Microsoft expands its SLM lineup with new multimodal and mini Phi-4 models

Microsoft has added two new models to its Phi small language model family: Phi-4-multimodal, which can handle audio, images and text simultaneously, and Phi-4-mini, a streamlined model focused on text processing.
Phi-4-multimodal introduces what Microsoft calls a "mixture-of-LoRAs" approach. This allows it to process text, audio, and visual input in a single representation space, eliminating the need for complex pipelines or separate models for different types of data.
The model has taken the top spot in the Huggingface OpenASR Leaderboard for automatic speech recognition with a word error rate of only 6.14 percent. This puts it ahead of specialized models such as WhisperV3 and SeamlessM4T-v2-Large. According to Microsoft, the model also excels in speech translation and summarization.
Despite its relatively compact size, Phi-4-multimodal also shows good performance on vision-related tasks, especially when it comes to mathematical and scientific reasoning, Microsoft says. The company reports that it rivals larger models such as Gemini-2-Flash-lite-preview and Claude-3.5-Sonnet in document and graph comprehension, optical character recognition, and visual scientific reasoning.

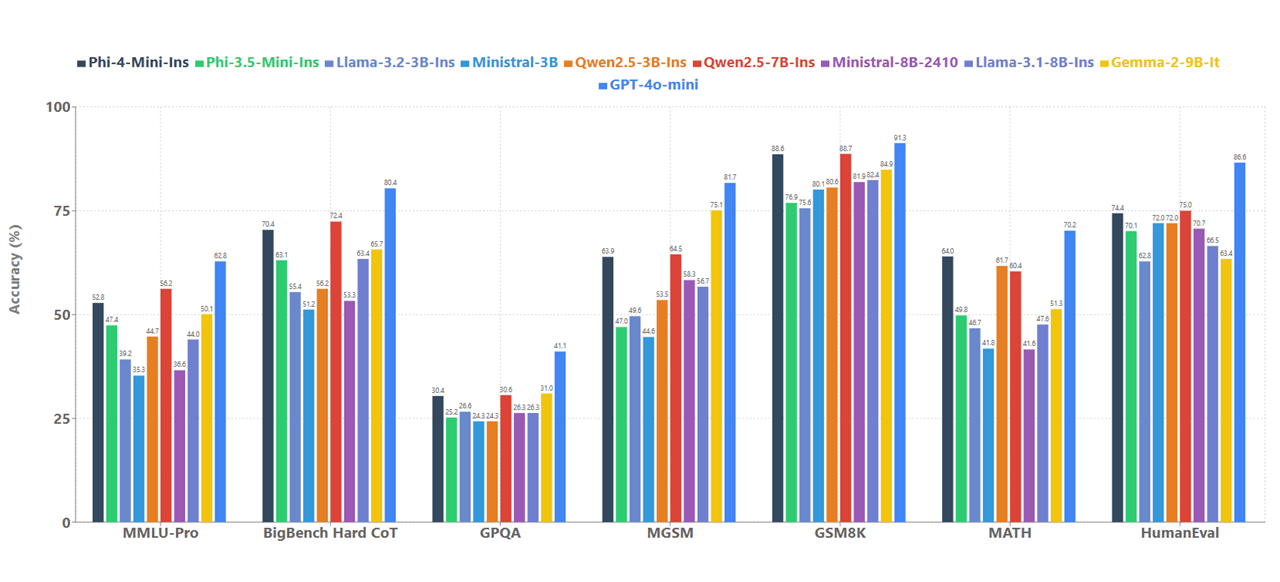
Phi-4-mini: Focused on efficiency
The new Phi-4-mini comes in at 3.8 billion parameters and is built as a dense decoder-only transformer with a 128K context window. Microsoft has optimized it specifically for speed and efficiency.
One of Phi-4-mini's standout features is its function calling capability, which allows it to automatically use tools. The model can analyze queries, call relevant functions with appropriate parameters, receive results, and incorporate them into its responses using a standardized protocol. This makes it well suited for agent-based systems that need to connect to external tools, APIs, and data sources, Microsoft says.
Real-world applications
Microsoft sees multiple applications for both models. Phi-4-multimodal could be integrated into smartphones to handle voice commands and image analysis, while also helping to improve driver assistance systems in cars. For Phi-4-mini, Microsoft sees particular value in financial services applications. It could support tasks such as calculations, report generation, and translation of financial documents.
Both models are available via Azure AI Foundry, Hugging Face and the NVIDIA API Catalog. These new additions join the Phi-4-14B language model, which Microsoft introduced in December 2024 and released with weights in January.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.