
As part of the Massively Multilingual Speech project, Meta is releasing AI models that can convert spoken language to text and text to speech in 1,100 languages.
The new set of models is based on Meta's wav2vec, as well as a curated dataset of examples for 1,100 languages and another uncurated dataset for nearly 4,000 languages, including languages spoken by only a few hundred people for which no speech technology yet exists, according to Meta.
The model can express itself in more than 1,000 languages and identify more than 4,000 languages. According to Meta, MMS outperforms previous models by covering ten times more languages. You can get an overview of all available languages here.
New Testament gets new use as AI dataset
A key component of MMS is the Bible, specifically the New Testament. The Meta dataset contains New Testament readings in more than 1,107 languages with an average length of 32 hours.
Meta used these recordings in combination with matching passages from the Internet. In addition, another 3,809 unlabeled audio files were used, also New Testament readings, but without additional language information.
Since 32 hours per language is not enough training material for a reliable speech recognition system, Meta used wave2vec 2.0 to pre-train MMS models with more than 500,000 hours of speech in more than 1,400 languages. These models were then fine-tuned to understand or identify numerous languages.
Benchmarks show that the model's performance remained nearly constant despite training with many more different languages. In fact, the error rate decreased minimally by 0.4 percentage points with increasing training.
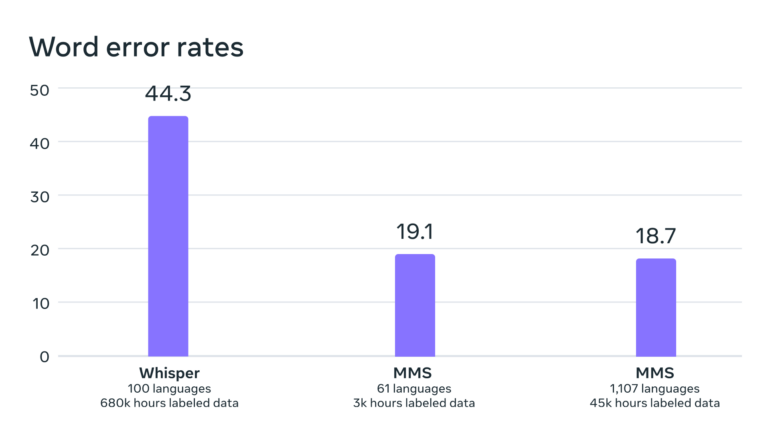
According to Meta, it is also significantly lower than that of OpenAI's Whisper, which was not explicitly optimized for extensive multilingualism. A comparison in English only would be more interesting. First testers on Twitter report that Whisper performs better here.
In my testing, it performs worse than Whisper for transcription to text, mis-hearing words and not hearing implied punctuation. Also it's about 10x slower than Faster-Whisper. Fairseq uses 20 GB of RAM, while Whisper uses about 1 GB. For these reasons and others this is…
— catid (e/acc) (@MrCatid) May 23, 2023
The fact that the voices in the dataset are predominantly male does not negatively affect the understanding or generation of female voices, according to Meta.

In addition, the model does not tend to generate overly religious speech. Meta attributes this to the classification approach used (Connectionist Temporal Classification), which focuses more on speech patterns and sequences than on word content and meaning.
Meta cautions, however, that the model sometimes transcribes words or phrases incorrectly, which can lead to incorrect or offensive statements.
One model for thousands of languages
Meta's long-term goal is to develop a single language model for as many languages as possible in order to preserve endangered languages. Future models may support even more languages and even dialects.
"Our goal is to make it easier for people to access information and to use devices in their preferred language," Meta writes. Specific application scenarios include VR and AR technologies or messaging.
In the future, a single model could be trained for all tasks, such as speech recognition, speech synthesis, and speech identification, leading to even better overall performance, Meta writes.
The code, the pre-trained MMS models with 300 million and one billion parameters, respectively, and the refined derivations for speech recognition and identification and text-to-speech are made available by Meta as open-source Models on Github.




