Microsoft's multimodal CoDi processes and generates text, images, video, and audio
Microsoft researchers present CoDi, a composable, diffusion-based AI model that can simultaneously process and generate content across multiple modalities, including text, images, video, and audio.
Composable Diffusion (CoDi) is presented by Microsoft's i-Code project, which aims to develop integrative and composable multimodal AI. It's a multimodal AI model that can simultaneously process and generate content across multiple modalities, including text, images, video, and audio. This model differs from traditional generative AI systems, which are limited to specific input modalities.
Because training data sets are scarce for most of today's modality combinations, the researchers used an alignment strategy that matches modalities in both input and output space. As a result, CoDi is free to condition on any combination of inputs and generate any set of modalities, even those not present in the training data.
Challenges in cross-modal AI development
Addressing the limitations of traditional single-modality AI models, CoDi provides a solution to the often cumbersome and slow process of combining modality-specific generative models.
This novel model employs a unique composable generation strategy that bridges alignment in the diffusion process and facilitates synchronized generation of intertwined modalities, such as temporally aligned video and audio.
Video: Microsoft
CoDi's training process is also distinctive. It involves projecting input modalities such as images, video, audio, and language into a common semantic space. This allows for flexible processing of multimodal inputs, and with a cross-attention module and an environment encoder, it is capable of generating any combination of output modalities simultaneously.
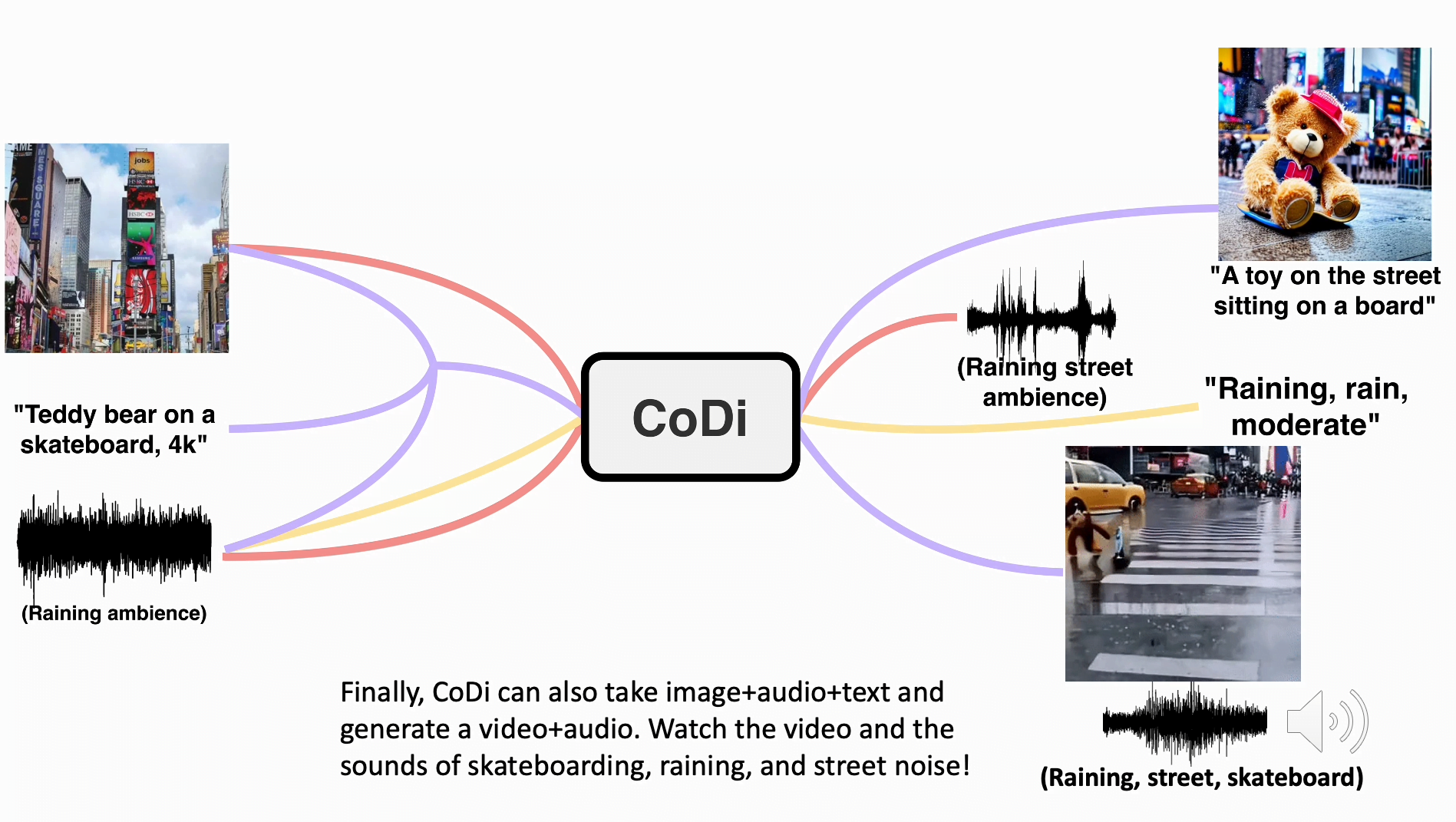
"teddy bear on a skateboard, 4k, high resolution"
The researchers provide examples of CoDi's capabilities, demonstrating its ability to generate synchronized video and audio from separate text, audio, and image prompts. In one example, the inputs included the text prompt "teddy bear on skateboard, 4k, high resolution", an image of Times Square, and the sound of rain.
CoDi generated a short, albeit low-quality video of a teddy bear skateboarding in the rain at Times Square, accompanied by the synchronized sounds of rain and street noise.
The potential applications of CoDi are numerous. The researchers highlight its possible uses in industries such as education and accessibility for people with disabilities.
Our work marks a significant step towards more engaging and holistic human-computer interactions, establishing a solid foundation for future investigations in generative artificial intelligence.
From the paper
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.