Meta's SAM 3 segmentation model blurs the boundary between language and vision
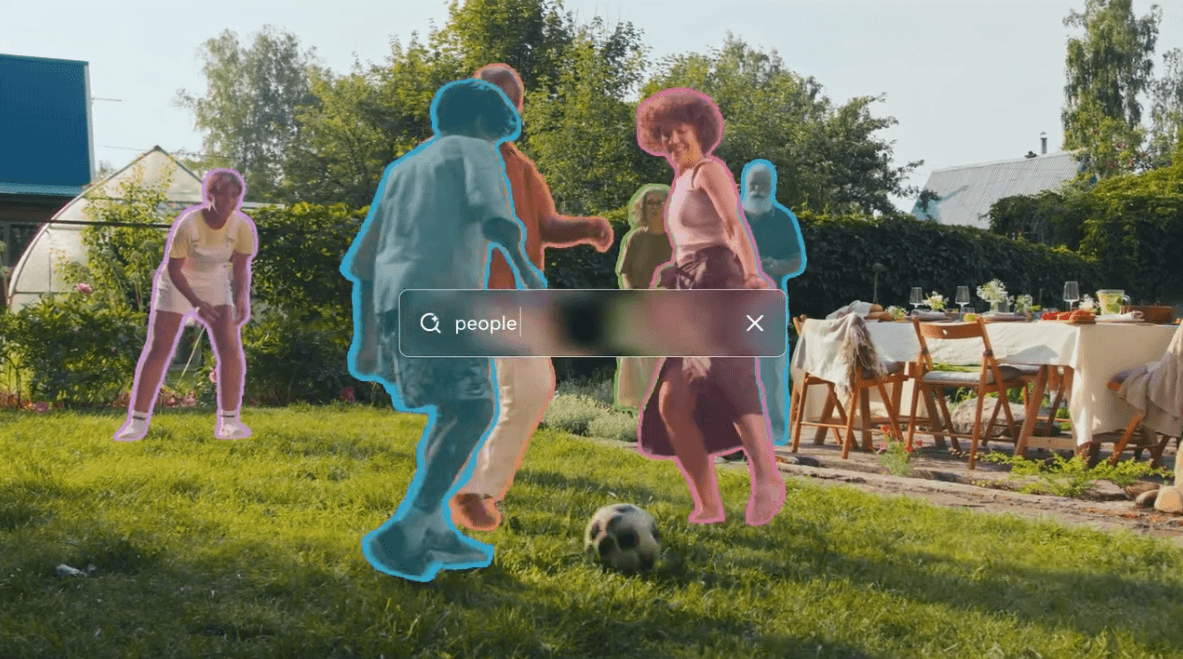
Meta releases the third generation of its "Segment Anything Model." Unlike standard models limited to fixed categories, SAM 3 uses an open vocabulary to understand both images and videos. The system relies on a new training method combining human and AI annotators.
Users can use text prompts, example images ("exemplar prompts"), or visual prompts to isolate specific concepts in both images and videos. Alongside the model weights and code, Meta has launched the Segment Anything Playground, a web interface where users can test the model.
Bridging the gap between language and vision
According to Meta, connecting language with visual elements remains a major hurdle in computer vision. Standard models recognize basic objects like "person" but struggle with nuanced descriptions like "the striped red umbrella" because they rely on predefined categories.
SAM 3 addresses this with "Promptable Concept Segmentation." The model takes short noun phrases or reference images to find every instance of a concept within a piece of media. It still supports the visual prompts from SAM 1 and SAM 2, such as masks, bounding boxes, or dots.

In internal benchmarks, specifically the new "Segment Anything with Concepts" (SA-Co) test, SAM 3 reportedly doubles the performance of existing systems. Meta claims the model outperforms specialized tools like GLEE and OWLv2, as well as large multimodal models like Gemini 2.5 Pro.

A hybrid approach speeds up training
Meta built a hybrid "data engine" for training—a pipeline where AI models, including SAM 3 and Llama-based captioning, generate initial segmentation masks. Human and AI annotators then verify and correct these suggestions.
According to the research paper, this process significantly speeds up annotation. AI assistance is roughly five times faster than manual effort for negative prompts (object not present) and 36 percent more efficient for positive ones. This resulted in a training dataset containing over four million unique concepts.

Meta is already integrating the technology into its products. On Facebook Marketplace, SAM 3 powers the "View in Room" feature, letting users virtually place furniture in their homes. In Instagram’s ‘Edits’ app, SAM 3 will soon enable effects that creators can apply to specific people or objects.
Running on an Nvidia H200 GPU, SAM 3 processes an image with over 100 recognized objects in 30 milliseconds. For video, latency scales with object count but allows near real-time processing for about five simultaneous objects.
Meta notes several limitations. SAM 3 struggles with highly specific technical terms outside its training data ("zero-shot"), such as those in medical imaging. The model also fails with complex logical descriptions like "the second to last book from the right on the top shelf." To address this, Meta suggests pairing SAM 3 with multimodal language models such as Llama or Gemini, a combination it calls the "SAM 3 Agent."
Reconstructing 3D worlds from 2D images
Alongside SAM 3, Meta released SAM 3D, a suite of two models designed to generate 3D reconstructions from single 2D images.
SAM 3D Objects focuses on reconstructing objects and scenes. Since 3D training data is scarce compared to 2D images, Meta applied its "data engine" principle here as well. Annotators rate multiple AI-generated mesh options, while the hardest examples are routed to expert 3D artists. This method allowed Meta to annotate nearly one million images with 3D information, creating a system that turns photos into manipulable 3D objects.
The second model, SAM 3D Body, specializes in capturing human poses and shapes. It uses the new "Meta Momentum Human Rig" (MHR) format, which separates skeletal structure from soft tissue shape. Trained on approximately eight million images, the model works robustly even with occlusions or unusual postures.
Meta says the technology is still in its early stages. The resolution of generated 3D objects remains limited, leading to detail loss in complex structures. Additionally, SAM 3D Objects treats items in isolation and cannot yet correctly simulate physical interactions between multiple objects. Meta also notes that SAM 3D Body has not yet reached the precision of specialized hand-tracking tools.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.