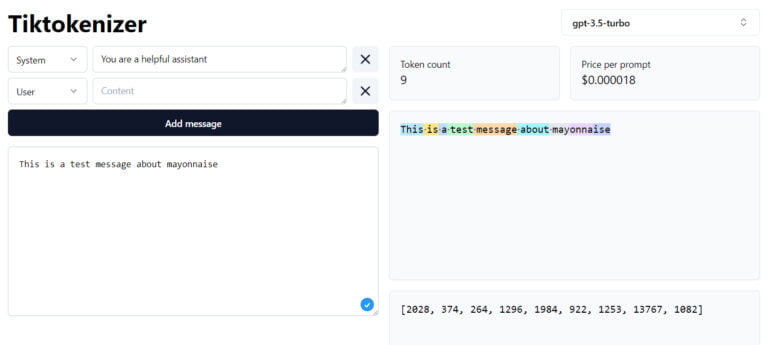
However, the use of such tokens has some drawbacks, for example, depending on the model architecture, their processing is computationally intensive, the integration of new modalities is difficult, and they usually do not work at the level of letters. This repeatedly leads to subtle capability gaps in language models, such as the inability to count the number of "n"s in the word "mayonnaise".
I saw this on Facebook, and I'm confused why this is a hard task. Facebook post has ChatGPT failing at this too pic.twitter.com/YHW9yHXA5X
— Talia Ringer (@TaliaRinger) May 19, 2023
These and other factors also make it difficult to handle larger inputs such as entire books, videos, or podcasts, although there are now models with GPT-4 or Claude that can handle between 32,000 and 100,000 tokens.
Metas MegaByte operates at the byte level
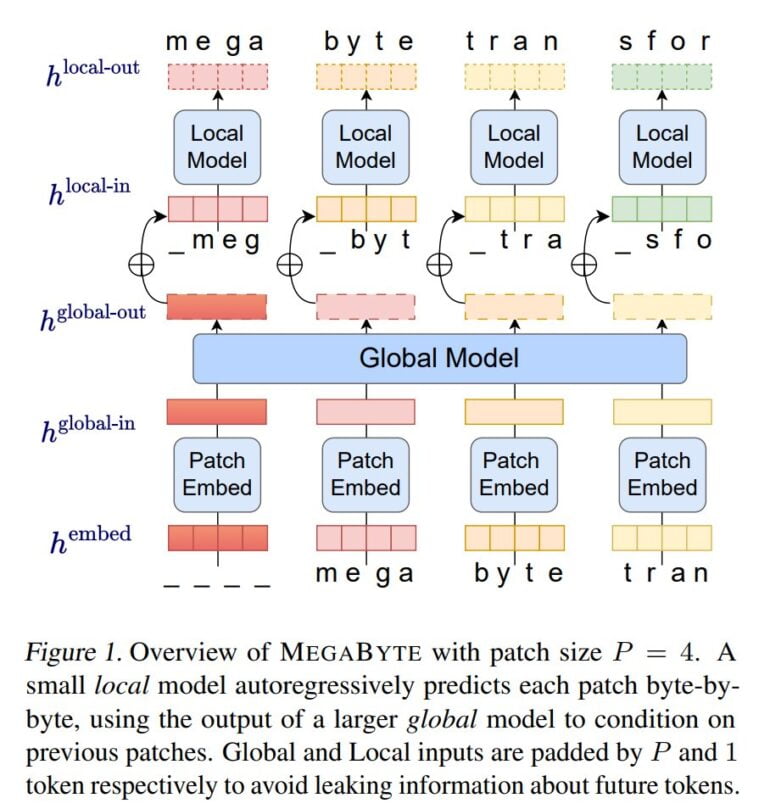
With MegaByte, the researchers at Meta AI now demonstrate a method that dispenses with classical tokenizers and instead processes text, images, and audio at the byte level. MegaByte first breaks down sequences of text or other modalities into individual patches, similar to a tokenizer.
Then, a patch embedder encodes a patch by losslessly concatenating embeddings of each byte, such as a letter. A global module, a large autoregressive transformer, takes as inputs and outputs those patch representations and passes them on.
Each section is then processed by a local autoregressive transformer model that predicts the bytes within a patch.
According to Meta, the architecture enables a higher degree of computational parallelism, larger and more powerful models for the same computational cost, and a significant reduction in the cost of the transformers' self-attention mechanism.
The team compares MegaByte to other models, such as a simple decoder-transformer architecture or Deepmind's PerceiverAR, in tests for text, images, and audio, and shows that MegaByte is more efficient and can handle sequences of nearly a million bytes.

OpenAI's Andrej Karpathy call Meta's MegaByte "promising"
OpenAI's Andrej Karpathy called Meta's MegaByte promising work. "Everyone should hope we can throw away tokenization in LLMs," Karpathy wrote on Twitter.
Promising. Everyone should hope that we can throw away tokenization in LLMs. Doing so naively creates (byte-level) sequences that are too long, so the devil is in the details.
Tokenization means that LLMs are not actually fully end-to-end. There is a whole separate stage with… https://t.co/t240ZPxPm7
— Andrej Karpathy (@karpathy) May 15, 2023
The Meta AI team also sees their own results as an indication that MegaByte may have the potential to replace classic tokenizers in Transformer models.
MEGABYTE outperforms existing byte-level models across a range of tasks and modalities, allowing large models of sequences of over 1 million tokens. It also gives competitive language modeling results with subword models, which may allow byte-level models to replace tokenization.
Meta
Since the models on which the experiments were performed are well below the size of current language models, Meta plans to scale up to much larger models and datasets as a next step.



